
Artificial Intelligence
Обучение моделей компьютерного зрения на случайном шуме вместо реальных изображений

Исследователи из Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (CSAIL) экспериментировали с использованием изображений случайного шума в наборах данных компьютерного зрения для обучения моделей компьютерного зрения и обнаружили, что вместо создания мусора этот метод на удивление эффективен:

Генеративные модели из эксперимента, отсортированные по производительности. Источник: https://openreview.net/pdf?id=RQUl8gZnN7O
Добавление кажущегося «визуального мусора» в популярные архитектуры компьютерного зрения не должно приводить к такой производительности. В крайнем правом изображении выше черные столбцы представляют показатели точности (на Имиджнет-100) для четырех «реальных» наборов данных. Хотя предшествующие ему наборы данных «случайного шума» (изображенные разными цветами, см. указатель вверху слева) не могут соответствовать этому, почти все они находятся в приемлемых верхних и нижних границах (красные пунктирные линии) для точности.
В этом смысле «точность» не означает, что результат обязательно выглядит как противоречить, чтобы церковь, чтобы пицца, или любой другой конкретный домен, для которого вы можете заинтересоваться созданием синтез изображений система, такая как генеративно-состязательная сеть или структура кодировщика/декодера.
Скорее, это означает, что модели CSAIL извлекли широко применимые центральные «истины» из данных изображений, настолько явно неструктурированных, что они не должны быть в состоянии предоставить их.
Разнообразие против. Натурализм
Эти результаты также нельзя отнести к переоснащение: живой обсуждение между авторами и рецензентами в Open Review показывает, что смешивание различного контента из визуально различных наборов данных (таких как «мертвые листы», «фракталы» и «процедурный шум» — см. Изображение ниже) в обучающий набор данных на самом деле улучшается точность в этих экспериментах.
Это предполагает (и это немного революционное понятие) новый тип «недоподгонки», где «разнообразие» преобладает над «натурализмом».
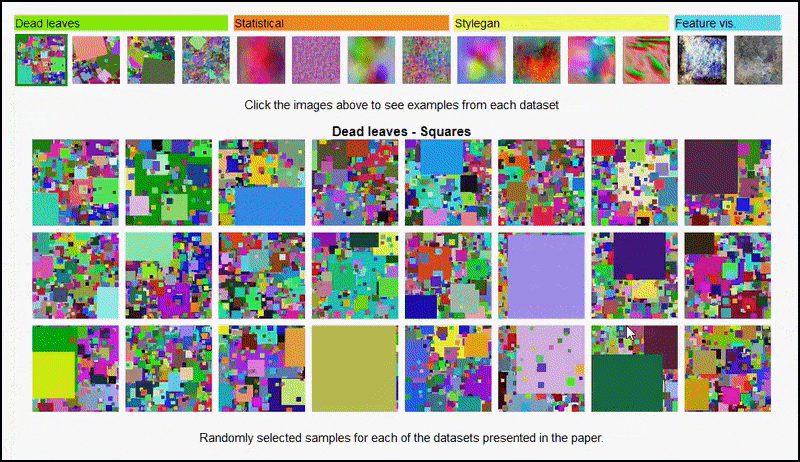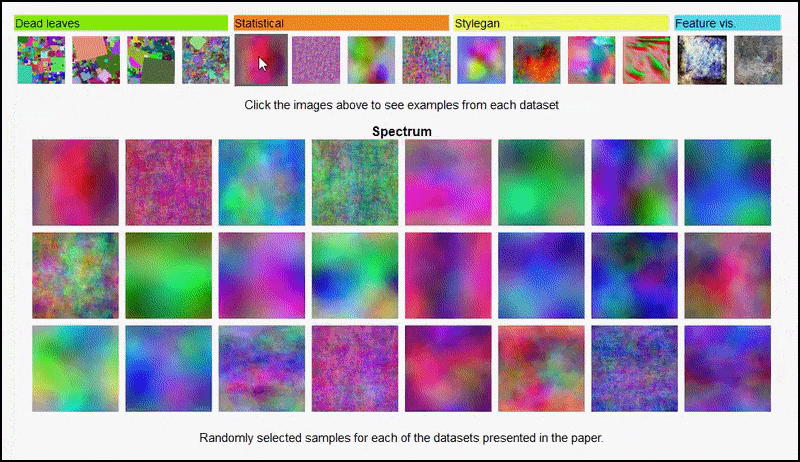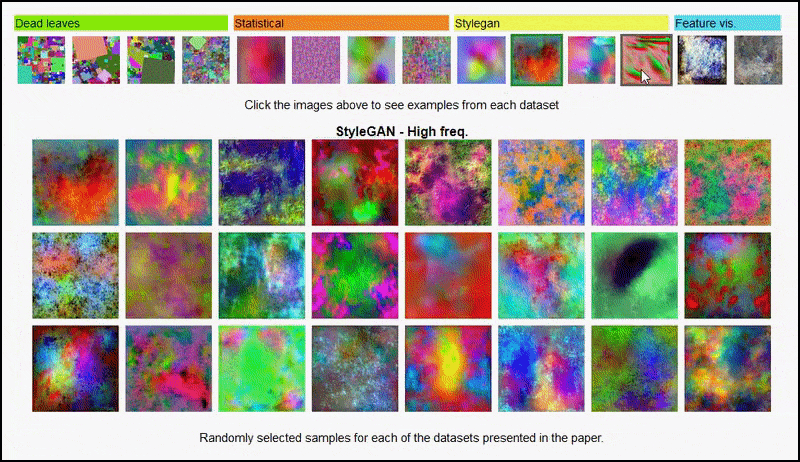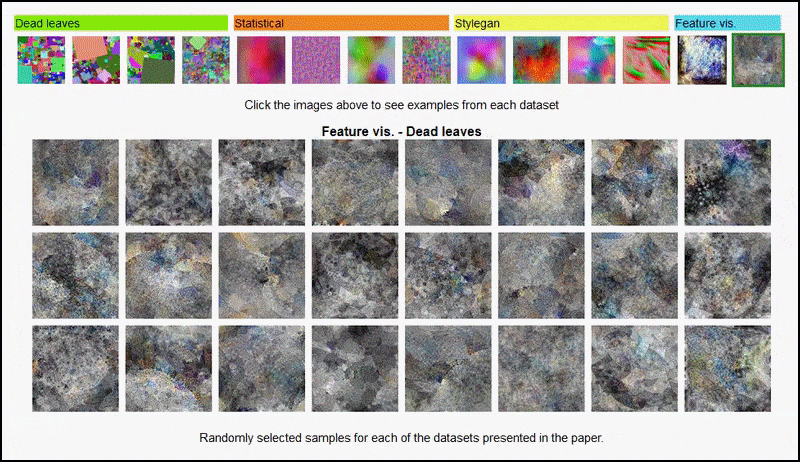
Ассоциация Проект страницу for the Initiative позволяет в интерактивном режиме просматривать различные типы наборов данных случайных изображений, используемых в эксперименте. Источник: https://mbaradad.github.io/learning_with_noise/
Результаты, полученные исследователями, ставят под сомнение фундаментальную связь между нейронными сетями, основанными на изображениях, и изображениями «реального мира», которые бросаются в них с тревожной тревогой. большие объемы каждый год и подразумевают, что необходимость получать, курировать и иным образом пререкаться гипермасштабные наборы данных изображений со временем могут стать излишними. Авторы заявляют:
«Существующие системы технического зрения обучаются на огромных наборах данных, и эти наборы данных требуют затрат: курирование стоит дорого, они наследуют человеческие предубеждения, и есть опасения по поводу конфиденциальности и прав на использование. Чтобы компенсировать эти затраты, возрос интерес к изучению более дешевых источников данных, таких как немаркированные изображения.
«В этой статье мы делаем еще один шаг и спрашиваем, можем ли мы полностью отказаться от наборов данных реальных изображений, изучая процедурные шумовые процессы».
Исследователи предполагают, что современные архитектуры машинного обучения могут выводить из изображений нечто гораздо более фундаментальное (или, по крайней мере, неожиданное), чем считалось ранее, и что «бессмысленные» изображения потенциально могут передать гораздо больше этих знаний. дешево, даже с возможным использованием специальных синтетических данных, с помощью архитектур генерации наборов данных, которые генерируют случайные изображения во время обучения:
"Мы выделяем два ключевых свойства, которые делают синтетические данные хорошими для обучения систем зрения: 1) натурализм, 2) разнообразие. Интересно, что самые натуралистичные данные не всегда самые лучшие, поскольку натурализм может быть достигнут за счет разнообразия.
«Тот факт, что натуралистические данные помогают, неудивителен, и это говорит о том, что крупномасштабные реальные данные действительно имеют ценность. Однако мы находим, что важно не то, чтобы данные были реальные но чтобы это было натуралистический, т. е. он должен отражать определенные структурные свойства реальных данных.
«Многие из этих свойств можно отразить в простых моделях шума».

