
Искусственный интеллект
Первая годовщина ChatGPT: меняя будущее взаимодействия с искусственным интеллектом

Оглядываясь на первый год работы ChatGPT, становится ясно, что этот инструмент значительно изменил мир искусственного интеллекта. Запущенный в конце 2022 года, ChatGPT выделялся своим удобным для пользователя диалоговым стилем, благодаря которому взаимодействие с ИИ было больше похоже на общение с человеком, чем с машиной. Этот новый подход быстро привлёк внимание общественности. Всего через пять дней после запуска ChatGPT привлёк миллион пользователей. К началу 2023 года это число выросло до примерно 100 миллионов пользователей в месяц, а к октябрю платформа привлекла около 1.7 миллиарда посещений по всему миру. Эти цифры красноречиво свидетельствуют о её популярности и полезности.
За последний год пользователи нашли множество креативных способов использования ChatGPT: от простых задач, таких как написание электронных писем и обновление резюме, до запуска успешного бизнеса. Но дело не только в том, как люди используют ChatGPT; сама технология развивалась и совершенствовалась. Изначально ChatGPT был бесплатным сервисом, предлагающим подробные текстовые ответы. Теперь есть ChatGPT Plus, включающий ChatGPT-4. Эта обновлённая версия обучена на большем объёме данных, даёт меньше неправильных ответов и лучше понимает сложные инструкции.
Одно из самых важных обновлений заключается в том, что ChatGPT теперь может взаимодействовать несколькими способами: он может слушать, говорить и даже обрабатывать изображения. Это означает, что вы можете общаться с ним через его мобильное приложение и показывать ему изображения, чтобы получить ответы. Эти изменения открыли новые возможности для искусственного интеллекта и изменили то, как люди видят и понимают его роль в нашей жизни.
От начала работы с демонстрационной технической программой до нынешнего статуса крупного игрока в мире технологий, ChatGPT прошёл впечатляющий путь. Изначально он рассматривался как способ тестирования и совершенствования технологий, получая обратную связь от общественности. Но быстро стал неотъемлемой частью сферы искусственного интеллекта. Этот успех демонстрирует эффективность тонкой настройки больших языковых моделей (LLM) как с помощью контролируемого обучения, так и с использованием обратной связи от людей. Благодаря этому ChatGPT способен решать широкий спектр вопросов и задач.
Гонка за разработку наиболее эффективных и универсальных систем искусственного интеллекта привела к распространению как открытых, так и проприетарных моделей, таких как ChatGPT. Понимание их общих возможностей требует комплексных тестов для широкого спектра задач. В этом разделе рассматриваются эти тесты, проливающие свет на то, как разные модели, включая ChatGPT, соотносятся друг с другом.
Оценка программ LLM: критерии
- МТ-Скамья: В этом тесте проверяются навыки многоходовой беседы и выполнения инструкций в восьми областях: письмо, ролевая игра, извлечение информации, рассуждение, математика, программирование, знания STEM и гуманитарные/социальные науки. В качестве оценщиков используются более сильные LLM, такие как GPT-4.
- АльпакаЭвал: основанный на наборе оценок AlpacaFarm, этот автоматический оценщик на основе LLM сравнивает модели с ответами продвинутых LLM, таких как GPT-4 и Claude, рассчитывая процент побед моделей-кандидатов.
- Открыть таблицу лидеров LLM: с помощью системы оценки языковой модели эта таблица лидеров оценивает студентов LLM по семи ключевым критериям, включая задачи на рассуждение и тесты на общие знания, как в условиях нулевого, так и малого количества попыток.
- БОЛЬШАЯ скамья: этот совместный тест охватывает более 200 новых языковых задач, охватывающих широкий спектр тем и языков. Его цель — изучить LLM и спрогнозировать их будущие возможности.
- ЧатЭвал: мультиагентная структура дебатов, которая позволяет командам автономно обсуждать и оценивать качество ответов различных моделей на открытые вопросы и традиционные задачи генерации естественного языка.
Сравнительная производительность
Что касается общих показателей, программы LLM с открытым исходным кодом продемонстрировали значительный прогресс. Лама-2-70Б, например, достиг впечатляющих результатов, особенно после точной настройки с помощью данных инструкций. Его вариант, Llama-2-chat-70B, преуспел в AlpacaEval с процентом побед 92.66%, превзойдя GPT-3.5-turbo. Тем не менее, GPT-4 остается лидером с процентом побед 95.28%.
