IA 101
Ce este învățarea prin întărire?
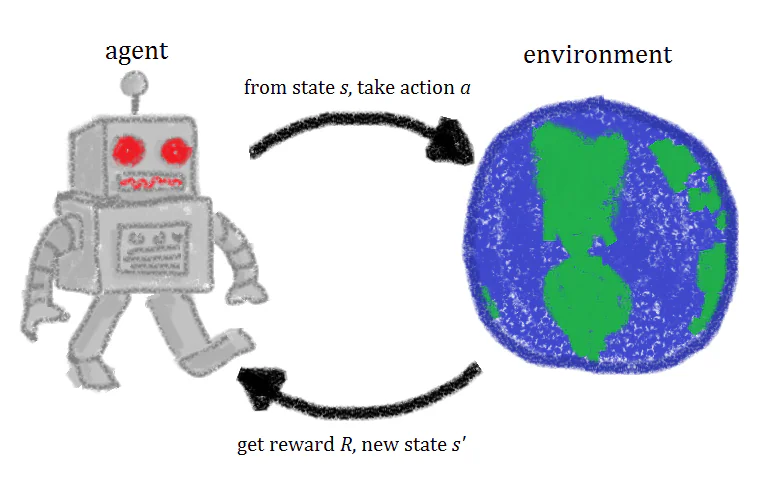
Ce este învățarea prin întărire?
În mod simplu, învățarea prin întărire este o tehnică de învățare a mașinilor care implică antrenarea unui agent de inteligență artificială prin repetiția acțiunilor și a recompenselor asociate. Un agent de învățare prin întărire experimentează într-un mediu, efectuează acțiuni și primește recompense atunci când acțiunile corecte sunt efectuate. În timp, agentul învață să efectueze acțiunile care vor maximiza recompensa sa. Aceasta este o definiție rapidă a învățării prin întărire, dar o examinare mai atentă a conceptelor din spatele învățării prin întărire vă va ajuta să obțineți o înțelegere mai bună și mai intuitivă a acesteia.
Termenul “învățare prin întărire” este adaptat din conceptul de întărire în psihologie. Din acest motiv, să luăm un moment pentru a înțelege conceptul psihologic de întărire. În sens psihologic, termenul de întărire se referă la ceva care crește probabilitatea ca o anumită reacție/acțiune să aibă loc. Acest concept de întărire este o idee centrală a teoriei condiționării operante, propusă inițial de psihologul B.F. Skinner. În acest context, întărirea este orice lucru care face ca frecvența unei anumite comportări să crească. Dacă ne gândim la posibile întăriri pentru oameni, acestea pot fi lucruri precum laudă, o creștere salarială, dulciuri și activități distractive.
În sensul tradițional, psihologic, există două tipuri de întărire. Există întărire pozitivă și întărire negativă. Întărirea pozitivă constă în adăugarea a ceva pentru a crește o comportare, precum oferirea unui tratament câinelui atunci când se comportă bine. Întărirea negativă implică înlăturarea unui stimul pentru a provoca o comportare, precum oprirea zgomotului puternic pentru a atrage o pisică sperioasă.
Întărire pozitivă și negativă
Întărirea pozitivă crește frecvența unei comportări, în timp ce întărirea negativă scade frecvența. În general, întărirea pozitivă este cel mai frecvent tip de întărire utilizat în învățarea prin întărire, deoarece ajută modelele să maximizeze performanța la o anumită sarcină. Nu numai că întărirea pozitivă conduce la schimbări mai durabile, dar aceste schimbări pot deveni modele consistente și pot persista pentru perioade lungi de timp.
În contrast, deși întărirea negativă face, de asemenea, o comportare mai probabilă, este utilizată pentru menținerea unui standard de performanță minim, mai degrabă decât atingerea performanței maxime a modelului. Întărirea negativă în învățarea prin întărire poate ajuta la menținerea modelului departe de acțiuni nedorite, dar nu poate face ca modelul să exploreze acțiuni dorite.
Antrenarea unui agent de învățare prin întărire
Atunci când un agent de învățare prin întărire este antrenat, există patru ingrediente sau stări utilizate în antrenare: stări inițiale (Stare 0), nouă stare (Stare 1), acțiuni și recompense.
Imaginați-vă că antrenăm un agent de învățare prin întărire pentru a juca un joc de platformă video, în care scopul inteligenței artificiale este de a ajunge la capătul nivelului prin deplasarea spre dreapta pe ecran. Starea inițială a jocului este extrasă din mediu, ceea ce înseamnă că primul cadru al jocului este analizat și dat modelului. Pe baza acestei informații, modelul trebuie să decidă asupra unei acțiuni.