Визуализации признаков, полученные кодировщиком, производным от AlexNet, в некоторых из различных наборов данных «случайных изображений», используемых авторами, охватывающих 3-й и 5-й (последний) сверточный слой. Используемая здесь методология следует изложенной в Исследование Google AI от 2017 года.
Ассоциация бумаги, представленный на 35-й конференции по системам обработки нейронной информации (NeurIPS 2021) в Сиднее, называется Учимся видеть, глядя на шум, и исходит от шести исследователей из CSAIL с равным вкладом.
Работа была Управление по борьбе с наркотиками (DEA) консенсусом для выбора в центре внимания на NeurIPS 2021, при этом коллеги-комментаторы характеризуют статью как «научный прорыв», который открывает «большую область исследований», даже если она вызывает столько же вопросов, сколько и ответов.
В статье авторы делают вывод:
«Мы показали, что при разработке с использованием результатов прошлых исследований статистики естественных изображений эти наборы данных могут успешно обучать визуальные представления. Мы надеемся, что эта статья побудит к изучению новых генеративных моделей, способных создавать структурированный шум, достигая еще более высокой производительности при использовании в разнообразном наборе визуальных задач.
«Можно ли достичь производительности, полученной с помощью предварительной подготовки ImageNet? Возможно, в отсутствие большого обучающего набора, специфичного для конкретной задачи, лучшим предварительным обучением может быть не использование стандартного набора реальных данных, такого как ImageNet».















