Inteligência artificial
Rumo a humanos de IA em tempo real com renderização de lumigrafia neural

Apesar da atual onda de interesse em Neural Radiance Fields (NeRF), uma tecnologia capaz de criar ambientes e objetos 3D gerados por IA, essa nova abordagem para a tecnologia de síntese de imagens ainda requer muito tempo de treinamento e carece de uma implementação que permita interfaces altamente responsivas em tempo real.
No entanto, uma colaboração entre alguns nomes impressionantes da indústria e da academia oferece uma nova abordagem a esse desafio (conhecido genericamente como Novel View Synthesis, ou NVS).
A pesquisa papel, intitulado Renderização de Lumigrafia Neural, afirma uma melhoria no estado da arte de cerca de duas ordens de magnitude, representando vários passos em direção à renderização de CG em tempo real por meio de pipelines de aprendizado de máquina.

A Renderização Neural Lumigraph (à direita) oferece melhor resolução de artefatos de mesclagem e tratamento aprimorado de oclusão em relação aos métodos anteriores. fonte.
Embora os créditos para o artigo cite apenas a Universidade de Stanford e a empresa de tecnologia de exibição holográfica Raxium (atualmente operando em modo furtivo), os colaboradores incluem um aprendizado de máquina principal no Google, um computador cientista na Adobe, e o CTO at Arquivo de Histórias (que fez manchetes recentemente com uma versão AI de William Shatner).
Em relação à recente blitz publicitária de Shatner, o StoryFile parece estar empregando NLR em seu novo processo para a criação de entidades interativas geradas por IA com base nas características e narrativas de pessoas individuais.
O StoryFile prevê o uso dessa tecnologia em exibições de museus, narrativas interativas on-line, exibições holográficas, realidade aumentada (AR) e documentação de patrimônio - e também parece estar de olho em possíveis novas aplicações de NLR em entrevistas de recrutamento e aplicativos de namoro virtual:

Usos propostos a partir de um vídeo online do StoryFile. Fonte: https://www.youtube.com/watch?v=2K9J6q5DqRc
Captura volumétrica para novas interfaces de síntese de visualização e vídeo
O princípio da captura volumétrica, em toda a gama de artigos que estão se acumulando sobre o assunto, é a ideia de tirar fotos ou vídeos de um objeto e usar o aprendizado de máquina para "preencher" os pontos de vista que não foram cobertos pelo conjunto original de câmeras.
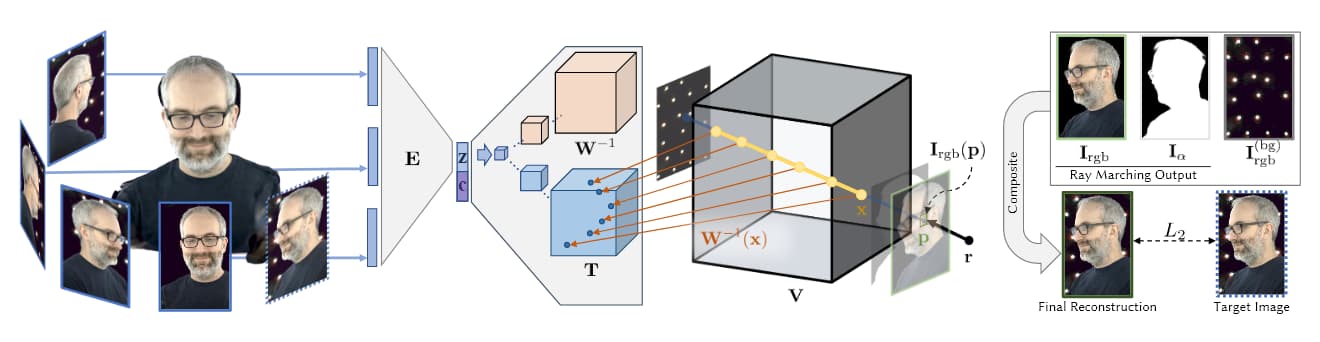
Fonte: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
Na imagem acima, retirada da pesquisa de IA do Facebook AI 2019 (veja abaixo), vemos os quatro estágios da captura volumétrica: várias câmeras obtêm imagens/filmagens; a arquitetura do codificador/decodificador (ou outras arquiteturas) calcula e concatena a relatividade das visualizações; os algoritmos de ray-marching calculam a voxels (ou outras unidades geométricas espaciais XYZ) de cada ponto no espaço volumétrico; e (nos artigos mais recentes) o treinamento ocorre para sintetizar uma entidade completa que pode ser manipulada em tempo real.
É essa fase de treinamento muitas vezes extensa e com muitos dados que, até o momento, manteve a síntese de novas visualizações fora do domínio da captura em tempo real ou altamente responsiva.
O fato de o Novel View Synthesis fazer um mapa 3D completo de um espaço volumétrico significa que é relativamente trivial unir esses pontos em uma malha tradicional gerada por computador, capturando e articulando efetivamente um humano CGI (ou qualquer outro objeto relativamente limitado) on- o voo.
Abordagens que usam NeRF dependem de nuvens de pontos e mapas de profundidade para gerar as interpolações entre os pontos de vista esparsos dos dispositivos de captura:

O NeRF pode gerar profundidade volumétrica por meio do cálculo de mapas de profundidade, em vez da geração de malhas CG. Fonte: https://www.youtube.com/watch?v=JuH79E8rdKc
Embora o NeRF seja capaz de cálculo de malhas, a maioria das implementações não usa isso para gerar cenas volumétricas.
Por outro lado, o renderizador diferenciável implícito (IDR) abordagem, publicado pelo Weizmann Institute of Science em outubro de 2020, depende da exploração de informações de malha 3D geradas automaticamente a partir de matrizes de captura:

Exemplos de capturas IDR transformadas em malhas CGI interativas. Fonte: https://www.youtube.com/watch?v=C55y7RhJ1fE
Embora o NeRF não tenha a capacidade do IDR para estimativa de forma, o IDR não pode corresponder à qualidade de imagem do NeRF e ambos exigem recursos extensos para treinar e reunir (embora as inovações recentes no NeRF sejam começo para resolver isso).

Equipamento de câmera personalizado da NLR com 16 câmeras GoPro HERO7 e 6 câmeras Back-Bone H7PRO centrais. Para renderização em "tempo real", elas operam a no mínimo 60 fps. Fonte: https://arxiv.org/pdf/2103.11571.pdf
Em vez disso, a Renderização Neural Lumigraph utiliza SIRENE (Redes de Representação Senoidal) para incorporar os pontos fortes de cada abordagem em sua própria estrutura, cujo objetivo é gerar uma saída diretamente utilizável em pipelines gráficos em tempo real existentes.
O SIREN tem sido utilizado para implementações semelhantes no ano passado, e agora representa um chamada de API popular para colabs amadores em comunidades de síntese de imagens; no entanto, a inovação da NLR é aplicar SIRENs à supervisão de imagens multivisualização bidimensionais, o que é problemático devido à extensão em que SIREN produz uma saída superajustada em vez de generalizada.
Depois que a malha CG é extraída das imagens da matriz, a malha é rasterizada via OpenGL e as posições dos vértices da malha mapeadas para os pixels apropriados, após o que a mistura dos vários mapas contribuintes é calculada.
A malha resultante é mais generalizada e representativa que a do NeRF (veja a imagem abaixo), requer menos cálculos e não aplica detalhes excessivos a áreas (como a pele lisa do rosto) que não podem se beneficiar dela:

Fonte: https://arxiv.org/pdf/2103.11571.pdf
Do lado negativo, o NLR ainda não tem capacidade de iluminação dinâmica ou reacendimento, e a saída é restrita a mapas de sombra e outras considerações de iluminação obtidas no momento da captura. Os pesquisadores pretendem abordar isso em trabalhos futuros.
Além disso, o artigo admite que as formas geradas pelo NLR não são tão precisas quanto algumas abordagens alternativas, como Seleção de visualização em pixels para estéreo multivisualização não estruturada, ou a pesquisa do Weizmann Institute mencionada anteriormente.
A ascensão da síntese volumétrica de imagens
A ideia de criar entidades 3D a partir de uma série limitada de fotos com redes neurais é anterior ao NeRF, com artigos visionários que datam de 2007 ou antes. Em 2019, o departamento de pesquisa de IA do Facebook produziu um artigo de pesquisa seminal, Volumes neurais: aprendendo volumes renderizáveis dinâmicos a partir de imagens, que primeiro permitiu interfaces responsivas para humanos sintéticos gerados por captura volumétrica baseada em aprendizado de máquina.

A pesquisa de 2019 do Facebook permitiu a criação de uma interface de usuário responsiva para uma pessoa volumétrica. Fonte: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/












