
Artificial Intelligence
Как стабильное распространение может превратиться в основной потребительский продукт

Как ни странно, Стабильная диффузияn, новый фреймворк синтеза изображений ИИ, который штурмом покорил мир, не является ни стабильным, ни действительно «распространенным» — по крайней мере, пока.
Полный спектр возможностей системы распределен по разнообразному шведскому столу постоянно видоизменяющихся предложений от горстки разработчиков, лихорадочно обменивающихся последней информацией и теориями в различных беседах на Discord, и подавляющее большинство процедур установки для пакетов, которые они создают или модификация очень далека от «подключи и работай».
Скорее, они, как правило, требуют командной строки или управляемый BAT установка через GIT, Conda, Python, Miniconda и другие передовые среды разработки — программные пакеты, настолько редкие среди обычных потребителей, что их установка часто помечается поставщиками антивирусных и антивредоносных программ как свидетельство скомпрометированной хост-системы.

Только небольшой выбор этапов в перчатке, которая в настоящее время требуется для стандартной установки Stable Diffusion. Для многих дистрибутивов также требуются определенные версии Python, которые могут конфликтовать с существующими версиями, установленными на компьютере пользователя, хотя этого можно избежать с помощью установок на основе Docker и, в определенной степени, с помощью сред Conda.
Потоки сообщений в сообществах SFW и NSFW Stable Diffusion переполнены советами и рекомендациями, связанными со взломом скриптов Python и стандартной установкой, чтобы обеспечить улучшенную функциональность или устранить частые ошибки зависимостей, а также ряд других проблем.
Это оставляет среднего потребителя, заинтересованного в создание потрясающих образов из текстовых подсказок, в значительной степени во власти растущего числа монетизированных веб-интерфейсов API, большинство из которых предлагают минимальное количество бесплатных поколений изображений, прежде чем потребуется покупка токенов.
Кроме того, почти все эти веб-предложения отказываются выводить контент NSFW (большая часть которого может относиться к темам общего интереса, не связанным с порнографией, таким как «война»), что отличает Stable Diffusion от сервисов DALL-E от OpenAI. 2.
«Фотошоп для стабильной диффузии»
Взволнованный невероятными, колоритными или потусторонними изображениями, которые ежедневно заполняют хэштег Твиттера #stablediffusion, то, чего, возможно, ждет весь мир, это «Фотошоп для стабильной диффузии» – кроссплатформенное устанавливаемое приложение, сочетающее в себе лучшие и самые мощные функциональные возможности архитектуры Stability.ai, а также различные гениальные новшества появляющегося сообщества разработчиков SD, без каких-либо плавающих окон CLI, неясной и постоянно меняющейся установки и обновления. подпрограммы или отсутствующие функции.
То, что у нас есть в настоящее время, в большинстве более функциональных установок, представляет собой элегантную веб-страницу, окруженную бестелесным окном командной строки, и URL-адрес которой является портом локального хоста:

Подобно приложениям для синтеза на основе CLI, таким как FaceSwap и ориентированному на BAT DeepFaceLab, «предварительная» установка Stable Diffusion показывает свои корни командной строки с доступом к интерфейсу через локальный порт (см. с функциональностью Stable Diffusion на основе CLI.
Без сомнения, грядет более оптимизированное приложение. Уже есть несколько встроенных приложений на основе Patreon, которые можно загрузить, например, ГРиск и НМКД (см. изображение ниже).