În fazele inițiale de antrenare, aceste acțiuni sunt aleatorii, dar pe măsură ce modelul este întărit, anumite acțiuni vor deveni mai frecvente. După ce acțiunea este efectuată, mediul jocului este actualizat și se creează o nouă stare sau cadru. Dacă acțiunea efectuată de agent a produs un rezultat dorit, să zicem în acest caz că agentul este încă viu și nu a fost lovit de un dușman, se oferă o recompensă agentului și devine mai probabil să efectueze aceeași acțiune în viitor.
Acest sistem de bază este repetat constant, apărând din nou și din nou, și de fiecare dată agentul încearcă să învețe puțin mai mult și să maximizeze recompensa sa.
Sarcini episodice versus sarcini continue
Sarcinile de învățare prin întărire pot fi de obicei încadrate în una dintre două categorii diferite: sarcini episodice și sarcini continue.
Sarcinile episodice efectuează bucla de învățare/antrenare și îmbunătățesc performanța până când sunt îndeplinite anumite criterii de sfârșit și antrenarea este încheiată. Într-un joc, acest lucru ar putea fi ajungerea la capătul nivelului sau căderea într-un pericol, cum ar fi cuie. În contrast, sarcinile continue nu au criterii de sfârșit, efectuând practic antrenarea pe termen nelimitat, până când inginerul alege să încheie antrenarea.
Monte Carlo versus diferență temporală
Există două moduri principale de învățare, sau antrenare, a unui agent de învățare prin întărire. În abordarea Monte Carlo, recompensele sunt oferite agentului (scorul său este actualizat) numai la sfârșitul episoadei de antrenare. Altfel spus, numai atunci când condiția de sfârșit este atinsă, modelul învață cât de bine a performant. Apoi, poate utiliza această informație pentru a se actualiza și, atunci când următoarea rundă de antrenare este începută, va răspunde în conformitate cu noile informații.
Metoda diferenței temporale se diferențiază de metoda Monte Carlo prin faptul că estimarea valorii, sau estimarea scorului, este actualizată pe parcursul episoadei de antrenare. Odată ce modelul avansează la următorul pas de timp, valorile sunt actualizate.
Explorare versus exploatare
Antrenarea unui agent de învățare prin întărire este un act de echilibru, implicând echilibrarea a două metrici diferite: explorare și exploatare.
Explorarea este actul de colectare a mai multor informații despre mediul înconjurător, în timp ce exploatarea constă în utilizarea informațiilor deja cunoscute despre mediu pentru a câștiga puncte de recompensă. Dacă un agent explorează și nu exploatează niciodată mediul, acțiunile dorite nu vor fi niciodată efectuate. Pe de altă parte, dacă agentul exploatează și nu explorează niciodată, agentul va învăța să efectueze doar o acțiune și nu va descoperi alte strategii posibile de a câștiga recompense. Prin urmare, echilibrarea explorării și exploatarea este critică atunci când se creează un agent de învățare prin întărire.
Cazuri de utilizare pentru învățarea prin întărire
Învățarea prin întărire poate fi utilizată într-o varietate largă de roluri și este cel mai bine adaptată pentru aplicații care necesită automatizarea sarcinilor.
Automatizarea sarcinilor care trebuie efectuate de roboți industriali este o zonă în care învățarea prin întărire se dovedește utilă. Învățarea prin întărire poate fi utilizată și pentru probleme precum mineritul de text, crearea de modele care pot rezuma corpuri lungi de text. Cercetătorii experimentează, de asemenea, cu utilizarea învățării prin întărire în domeniul sănătății, cu agenți de întărire care gestionează sarcini precum optimizarea politicilor de tratament. Învățarea prin întărire poate fi utilizată, de asemenea, pentru a personaliza materialul educațional pentru studenți.
Rezumat al învățării prin întărire
Învățarea prin întărire este o metodă puternică de construire a agenților de inteligență artificială care poate duce la rezultate impresionante și, uneori, surprinzătoare. Antrenarea unui agent prin învățarea prin întărire poate fi complexă și dificilă, deoarece necesită multe iterații de antrenare și un echilibru delicat al dicotomiei explorare/exploatare. Cu toate acestea, dacă este reușită, un agent creat cu învățarea prin întărire poate efectua sarcini complexe într-o varietate largă de medii diferite.








