
Artificial Intelligence
InstructIR: высококачественное восстановление изображений по инструкциям человека

Изображение может передать очень многое, но оно также может быть испорчено различными проблемами, такими как размытость при движении, дымка, шум и низкий динамический диапазон. Эти проблемы, обычно называемые ухудшением компьютерного зрения низкого уровня, могут возникнуть из-за сложных условий окружающей среды, таких как жара или дождь, или из-за ограничений самой камеры. Восстановление изображения представляет собой основную задачу в компьютерном зрении, поскольку необходимо восстановить высококачественное и чистое изображение из изображения с такими ухудшениями. Восстановление изображения является сложной задачей, поскольку может существовать несколько решений для восстановления любого изображения. Некоторые подходы нацелены на конкретные снижения качества, такие как уменьшение шума или устранение размытия или дымки.
Хотя эти методы могут дать хорошие результаты для решения конкретных проблем, им часто сложно обобщить различные типы деградации. Многие платформы используют общую нейронную сеть для широкого спектра задач восстановления изображений, но каждая из этих сетей обучается отдельно. Потребность в разных моделях для каждого типа деградации делает этот подход дорогостоящим и трудоемким, что приводит к тому, что в последних разработках основное внимание уделяется моделям восстановления «все в одном». В этих моделях используется единая модель глубокого слепого восстановления, которая учитывает несколько уровней и типов деградации, часто используя подсказки или векторы направления, специфичные для деградации, для повышения производительности. Хотя модели «все в одном» обычно показывают многообещающие результаты, они по-прежнему сталкиваются с проблемами, связанными с обратными задачами.
InstructIR представляет собой новаторский подход в этой области, будучи первым восстановление изображения структура, предназначенная для управления моделью восстановления с помощью инструкций, написанных человеком. Он может обрабатывать подсказки на естественном языке для восстановления высококачественных изображений из испорченных с учетом различных типов деградации. InstructIR устанавливает новый стандарт производительности для широкого спектра задач по восстановлению изображений, включая удаление искажений, шумоподавление, устранение дымки, устранение размытия и улучшение изображений при слабом освещении.
Целью этой статьи является более глубокое освещение платформы InstructIR, и мы исследуем механизм, методологию, архитектуру платформы, а также ее сравнение с современными платформами генерации изображений и видео. Итак, давайте начнем.
InstructIR: высококачественное восстановление изображений
Восстановление изображения является фундаментальной проблемой компьютерного зрения, поскольку оно направлено на восстановление высококачественного чистого изображения из изображения с ухудшениями. В низкоуровневом компьютерном зрении деградация — это термин, используемый для обозначения неприятных эффектов, наблюдаемых в изображении, таких как размытие изображения, дымка, шум, низкий динамический диапазон и т. д. Причина, по которой восстановление изображений является сложной обратной задачей, заключается в том, что для восстановления любого изображения может существовать множество различных решений. Некоторые платформы фокусируются на конкретных ухудшениях, таких как уменьшение шума экземпляра или шумоподавление изображения, в то время как другие могут больше сосредоточиться на удалении размытия или устранении размытия, или устранении дымки или устранении дымки.
Последние методы глубокого обучения показали более высокую и стабильную производительность по сравнению с традиционными методами восстановления изображений. Эти модели восстановления изображений с глубоким обучением предлагают использовать нейронные сети на основе трансформаторов и сверточных нейронных сетей. Эти модели можно независимо обучать для выполнения различных задач по восстановлению изображений, а также они обладают способностью фиксировать локальные и глобальные взаимодействия функций и улучшать их, что приводит к удовлетворительной и стабильной производительности. Хотя некоторые из этих методов могут адекватно работать для конкретных типов деградации, они обычно плохо экстраполируются на различные типы деградации. Более того, хотя многие существующие платформы используют одну и ту же нейронную сеть для множества задач восстановления изображений, каждая формула нейронной сети обучается отдельно. Следовательно, очевидно, что использование отдельной нейронной модели для каждой мыслимой деградации нецелесообразно и требует много времени, поэтому последние платформы восстановления изображений сконцентрировались на прокси-серверах восстановления «все в одном».
Модели восстановления изображений «все в одном», «мульти-деградация» или «многозадачность» набирают популярность в области компьютерного зрения, поскольку они способны восстанавливать несколько типов и уровней ухудшений изображения без необходимости обучения моделей независимо для каждого ухудшения. . Модели восстановления изображений «все в одном» используют одну модель глубокого слепого восстановления изображений для решения различных типов и уровней ухудшения качества изображения. В разных моделях «все в одном» реализованы разные подходы, помогающие слепой модели восстановить испорченное изображение, например, вспомогательная модель для классификации векторов деградации или многомерные наведения или подсказки, помогающие модели восстановить различные типы деградации в пределах изображения. изображение.
С учетом вышесказанного мы приходим к текстовой манипуляции с изображениями, поскольку за последние несколько лет она была реализована в нескольких средах для преобразования текста в изображение и задач редактирования текстовых изображений. Эти модели часто используют текстовые подсказки для описания действий или изображений вместе с модели на основе диффузии для создания соответствующих изображений. Основным источником вдохновения для платформы InstructIR является платформа InstructPix2Pix, которая позволяет модели редактировать изображение, используя пользовательские инструкции, указывающие модели, какое действие следует выполнять, вместо текстовых меток, описаний или подписей входного изображения. В результате пользователи могут использовать естественный письменный текст, чтобы указать модели, какое действие следует выполнить, без необходимости предоставления образцов изображений или дополнительных описаний изображений.
Основываясь на этих основах, платформа InstructIR является первой в мире моделью компьютерного зрения, которая использует написанные человеком инструкции для восстановления изображений и решения обратных задач. Для подсказок на естественном языке модель InstructIR может восстанавливать высококачественные изображения из их ухудшенных аналогов, а также учитывать несколько типов деградации. Платформа InstructIR способна обеспечить современную производительность при решении широкого спектра задач по восстановлению изображений, включая удаление искажений, шумоподавление, удаление дымки, устранение размытия и улучшение изображений при слабом освещении. В отличие от существующих работ, которые обеспечивают восстановление изображений с использованием изученных векторов направления или встраивания подсказок, платформа InstructIR использует необработанные пользовательские подсказки в текстовой форме. Платформа InstructIR способна обобщать восстановление изображений с использованием написанных человеком инструкций, а единая модель «все в одном», реализованная InstructIR, охватывает больше задач восстановления, чем предыдущие модели. На следующем рисунке показаны разнообразные образцы восстановления платформы InstructIR.