Ранние пакеты Stable Diffusion на основе Patreon, слегка «приложенные». NMKD первым интегрировал вывод командной строки непосредственно в графический интерфейс.
Давайте посмотрим, как в конечном итоге может выглядеть более совершенная и цельная реализация этого удивительного чуда с открытым исходным кодом, и с какими проблемами она может столкнуться.
Юридические аспекты полностью финансируемого коммерческого приложения стабильной диффузии
Фактор NSFW
Исходный код Stable Diffusion был выпущен под лицензией чрезвычайно либеральная лицензия который не запрещает коммерческие повторные реализации и производные работы, которые в значительной степени основаны на исходном коде.
Помимо вышеупомянутого и растущего числа сборок Stable Diffusion на основе Patreon, а также большого количества плагинов приложений, разрабатываемых для Figma, Krita, Photoshop, GIMPи смеситель (среди прочих) нет практический Причина, по которой хорошо финансируемая компания по разработке программного обеспечения не может разработать гораздо более сложное и функциональное приложение Stable Diffusion. С точки зрения рынка есть все основания полагать, что несколько таких инициатив уже реализуются.
Здесь такие усилия сразу же сталкиваются с дилеммой: позволит ли приложение, как и большинство веб-API для Stable Diffusion, использовать встроенный фильтр NSFW Stable Diffusion (a фрагмент кода), чтобы быть выключенным.
«Хороня» коммутатор NSFW
Хотя лицензия Stability.ai с открытым исходным кодом для Stable Diffusion включает широкий интерпретируемый список приложений, для которых она может не использоваться (возможно, в том числе порнографическое содержание и deepfakes), единственный способ, которым поставщик может эффективно запретить такое использование, — это скомпилировать фильтр NSFW в непрозрачный исполняемый файл вместо параметра в файле Python или принудительно применить сравнение контрольной суммы в файле Python или DLL, содержащем директиву NSFW. так что рендеринг не может произойти, если пользователи изменят этот параметр.
Это оставило бы предполагаемое приложение «кастрированным» почти так же, как DALL-E 2 в настоящее время, что снижает его коммерческую привлекательность. Кроме того, декомпилированные «подправленные» версии этих компонентов (либо исходные элементы среды выполнения Python, либо скомпилированные DLL-файлы, которые сейчас используются в линейке инструментов улучшения изображений ИИ Topaz), вероятно, появятся в сообществе торрентов/хакеров, чтобы разблокировать такие ограничения. , просто заменив мешающие элементы и отменив любые требования к контрольной сумме.
В конце концов, поставщик может просто повторить предупреждение Stability.ai о неправомерном использовании, которое характеризует первый запуск многих текущих дистрибутивов Stable Diffusion.
Тем не менее, небольшие разработчики с открытым исходным кодом, которые в настоящее время используют случайные заявления об отказе от ответственности, мало что теряют по сравнению с компанией-разработчиком программного обеспечения, которая вложила значительное количество времени и денег в то, чтобы сделать Stable Diffusion полнофункциональным и доступным, что требует более глубокого рассмотрения.
Ответственность за дипфейк
Поскольку у нас есть недавно отметилБаза данных LAION-esthetics, входящая в число 4.2 миллиардов изображений, на которых обучались текущие модели Stable Diffusion, содержит большое количество изображений знаменитостей, что позволяет пользователям эффективно создавать дипфейки, в том числе дипфейк-порно со знаменитостями.

Из нашей недавней статьи четыре этапа Дженнифер Коннелли за четыре десятилетия ее карьеры, выведенные из стабильной диффузии.
Это отдельный и более спорный вопрос, чем создание (обычно) легального «абстрактного» порно, в котором не изображены «настоящие» люди (хотя такие изображения выводятся из множества реальных фотографий в учебных материалах).
Поскольку все большее число штатов и стран США разрабатывают или вводят законы против дипфейковой порнографии, способность Stable Diffusion создавать порно со знаменитостями может означать, что коммерческое приложение, которое не подвергается полной цензуре (т. е. может создавать порнографические материалы), все же может нуждаться возможность фильтровать воспринимаемые лица знаменитостей.
Одним из методов может быть предоставление встроенного «черного списка» терминов, которые не будут приняты в приглашении пользователя, относящихся к именам знаменитостей и вымышленным персонажам, с которыми они могут быть связаны. Предположительно, такие настройки должны быть установлены на большем количестве языков, чем только английский, поскольку исходные данные содержат другие языки. Другой подход может заключаться в использовании систем распознавания знаменитостей, таких как разработанные Clarifai.
Производителям программного обеспечения может быть необходимо включить такие методы, которые, возможно, изначально были отключены, что может помочь предотвратить создание полноценным автономным приложением Stable Diffusion лиц знаменитостей до принятия нового законодательства, которое может сделать такую функциональность незаконной.
Однако и в этом случае такая функциональность неизбежно может быть декомпилирована и изменена заинтересованными сторонами; однако производитель программного обеспечения может в этом случае заявить, что это фактически несанкционированный вандализм - до тех пор, пока этот вид реверс-инжиниринга не будет чрезмерно упрощен.
Возможности, которые могут быть включены
Основные функциональные возможности любого дистрибутива Stable Diffusion можно ожидать от любого хорошо финансируемого коммерческого приложения. К ним относится возможность использовать текстовые подсказки для создания подходящих изображений (текст в изображение); возможность использовать эскизы или другие изображения в качестве руководства для новых сгенерированных изображений (изображение к изображению); средства регулировки того, насколько «творческой» должна быть система; способ компромисса между временем рендеринга и качеством; и другие «основы», такие как дополнительное автоматическое архивирование изображений/подсказок и обычное дополнительное масштабирование с помощью РеалESRGAN, и хотя бы базовую "коррекцию лица" с помощью ГФПГАН or КодФормер.
Это довольно «ванильная установка». Давайте взглянем на некоторые из более продвинутых функций, разрабатываемых или расширяемых в настоящее время, которые могут быть включены в полноценное «традиционное» приложение Stable Diffusion.
Стохастическая заморозка
Даже если ты повторно использовать семя из предыдущего успешного рендера ужасно сложно заставить Stable Diffusion точно повторять трансформацию, если любая часть подсказки или исходного изображения (или обоих) изменяется для последующего рендеринга.
Это проблема, если вы хотите использовать ЭбСинт чтобы наложить преобразования Stable Diffusion на реальное видео во временной согласованности, хотя этот метод может быть очень эффективным для простых снимков головы и плеч:

Ограниченное движение может сделать EbSynth эффективной средой для превращения преобразований Stable Diffusion в реалистичное видео. Источник: https://streamable.com/u0pgzd
EbSynth работает, экстраполируя небольшой набор «измененных» ключевых кадров в видео, которое было преобразовано в серию файлов изображений (и которые позже могут быть снова собраны в видео).

В этом примере с сайта EbSynth небольшое количество кадров из видео нарисовано в художественной манере. EbSynth использует эти кадры в качестве руководства по стилю, чтобы аналогичным образом изменить все видео, чтобы оно соответствовало нарисованному стилю. Источник: https://www.youtube.com/embed/eghGQtQhY38
В приведенном ниже примере, где (настоящая) блондинка-инструктор по йоге слева практически не двигается, Stable Diffusion по-прежнему испытывает трудности с сохранением постоянного лица, потому что три изображения, преобразованные в «ключевые кадры», не полностью идентичны. хотя все они имеют одно и то же числовое начальное число.

Здесь, даже с одним и тем же приглашением и начальным значением для всех трех преобразований и очень небольшими изменениями между исходными кадрами, мышцы тела различаются по размеру и форме, но, что более важно, лицо непоследовательно, что препятствует временной согласованности в потенциальном рендеринге EbSynth.
Хотя видео SD/EbSynth ниже очень изобретательно, где пальцы пользователя были преобразованы (соответственно) в ходячую пару ног в штанах и утку, несоответствие брюк типизирует проблему, с которой Stable Diffusion поддерживает согласованность в разных ключевых кадрах. , даже если исходные кадры похожи друг на друга, а начальное значение согласовано.

Пальцы человека становятся ходячим человеком и уткой с помощью Stable Diffusion и EbSynth. Источник: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Пользователь, создавший это видео , имея в виду что преобразование утки, возможно, более эффективное из двух, хотя и менее яркое и оригинальное, потребовало только одного ключевого кадра преобразования, в то время как для создания прогулочных брюк, которые демонстрируют более временную ориентацию, необходимо было выполнить рендеринг 50 изображений Stable Diffusion. непоследовательность. Пользователь также отметил, что потребовалось пять попыток для достижения согласованности для каждого из 50 ключевых кадров.
Поэтому было бы большим преимуществом, если бы действительно комплексное приложение Stable Diffusion обеспечивало функциональность, максимально сохраняющую характеристики по ключевым кадрам.
Одна из возможностей заключается в том, чтобы приложение позволяло пользователю «замораживать» стохастическое кодирование для преобразования каждого кадра, что в настоящее время может быть достигнуто только путем изменения исходного кода вручную. Как показывает приведенный ниже пример, это способствует временной согласованности, хотя и не решает ее:

Один пользователь Reddit трансформировал кадры с веб-камеры, на которых он запечатлен, в разных известных людей, не просто сохраняя начальное число (что может сделать любая реализация Stable Diffusion), но и гарантируя, что параметр stochastic_encode() идентичен при каждом преобразовании. Это было достигнуто путем изменения кода, но может легко стать доступным для пользователя переключателем. Ясно, однако, что это не решает всех временных проблем. Источник: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Облачная инверсия текста
Лучшим решением для выявления согласованных во времени персонажей и объектов является «запекание» их в Текстовая инверсия – файл размером 5 КБ, который можно обучить за несколько часов на основе всего пяти аннотированных изображений, которые затем можно извлечь с помощью специального '*' подсказка, позволяющая, например, постоянное появление новых персонажей для включения в повествование.

Изображения, связанные с соответствующими тегами, могут быть преобразованы в отдельные объекты с помощью инверсии текста и вызваны без двусмысленности, в правильном контексте и стиле с помощью специальных слов-символов. Источник: https://huggingface.co/docs/diffusers/training/text_inversion
Текстовые инверсии являются дополнительными файлами к очень большой и полностью обученной модели, которую использует Stable Diffusion, и эффективно «встраиваются» в процесс извлечения/подсказки, так что они могут участвовать в сценах, полученных из модели, и извлекайте выгоду из огромной базы данных модели об объектах, стилях, средах и взаимодействиях.
Однако, хотя обучение текстовой инверсии не занимает много времени, для нее требуется большой объем видеопамяти; согласно различным текущим пошаговым инструкциям, где-то между 12, 20 и даже 40 ГБ.
Поскольку большинство случайных пользователей вряд ли будут иметь в своем распоряжении такой вес графического процессора, уже появляются облачные сервисы, которые справятся с этой операцией, включая версию Hugging Face. Хотя есть Реализации Google Colab которые могут создавать текстовые инверсии для Stable Diffusion, необходимая видеопамять и требования к времени могут сделать это сложным для пользователей бесплатного уровня Colab.
Для потенциально полноценного и хорошо вложенного приложения Stable Diffusion (установленного) передача этой тяжелой задачи через облачные серверы компании кажется очевидной стратегией монетизации (при условии, что недорогое или бесплатное приложение Stable Diffusion пронизано такими не- бесплатная функциональность, которая кажется вероятной во многих возможных приложениях, которые появятся на основе этой технологии в ближайшие 6-9 месяцев).
Кроме того, довольно сложный процесс аннотирования и форматирования представленных изображений и текста может выиграть от автоматизации в интегрированной среде. Потенциальный «захватывающий фактор» создания уникальных элементов, которые могут исследовать и взаимодействовать с огромными мирами Stable Diffusion, может показаться потенциально навязчивым как для обычных энтузиастов, так и для молодых пользователей.
Универсальное взвешивание подсказок
Существует множество текущих реализаций, которые позволяют пользователю выделять часть длинного текстового приглашения, но инструментальные средства довольно сильно различаются между ними и часто бывают неуклюжими или неинтуитивными.
Очень популярная вилка Stable Diffusion. АВТОМАТИЧЕСКИЙ1111, например, может понизить или повысить значение слова-подсказки, заключив его в одну или несколько квадратных скобок (для уменьшения акцента) или в квадратные скобки для дополнительного выделения.

