
Artificial Intelligence
Детекторы дипфейков осваивают новые направления: модели скрытой диффузии и GAN

Обзор В последнее время исследовательское сообщество по обнаружению дипфейков, которое с конца 2017 года занимается почти исключительно автоэнкодерна основе фреймворка, премьера которого в то время вызвала такой общественный трепет (и испуг), начал проявлять судебный интерес к менее застойным архитектурам, включая скрытая диффузия такие модели, как ДАЛЛ-Э 2 и Стабильная диффузия, а также выходные данные генеративно-состязательных сетей (GAN). Например, в июне Калифорнийский университет в Беркли опубликовали результаты своих исследований по разработке детектора для выхода доминирующего в то время DALL-E 2.
Этот растущий интерес, по-видимому, вызван внезапным эволюционным скачком в возможностях и доступности моделей скрытой диффузии в 2022 году с закрытым исходным кодом и ограниченным доступом. освободить DALL-E 2 весной, а в конце лета – сенсационное открытый источник стабильной диффузии с помощью stable.ai.
GAN также были давно изученный в этом контексте, хотя и менее интенсивно, поскольку очень трудно использовать их для убедительных и продуманных видео-воспроизведений людей; по крайней мере, по сравнению с уважаемыми теперь пакетами автоэнкодера, такими как обмен лицами и DeepFaceLab - и двоюродный брат последнего в прямом эфире, DeepFaceLive.
Движущиеся картинки
В любом случае стимулирующим фактором, по-видимому, является перспектива последующего спринта в области развития. видео синтез. Начало октября — и главный сезон конференций 2022 года — характеризовалось лавиной внезапных и неожиданных решений различных давних проблем синтеза видео: как только Facebook выпущенные образцы своей собственной платформы преобразования текста в видео, Google Research быстро заглушила это первоначальное признание, объявив о своей новой архитектуре Imagen-to-Video T2V, способной выводить кадры в высоком разрешении (правда, только через 7-уровневую сеть апскейлеров).
Если вы считаете, что такого рода вещи приходят втроем, рассмотрите также загадочное обещание стабильности.ай о том, что «видео появится» в Stable Diffusion, по-видимому, в конце этого года, в то время как один из разработчиков Stable Diffusion Runway дал такое же обещание, хотя неясно, относятся ли они к одной и той же системе. Discord-сообщение от генерального директора Stability Эмада Мостака также пообещал «аудио, видео [и] 3d».
Что с неожиданным предложением нескольких новых фреймворки для генерации звука (некоторые основаны на скрытой диффузии) и новая модель диффузии, которая может генерировать аутентичное движение персонажа, идея о том, что «статические» фреймворки, такие как GAN и диффузоры, наконец, займут свое место в качестве поддержки адъюнкты к внешним анимационным фреймворкам начинает набирать обороты.
Короче говоря, вполне вероятно, что ограниченный мир дипфейков видео на основе автокодировщиков, которые могут лишь эффективно заменить центральная часть лица, к этому времени в следующем году может быть вытеснено новым поколением технологий дипфейка на основе диффузии — популярных подходов с открытым исходным кодом, способных фотореалистично подделывать не только целые тела, но и целые сцены.
Возможно, по этой причине исследовательское сообщество, выступающее против дипфейков, начинает серьезно относиться к синтезу изображений и понимать, что он может служить большему количеству целей, чем просто создание поддельные фотографии профиля LinkedIn; и что если все их непостижимые латентные пространства могут выполняться с точки зрения временного движения, действовать как действительно отличный рендерер текстур, этого может быть более чем достаточно.
Blade Runner
Последние две статьи, посвященные скрытой диффузии и обнаружению дипфейков на основе GAN, соответственно, DE-FAKE: обнаружение и атрибуция поддельных изображений, созданных с помощью моделей преобразования текста в изображение, результат сотрудничества Центра информационной безопасности Гельмгольца CISPA и Salesforce; и BLADERUNNER: Быстрая контрмера для синтетических (создаваемых искусственным интеллектом) лиц StyleGAN, от Адама Дориана Вонга из Линкольнской лаборатории Массачусетского технологического института.
Прежде чем объяснять свой новый метод, в последнем документе требуется некоторое время для изучения предыдущих подходов к определению того, было ли изображение сгенерировано GAN (документ конкретно посвящен семейству StyleGAN от NVIDIA).
Метод «группы Брейди» — возможно, бессмысленная ссылка для тех, кто не смотрел телевизор в 1970-х или кто пропустил экранизацию фильмов 1990-х — идентифицирует поддельный контент GAN на основе фиксированных позиций, которые наверняка занимают определенные части лица GAN, из-за механического и шаблонного характера 'производственный процесс'.