Зефир-7Б, меньшая модель, продемонстрировала возможности, сравнимые с более крупными LLM 70B, особенно в AlpacaEval и MT-Bench. Между тем, WizardLM-70B, настроенный для работы с разнообразными командными данными, набрал самый высокий балл среди LLM с открытым исходным кодом на MT-Bench. Однако он все равно отставал от ГПТ-3.5-турбо и ГПТ-4.
Интересная работа, GodziLLa2-70B, получила конкурентную оценку в таблице лидеров Open LLM, демонстрируя потенциал экспериментальных моделей, объединяющих различные наборы данных. Аналогичным образом, Yi-34B, разработанный с нуля, выделился с оценками, сравнимыми с GPT-3.5-турбо, и лишь немного отстал от GPT-4.
UltraLlama с ее тонкой настройкой на разнообразные и высококачественные данные соответствовала GPT-3.5-turbo в предлагаемых тестах и даже превзошла его в областях мировых и профессиональных знаний.
Расширение масштабов: появление гигантских программ LLM
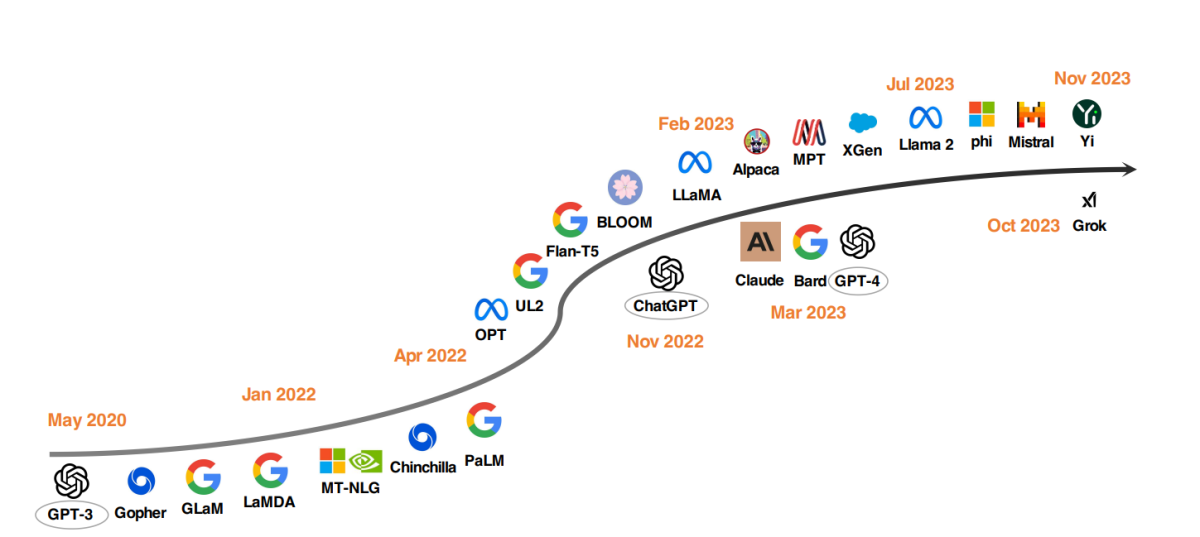
Лучшие модели LLM с 2020 года
Заметной тенденцией в разработке LLM стало масштабирование параметров моделей. Такие модели, как Gopher, GLaM, LaMDA, MT-NLG и PaLM, раздвинули границы, достигнув кульминации в моделях с числом параметров до 540 миллиардов. Эти модели продемонстрировали исключительные возможности, но их закрытый исходный код ограничивал их более широкое применение. Это ограничение стимулировало интерес к разработке LLM с открытым исходным кодом, и эта тенденция набирает обороты.
Параллельно с масштабированием моделей исследователи изучали альтернативные стратегии. Вместо того чтобы просто увеличивать размеры моделей, они сосредоточились на улучшении предобучения моделей меньшего размера. В качестве примеров можно привести Chinchilla и UL2, которые показали, что больше не всегда значит лучше; более продуманные стратегии также могут давать эффективные результаты. Кроме того, значительное внимание уделяется настройке инструкций языковых моделей, и такие проекты, как FLAN, T0 и Flan-T5, внесли значительный вклад в эту область.
Катализатор ChatGPT
Внедрение OpenAI ChatGPT Это стало поворотным моментом в исследованиях обработки естественного языка (NLP). Чтобы конкурировать с OpenAI, такие компании, как Google и Anthropic, запустили собственные модели, Bard и Claude соответственно. Хотя эти модели демонстрируют сопоставимую с ChatGPT производительность во многих задачах, они всё ещё отстают от последней модели OpenAI, GPT-4. Успех этих моделей в первую очередь обусловлен обучением с подкреплением на основе обратной связи с человеком (RLHF) — методом, который всё больше исследуется для дальнейшего совершенствования.