Квадратные скобки и/или круглые скобки могут преобразить ваш завтрак в этой версии весов подсказок Stable Diffusion, но в любом случае это кошмар холестерина.
В других итерациях Stable Diffusion для выделения используются восклицательные знаки, а наиболее универсальные позволяют пользователям назначать вес каждому слову в подсказке через графический интерфейс.
Система также должна позволять отрицательные мгновенные веса - не только для фанаты ужасов, а потому, что в скрытом пространстве Stable Diffusion может быть меньше тревожных и больше поучительных тайн, чем может вызвать наше ограниченное использование языка.
Перекраска
Вскоре после сенсационного открытия Stable Diffusion с открытым исходным кодом OpenAI попыталась — по большей части тщетно — вернуть часть своего успеха DALL-E 2 с помощью объявляющий «закрашивание», которое позволяет пользователю расширять изображение за его границы с помощью семантической логики и визуальной согласованности.
Естественно, с тех пор это в XNUMX году в различных формах для стабильной диффузии, а также в Крите, и, безусловно, должен быть включен в комплексную версию Stable Diffusion в стиле Photoshop.
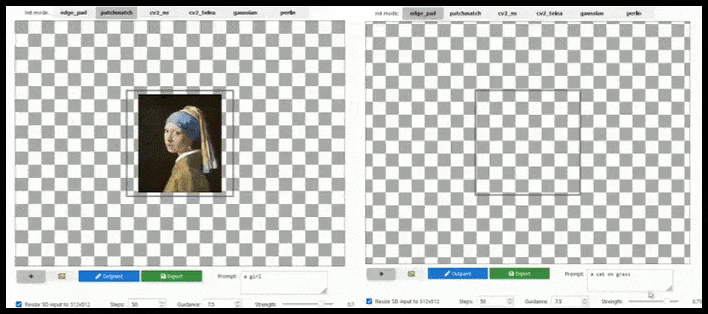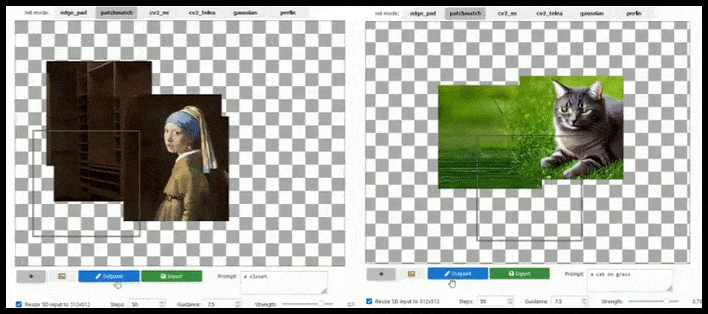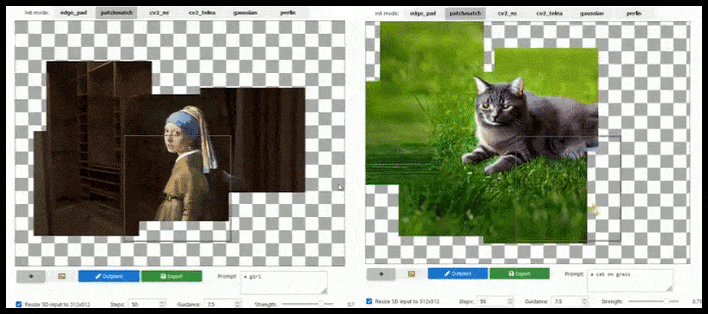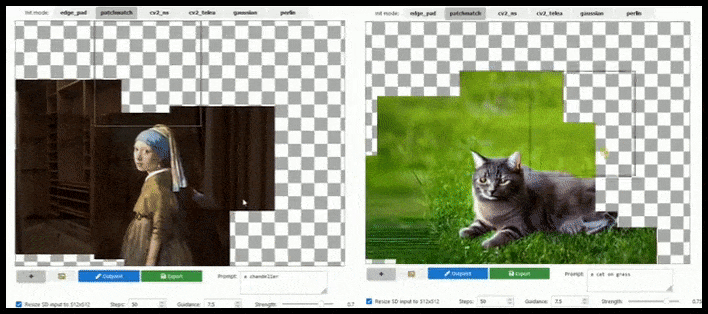
Аугментация на основе тайлов может почти бесконечно расширять стандартный рендеринг 512×512, если это позволяют подсказки, существующее изображение и семантическая логика. Источник: https://github.com/lkwq007/stablediffusion-infinity
Поскольку Stable Diffusion обучается на изображениях размером 512x512 пикселей (и по ряду других причин), он часто отрезает головы (или другие важные части тела) от людей, даже если в подсказке четко указано «акцент на голове» и т. д.