InstructIR: Метод и архитектура
По своей сути платформа InstructIR состоит из кодировщика текста и модели изображения. Модель использует структуру NAFNet, эффективную модель восстановления изображений, которая соответствует архитектуре U-Net в качестве модели изображения. Кроме того, в модели реализованы методы маршрутизации задач для успешного изучения нескольких задач с использованием одной модели. На следующем рисунке показан подход к обучению и оценке в рамках InstructIR.

Черпая вдохновение из модели InstructPix2Pix, платформа InstructIR использует письменные инструкции человека в качестве механизма управления, поскольку пользователю не требуется предоставлять дополнительную информацию. Эти инструкции предлагают выразительный и понятный способ взаимодействия, позволяя пользователям указать точное место и тип искажения изображения. Кроме того, использование подсказок для пользователей вместо фиксированных подсказок, специфичных для деградации, повышает удобство использования и применение модели, поскольку ее также могут использовать пользователи, которым не хватает необходимого опыта в предметной области. Чтобы снабдить платформу InstructIR способностью понимать разнообразные подсказки, модель использует GPT-4, большую языковую модель для создания разнообразных запросов, при этом неоднозначные и неясные подсказки удаляются после процесса фильтрации.
Текстовый кодировщик
Кодировщик текста используется языковыми моделями для сопоставления подсказок пользователя с встраиванием текста или векторным представлением фиксированного размера. Традиционно текстовый кодер Модель CLIP является жизненно важным компонентом для создания текстовых изображений и моделей манипулирования текстовыми изображениями для кодирования пользовательских подсказок, поскольку платформа CLIP превосходно справляется с визуальными подсказками. Однако в большинстве случаев пользовательские запросы об ухудшении качества практически не содержат визуального контента, что делает большие кодеры CLIP бесполезными для таких задач, поскольку это значительно снижает эффективность. Чтобы решить эту проблему, платформа InstructIR выбирает текстовый кодировщик предложений, который обучен кодировать предложения в значимом пространстве встраивания. Кодировщики предложений предварительно обучены на миллионах примеров, но при этом они компактны и эффективны по сравнению с традиционными кодировщиками текста на основе CLIP, но при этом имеют возможность кодировать семантику различных пользовательских подсказок.
Текстовое руководство
Основным аспектом платформы InstructIR является реализация закодированной инструкции в качестве механизма управления моделью изображения. Основываясь на этом и вдохновившись маршрутизацией задач для обучения многим задачам, платформа InstructIR предлагает блок построения инструкций или ICB, позволяющий осуществлять преобразования в модели для конкретных задач. Традиционная маршрутизация задач применяет двоичные маски, специфичные для задачи, к функциям канала. Однако, поскольку платформа InstructIR не знает об деградации, этот метод не реализуется напрямую. Кроме того, для функций изображения и закодированных инструкций платформа InstructIR применяет маршрутизацию задач и создает маску, используя линейный слой, активированный с помощью функции Sigmoid, для создания набора весов в зависимости от встраивания текста, таким образом получая c-мерное значение для каждого изображения. бинарная маска канала. Модель дополнительно расширяет условные функции с помощью NAFBlock и использует NAFBlock и условный блок инструкций для формирования функций как в блоке кодера, так и в блоке декодера.
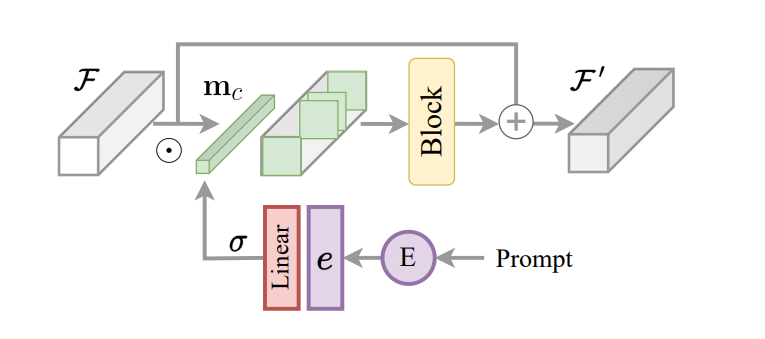
Хотя структура InstructIR не определяет фильтры нейронной сети явным образом, маска помогает модели выбирать наиболее релевантные каналы на основе инструкций изображения и информации.
InstructIR: реализация и результаты