Слухи и домыслы вокруг Q* (Q-Star) от OpenAI
Последние отчеты предполагают, что исследователи из OpenAI, возможно, достигли значительного прогресса в области ИИ благодаря разработке новой модели под названием Q* (произносится как Q-звезда). Предположительно, Q* обладает способностью решать математические задачи на уровне начальной школы — подвиг, который вызвал дискуссии среди экспертов о его потенциале как вехи на пути к искусственному общему интеллекту (AGI). Хотя OpenAI не прокомментировала эти сообщения, слухи о способностях Q* вызвали значительный ажиотаж и спекуляции в социальных сетях и среди энтузиастов искусственного интеллекта.
Разработка Q* примечательна тем, что существующие языковые модели, такие как ChatGPT и GPT-4, хотя и способны решать некоторые математические задачи, не особенно подходят для их надежного решения. Проблема заключается в том, что модели ИИ должны не только распознавать закономерности, как это происходит в настоящее время посредством глубокого обучения и преобразователей, но также рассуждать и понимать абстрактные концепции. Математика, будучи эталоном рассуждения, требует от ИИ планирования и выполнения нескольких шагов, демонстрируя глубокое понимание абстрактных концепций. Эта способность ознаменует значительный скачок в возможностях ИИ, потенциально выходя за рамки математики и позволяя решать другие сложные задачи.
Однако эксперты предостерегают от чрезмерного преувеличения этой разработки. Хотя система ИИ, надёжно решающая математические задачи, была бы впечатляющим достижением, это не обязательно означает появление сверхразумного ИИ или ИИ с полным интеллектом. Современные исследования в области ИИ, включая работы OpenAI, сосредоточены на элементарных задачах, с разной степенью успеха в решении более сложных задач.
Потенциальные сферы применения таких достижений, как Q*, обширны: от персонализированного обучения до помощи в научных исследованиях и проектировании. Однако важно также учитывать ожидания и учитывать ограничения и проблемы безопасности, связанные с такими достижениями. Опасения по поводу экзистенциальных рисков, связанных с ИИ, – основополагающая проблема OpenAI – остаются актуальными, особенно по мере того, как системы ИИ начинают всё больше взаимодействовать с реальным миром.
Движение LLM с открытым исходным кодом
Чтобы стимулировать исследования LLM с открытым исходным кодом, Meta выпустила модели серии Llama, вызвав волну новых разработок на основе Llama. Сюда входят модели, точно настроенные с помощью данных инструкций, такие как Alpaca, Vicuna, Lima и WizardLM. Исследования также направлены на расширение возможностей агентов, логическое рассуждение и долгоконтекстное моделирование в рамках структуры на основе Llama.
Кроме того, растет тенденция к разработке мощных программ LLM с нуля, в рамках таких проектов, как MPT, Falcon, XGen, Phi, Baichuan, Мистраль, Grokи Йи. Эти усилия отражают стремление демократизировать возможности программ LLM с закрытым исходным кодом, делая передовые инструменты искусственного интеллекта более доступными и эффективными.
Влияние ChatGPT и моделей с открытым исходным кодом в здравоохранении
Мы смотрим в будущее, где магистры права (LLM) будут помогать вести клинические записи, заполнять формы для возмещения расходов и помогать врачам в диагностике и планировании лечения. Это привлекло внимание как технологических гигантов, так и учреждений здравоохранения.
от Microsoft обсуждения с Epic, ведущий поставщик программного обеспечения для электронных медицинских карт, знаменует собой интеграцию программ магистратуры права в здравоохранение. Подобные инициативы уже реализуются в Калифорнийском университете в Сан-Диего и Медицинском центре Стэнфордского университета. Аналогичным образом, Google партнерские отношения с клиникой Мэйо и Amazon Web ServicesЗапуск HealthScribe, службы клинической документации с использованием искусственного интеллекта, знаменует собой значительный прогресс в этом направлении.
Однако такое быстрое развертывание вызывает опасения по поводу передачи контроля над медициной в пользу корпоративных интересов. Запатентованный характер этих программ LLM затрудняет их оценку. Их возможная модификация или прекращение по соображениям рентабельности может поставить под угрозу уход за пациентами, конфиденциальность и безопасность.
Острая необходимость заключается в открытом и инклюзивном подходе к развитию LLM в здравоохранении. Медицинские учреждения, исследователи, врачи и пациенты должны сотрудничать во всем мире для создания программ LLM с открытым исходным кодом для здравоохранения. Этот подход, аналогичный Консорциуму триллионов параметров, позволит объединить вычислительные, финансовые ресурсы и опыт.