Типичные примеры «обезглавливания» стабильной диффузии; но перекрашивание могло вернуть Джорджа на сцену.
Любая реализация перерисовки типа, показанного на анимированном изображении выше (которая основана исключительно на библиотеках Unix, но должна быть способна быть воспроизведена в Windows), также должна быть инструментом для решения этой проблемы одним щелчком мыши / подсказкой.
В настоящее время ряд пользователей расширяют холст «обезглавленных» изображений вверх, примерно заполняют область головы и используют img2img для завершения неудачного рендеринга.
Эффективная маскировка с учетом контекста
Маскировка может быть ужасно случайным делом в Stable Diffusion, в зависимости от рассматриваемого форка или версии. Часто там, где вообще возможно нарисовать связную маску, указанная область оказывается закрашенной содержимым, которое не принимает во внимание весь контекст изображения.
Однажды я замаскировал роговицы изображения лица и предоставил подсказку. 'голубые глаза' как маска, написанная краской, — только чтобы обнаружить, что смотрю двумя вырезанными человеческими глазами на далекое изображение волка неземного вида. Наверное, мне повезло, что это был не Фрэнк Синатра.
Также возможно семантическое редактирование определение шума который создает изображение в первую очередь, что позволяет пользователю обращаться к определенным структурным элементам в рендеринге, не мешая остальной части изображения:

Изменение одного элемента изображения без традиционного маскирования и без изменения соседнего содержимого путем определения шума, из-за которого изображение изначально возникло, и устранения его частей, которые внесли свой вклад в целевую область. Источник: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Этот метод основан на К-диффузионный пробоотборник.
Семантические фильтры для физиологических глупостей
Как мы упоминали ранее, Stable Diffusion может часто добавлять или удалять конечности, в основном из-за проблем с данными и недостатков в аннотациях, которые сопровождают изображения, которые его обучили.

Как и тот заблудший ребенок, который высунул язык на школьной групповой фотографии, биологические злодеяния Stable Diffusion не всегда сразу очевидны, и вы, возможно, разместили в Instagram свой последний шедевр искусственного интеллекта, прежде чем заметите дополнительные руки или расплавленные конечности.
Исправить такие ошибки настолько сложно, что было бы полезно, если бы полноразмерное приложение Stable Diffusion содержало какую-то систему распознавания анатомических данных, которая использовала бы семантическую сегментацию для вычисления того, имеет ли входящее изображение серьезные анатомические дефекты (как на изображении выше). ) и отбрасывает его в пользу нового рендера, прежде чем представить его пользователю.