Модель InstructIR поддается сквозному обучению, а модель изображения не требует предварительного обучения. Обучаться необходимо только проекциям встраивания текста и головке классификации. Кодировщик текста инициализируется с использованием кодера BGE, кодера, подобного BERT, который предварительно обучен на огромном объеме контролируемых и неконтролируемых данных для кодирования предложений общего назначения. Платформа InstructIR использует модель NAFNet в качестве модели изображения, а архитектура NAFNet состоит из четырехуровневого кодера-декодера с различным количеством блоков на каждом уровне. Модель также добавляет 4 средних блока между кодером и декодером для дальнейшего улучшения функций. Более того, вместо объединения пропущенных соединений декодер реализует сложение, а модель InstructIR реализует только ICB или условный блок инструкций для маршрутизации задач только в кодере и декодере. Двигаясь дальше, модель InstructIR оптимизируется с использованием потерь между восстановленным изображением и чистым изображением, а перекрестная энтропийная потеря используется для заголовка классификации намерений текстового кодировщика. Модель InstructIR использует оптимизатор AdamW с размером пакета 4 и скоростью обучения 32e-5 для почти 4 эпох, а также реализует затухание скорости обучения косинусного отжига. Поскольку модель изображения в среде InstructIR содержит всего 500 миллионов параметров, а изученных параметров проекции текста всего 16 тысяч, среду InstructIR можно легко обучить на стандартных графических процессорах, что снижает вычислительные затраты и повышает применимость.
Множественные результаты деградации
Для множественных деградаций и многозадачных восстановлений платформа InstructIR определяет две начальные настройки:
- 3D для моделей с тремя деградациями для решения таких проблем, как удаление дымки, шумоподавление и удаление осадков.
- 5D для пяти моделей деградации для решения таких проблем, как шумоподавление изображения, улучшение при слабом освещении, удаление матовости, шумоподавление и удаление помех.
Производительность 5D-моделей продемонстрирована в следующей таблице и сравнивается с современными моделями восстановления изображений и моделями «все в одном».

Как можно заметить, платформа InstructIR с простой моделью изображения и всего 16 миллионами параметров может успешно решать пять различных задач по восстановлению изображений благодаря руководству на основе инструкций и обеспечивает конкурентоспособные результаты. В следующей таблице показана производительность платформы на 3D-моделях, и результаты сопоставимы с приведенными выше результатами.

Основной особенностью платформы InstructIR является восстановление изображений на основе инструкций, а следующий рисунок демонстрирует невероятные способности модели InstructIR понимать широкий спектр инструкций для конкретной задачи. Кроме того, для состязательной инструкции модель InstructIR выполняет идентификацию, которая не является принудительной.

Заключение
Восстановление изображения является фундаментальной проблемой компьютерного зрения, поскольку оно направлено на восстановление высококачественного чистого изображения из изображения с ухудшениями. В низкоуровневом компьютерном зрении деградация — это термин, используемый для обозначения неприятных эффектов, наблюдаемых в изображении, таких как размытие изображения, дымка, шум, низкий динамический диапазон и т. д. В этой статье мы говорили об InstructIR, первой в мире платформе восстановления изображений, целью которой является управление моделью восстановления изображений с использованием инструкций, написанных человеком. Для подсказок на естественном языке модель InstructIR может восстанавливать высококачественные изображения из их ухудшенных аналогов, а также учитывать несколько типов деградации. Платформа InstructIR способна обеспечить современную производительность при решении широкого спектра задач по восстановлению изображений, включая удаление искажений, шумоподавление, удаление дымки, устранение размытия и улучшение изображений при слабом освещении.