Метод «Группы Брейди», предложенный веб-трансляцией института SANS в 2022 году: генератор лиц на основе GAN в определенных случаях будет выполнять невероятно равномерное размещение определенных черт лица, опровергая происхождение фотографии. Источник: https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
Другим полезным известным признаком является частая неспособность StyleGAN отображать несколько лиц (первое изображение ниже), если это необходимо, а также отсутствие у него таланта в координации аксессуаров (среднее изображение ниже) и склонность использовать линию роста волос в качестве начала импровизации. шляпа (третье изображение ниже).

Третий метод, на который обращает внимание исследователь, это наложение фото (пример которого можно увидеть в наша августовская статья по диагностике психических расстройств с помощью ИИ), в котором используется композиционное программное обеспечение для «смешивания изображений», такое как серия CombineZ, для объединения нескольких изображений в одно изображение, часто выявляя основные общие черты в структуре — потенциальное указание на синтез.

Архитектура, предложенная в новой статье, называется (возможно, вопреки всем советам по SEO) Blade Runner, ссылаясь на Тест Войта-Кампфа это определяет, являются ли антагонисты в научно-фантастической франшизе «фальшивыми» или нет.
Конвейер состоит из двух этапов, первым из которых является анализатор PapersPlease, который может оценивать данные, полученные с известных веб-сайтов GAN, таких как thispersondoesnotexist.com или generate.photos.

Хотя урезанную версию кода можно просмотреть на GitHub (см. ниже), об этом модуле предоставлено мало подробностей, за исключением того, что OpenCV и ДЛИБ используются для выделения и обнаружения лиц в собранном материале.
Второй модуль — это Среди нас детектор. Система предназначена для поиска скоординированного расположения глаз на фотографиях, постоянной функции вывода лица StyleGAN, типизированной в сценарии «Брэди Банч», описанном выше. Среди нас используется стандартный детектор с 68 ориентирами.

Аннотации точек лица через Intelligent Behavior Understanding Group (IBUG), чей код построения ориентиров лица используется в пакете Blade Runner.
Среди нас используются предварительно обученные ориентиры, основанные на известных координатах «группы Брейди» из PapersPlease, и предназначен для использования с живыми веб-образцами изображений лиц на основе StyleGAN.
Автор предполагает, что Blade Runner — это готовое к работе решение, предназначенное для компаний или организаций, которым не хватает ресурсов для разработки собственных решений для того типа обнаружения дипфейков, о котором идет речь здесь, и «временная мера, позволяющая выиграть время для более постоянные контрмеры».
На самом деле, в столь нестабильном и быстрорастущем секторе безопасности не так много индивидуальных решений. or готовые облачные решения поставщиков, к которым в настоящее время может с уверенностью обращаться компания с ограниченными ресурсами.
Хотя Blade Runner плохо работает против носящий очки Люди, подделывающие StyleGAN, это относительно распространенная проблема в аналогичных системах, которые ожидают, что смогут оценивать очертания глаз как основные точки отсчета, скрытые в таких случаях.
Вышла уменьшенная версия Blade Runner. выпустил с открытым исходным кодом на GitHub. Существует более многофункциональная проприетарная версия, которая может обрабатывать несколько фотографий, а не одну фотографию за операцию репозитория с открытым исходным кодом. По его словам, автор намерен в конечном итоге обновить версию GitHub до того же стандарта, как только позволит время. Он также признает, что StyleGAN, скорее всего, будет развиваться за пределами своих известных или текущих недостатков, и программное обеспечение также должно будет развиваться в тандеме.
ДЕ-ФЕЙК
Архитектура DE-FAKE нацелена не только на «универсальное обнаружение» изображений, созданных с помощью моделей диффузии текста в изображение, но и на предоставление метода распознавания. который Модель скрытой диффузии (LD) создала изображение.
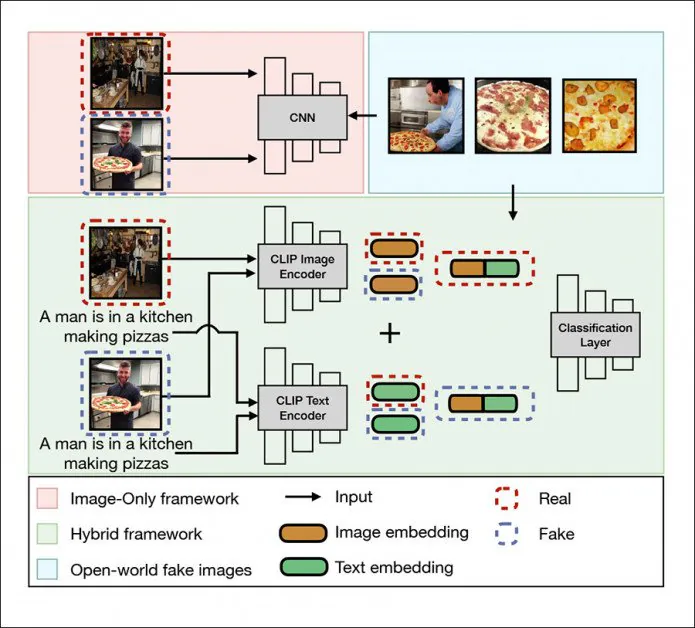
Универсальная структура обнаружения в DE-FAKE обращается к локальным изображениям, гибридной среде (зеленый) и изображениям открытого мира (синий). Источник: http://export.arxiv.org/pdf/2210.06998.
Честно говоря, на данный момент это довольно легкая задача, так как все популярные модели LD — закрытые или открытые — имеют заметные отличительные характеристики.
Кроме того, большинство из них имеют некоторые общие недостатки, такие как предрасположенность к отрубанию голов из-за произвольным образом что неквадратные изображения, извлеченные из Интернета, загружаются в массивные наборы данных, которые питают такие системы, как DALL-E 2, Stable Diffusion и MidJourney:

Модели скрытой диффузии, как и все модели компьютерного зрения, требуют ввода квадратного формата; но совокупный веб-скрапинг, который питает набор данных LAION5B, не предлагает никаких «роскошных дополнений», таких как возможность распознавать лица и фокусироваться на них (или что-то еще), и довольно жестко усекает изображения вместо того, чтобы дополнять их (что позволило бы сохранить весь исходный код). изображение, но в меньшем разрешении). После обучения эти «посевы» становятся нормализованными и очень часто возникают в результате работы скрытых диффузионных систем, таких как стабильная диффузия. Источники: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac и Stable Diffusion.
DE-FAKE задуман как независимый от алгоритма, давняя цель исследователей автоэнкодера против дипфейков, и прямо сейчас вполне достижимая в отношении систем LD.
Архитектура использует Contrastive Language-Image Pretraining от OpenAI (CLIP) мультимодальная библиотека — важный элемент стабильной диффузии и быстро становится сердцем новой волны систем синтеза изображений/видео — как способ извлечения вложений из «поддельных» LD-изображений и обучения классификатора на наблюдаемых шаблонах и классах.
В более «черном ящике», где фрагменты PNG, содержащие информацию о процессе генерации, уже давно удалены процессами загрузки и по другим причинам, исследователи используют Salesforce. BLIP-фреймворк (также компонент в хотя бы один распределение стабильной диффузии) для «слепого» опроса изображений на предмет вероятной семантической структуры подсказок, которые их создали.

Исследователи использовали Stable Diffusion, Latent Diffusion (сам по себе отдельный продукт), GLIDE и DALL-E 2 для заполнения набора данных для обучения и тестирования с использованием MSCOCO и Flickr30k.
Обычно мы достаточно подробно изучаем результаты экспериментов исследователей с новой структурой; но на самом деле выводы DE-FAKE кажутся более полезными в качестве будущего эталона для более поздних итераций и подобных проектов, а не в качестве значимого показателя успеха проекта, учитывая изменчивую среду, в которой он работает, и систему, в которой он работает. с которым конкурирует в испытаниях газеты, почти три года назад — с тех пор, когда сцена синтеза изображений действительно зарождалась.

Крайние два левых изображения: «проблемная» предыдущая структура, созданная в 2019 году, как и ожидалось, хуже справляется с DE-FAKE (два крайних правых изображения) в четырех протестированных системах LD.
Результаты команды в подавляющем большинстве положительные по двум причинам: существует мало предыдущих работ, с которыми можно было бы их сравнить (и вообще нет ни одной, которая предлагает справедливое сравнение, т. е. охватывает всего лишь двенадцать недель с момента выпуска Stable Diffusion с открытым исходным кодом).
Во-вторых, как упоминалось выше, хотя область синтеза LD-изображений развивается с экспоненциальной скоростью, выходной контент текущих предложений эффективно помечает себя своими структурными (и очень предсказуемыми) недостатками и эксцентричностью, многие из которых, вероятно, будут исправлены. в случае Stable Diffusion, по крайней мере, путем выпуска более производительной контрольной точки 1.5 (т. е. обученной модели объемом 4 ГБ, питающей систему).
В то же время Stability уже указал, что у него есть четкая дорожная карта для V2 и V3 системы. Учитывая захватывающие заголовки события последних трех месяцев, любое корпоративное оцепенение со стороны OpenAI и других конкурирующих игроков в области синтеза изображений, вероятно, испарилось, а это означает, что мы можем ожидать столь же быстрого прогресса и в пространство синтеза изображений с закрытым исходным кодом.
Впервые опубликовано 14 октября 2022 г.