Конечно, вы можете захотеть изобразить богиню Кали или Доктора Осьминога или даже спасти нетронутую часть изображения с пораженными конечностями, поэтому эта функция должна быть необязательным переключателем.
Если бы пользователи могли терпеть аспект телеметрии, такие осечки могли бы даже передаваться анонимно в рамках коллективных усилий федеративного обучения, что может помочь будущим моделям улучшить их понимание анатомической логики.
Автоматическое улучшение лица на основе LAION
Как я отметил в своем предыдущий вид из трех вещей, которые Stable Diffusion может решить в будущем, не следует оставлять исключительно какой-либо версии GFPGAN попытки «улучшить» визуализированные лица при рендеринге первого экземпляра.
«Улучшения» GFPGAN носят ужасно общий характер, часто подрывают личность изображенного человека и работают исключительно с лицом, которое обычно плохо визуализировалось, поскольку ему уделялось не больше времени или внимания на обработку, чем любой другой части изображения.
Поэтому профессиональная стандартная программа для стабильной диффузии должна уметь распознавать лицо (со стандартной и относительно легкой библиотекой, такой как YOLO), использовать всю доступную мощность графического процессора для его повторного рендеринга и либо смешивать улучшенное лицо с исходный полнотекстовый рендер или сохраните его отдельно для ручной перекомпоновки. В настоящее время это довольно «ручная» операция.
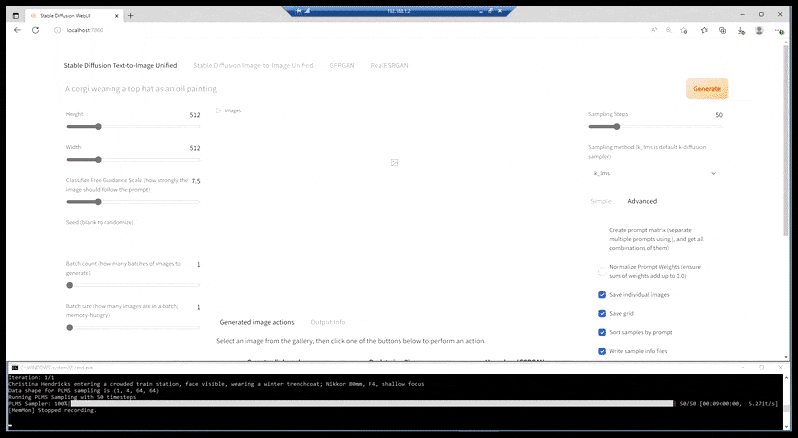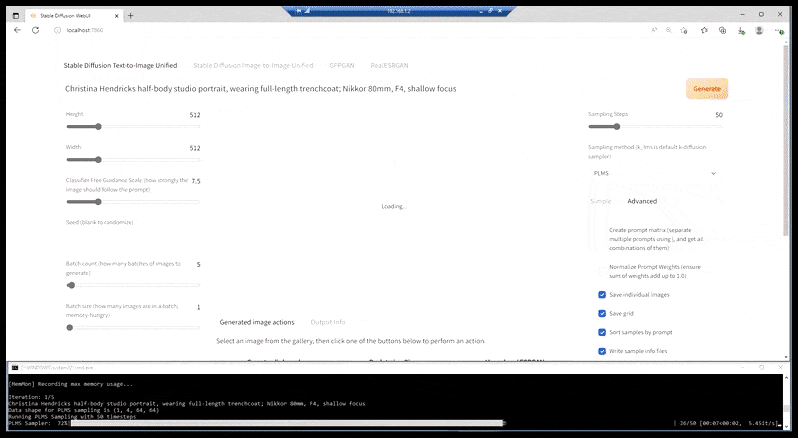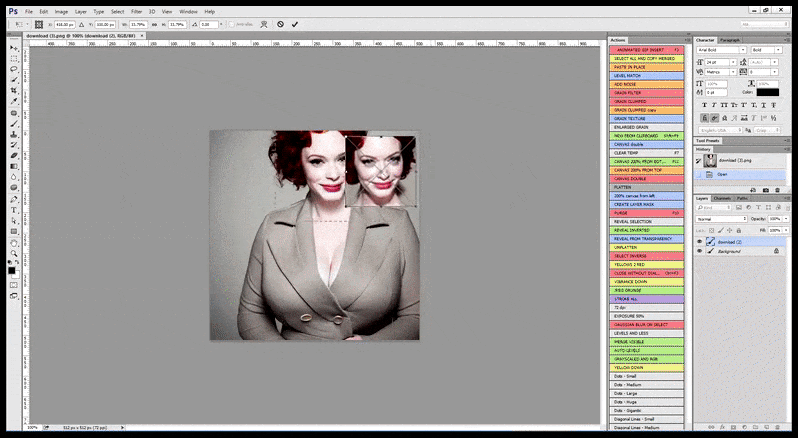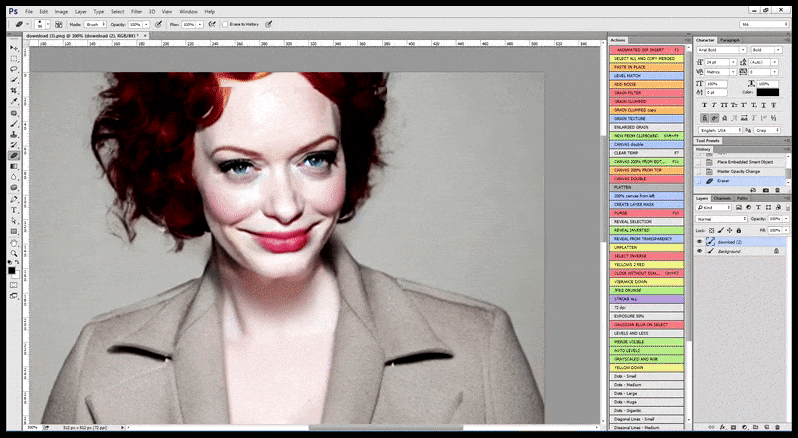
В тех случаях, когда Stable Diffusion был обучен на достаточном количестве изображений знаменитости, можно сосредоточить всю мощность GPU на последующем рендеринге исключительно лица визуализируемого изображения, что обычно является заметным улучшением — и, в отличие от GFPGAN , использует информацию из данных, обученных LAION, а не просто корректирует отображаемые пиксели.
Поиски в приложении LAION
Поскольку пользователи начали понимать, что поиск концепций, людей и тем в базе данных LAION может оказаться полезным для более эффективного использования Stable Diffusion, было создано несколько онлайн-исследователей LAION, включая haveibeentrained.com.

Функция поиска на сайте haveibeentrained.com позволяет пользователям исследовать изображения, лежащие в основе стабильной диффузии, и узнавать, были ли объекты, люди или идеи, которые они хотели бы извлечь из системы, обучены ей. Такие системы также полезны для обнаружения смежных объектов, таких как группировка знаменитостей или «следующая идея», которая следует за текущей. Источник: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Хотя такие веб-базы данных часто раскрывают некоторые теги, сопровождающие изображения, процесс обобщение то, что происходит во время обучения модели, означает, что маловероятно, что какое-либо конкретное изображение может быть вызвано с использованием его тега в качестве подсказки.
Кроме того, удаление «стоп-слова» а практика стемминга и лемматизации в обработке естественного языка означает, что многие отображаемые фразы были разделены или опущены до того, как они были обучены стабильной диффузии.
Тем не менее, то, как эстетические группы объединяются вместе в этих интерфейсах, может многому научить конечного пользователя логике (или, возможно, «личности») Stable Diffusion и оказаться помощником в улучшении создания изображений.
Заключение
Есть много других функций, которые я хотел бы видеть в полной реализации Stable Diffusion для настольных компьютеров, например, встроенный анализ изображений на основе CLIP, который меняет стандартный процесс Stable Diffusion и позволяет пользователю извлекать фразы и слова, которые система будет естественным образом ассоциироваться с исходным изображением или рендером.
Кроме того, истинное масштабирование на основе тайлов было бы желанным дополнением, поскольку ESRGAN является почти таким же грубым инструментом, как и GFPGAN. К счастью, планируется интегрировать txt2imghd реализация GOBIG быстро делает это реальностью во всех дистрибутивах, и это кажется очевидным выбором для настольной итерации.
Некоторые другие популярные запросы от сообществ Discord меня интересуют меньше, такие как встроенные словари подсказок и применимые списки исполнителей и стилей, хотя блокнот в приложении или настраиваемый словарь фраз казались бы логичным дополнением.
Точно так же текущие ограничения ориентированной на человека анимации в Stable Diffusion, хотя и были запущены CogVideo и различными другими проектами, остаются невероятно зарождающимися и зависят от предшествующих исследований временных априорных данных, касающихся подлинного человеческого движения.
На данный момент видео Stable Diffusion строго психоделики, хотя у него может быть гораздо более яркое ближайшее будущее в виде дипфейковых кукол, благодаря EbSynth и другим относительно зарождающимся инициативам по преобразованию текста в видео (и стоит отметить отсутствие синтезированных или «измененных» людей в «Подиуме»). последний рекламный ролик).
Еще одна ценная функциональность — прозрачная передача Photoshop, давно установленная в редакторе текстур Cinema4D среди других подобных реализаций. Благодаря этому можно легко перемещать изображения между приложениями и использовать каждое приложение для выполнения преобразований, в которых оно превосходно.
Наконец, и, возможно, это наиболее важно, полнофункциональная программа Stable Diffusion должна иметь возможность не только легко переключаться между контрольными точками (то есть версиями базовой модели, на которой работает система), но также должна иметь возможность обновлять пользовательские текстовые инверсии, которые работали. с предыдущими официальными выпусками модели, но в противном случае может быть нарушена более поздними версиями модели (как указали разработчики в официальном Discord).
По иронии судьбы, Adobe, организация, которая имеет наилучшие возможности для создания такой мощной и интегрированной матрицы инструментов для Stable Diffusion, так сильно объединилась с Инициатива аутентичности контента что это может показаться ретроградным пиар-шагом для компании — если только она не остановит генеративные возможности Stable Diffusion так же тщательно, как OpenAI сделала с DALL-E 2, и вместо этого не позиционирует его как естественную эволюцию своих значительных запасов в стоковой фотографии.
Впервые опубликовано 15 сентября 2022 г.















