AI 101
Co to jest Twierdzenie Bayesa?
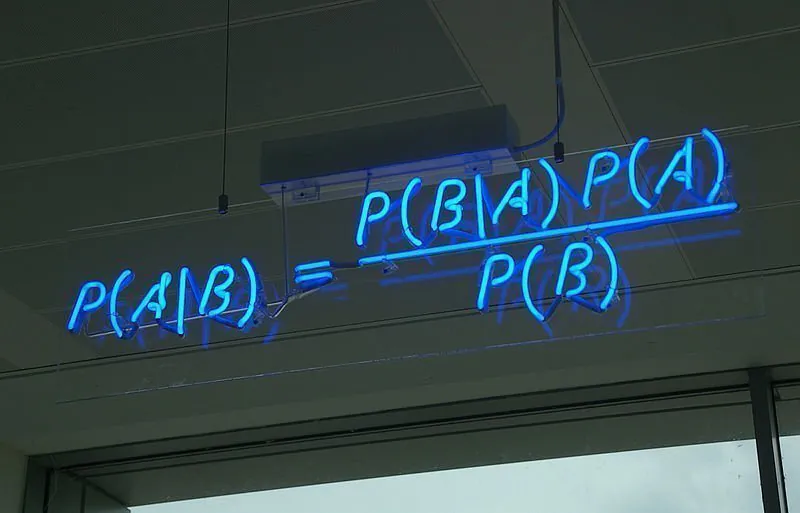
Jeśli uczyłeś się o nauce o danych lub uczeniu maszynowym, istnieje duże prawdopodobieństwo, że słyszałeś już termin „Twierdzenie Bayesa” lub „klasyfikator Bayesa”. Te pojęcia mogą być trochę mylące, szczególnie jeśli nie jesteś przyzwyczajony do myślenia o prawdopodobieństwie z tradycyjnej, częstotliwościowej perspektywy statystyki. Artykuł ten będzie próbował wyjaśnić zasady za Twierdzeniem Bayesa i jak jest ono stosowane w uczeniu maszynowym.
Co to jest Twierdzenie Bayesa?
Twierdzenie Bayesa jest metodą obliczania prawdopodobieństwa warunkowego. Tradycyjna metoda obliczania prawdopodobieństwa warunkowego (prawdopodobieństwa, że jedno zdarzenie występuje pod warunkiem wystąpienia innego zdarzenia) polega na użyciu formuły prawdopodobieństwa warunkowego, obliczaniu wspólnego prawdopodobieństwa zdarzenia pierwszego i zdarzenia drugiego występujących w tym samym czasie, a następnie dzieleniu go przez prawdopodobieństwo wystąpienia zdarzenia drugiego. Jednak prawdopodobieństwo warunkowe można również obliczyć w nieco inny sposób, używając Twierdzenia Bayesa.
Podczas obliczania prawdopodobieństwa warunkowego za pomocą Twierdzenia Bayesa, wykonujesz następujące kroki:
- Określ prawdopodobieństwo, że warunek B jest prawdziwy, zakładając, że warunek A jest prawdziwy.
- Określ prawdopodobieństwo, że zdarzenie A jest prawdziwe.
- Pomnóż oba prawdopodobieństwa.
- Podziel przez prawdopodobieństwo wystąpienia zdarzenia B.
Oznacza to, że wzór na Twierdzenie Bayesa można wyrazić w następujący sposób:
P(A|B) = P(B|A)*P(A) / P(B)
Obliczanie prawdopodobieństwa warunkowego w ten sposób jest szczególnie przydatne, gdy odwrotne prawdopodobieństwo warunkowe można łatwo obliczyć lub gdy obliczanie wspólnego prawdopodobieństwa byłoby zbyt trudne.
Przykład Twierdzenia Bayesa
Może to być łatwiejsze do zinterpretowania, jeśli spędzimy trochę czasu na przykładzie przykładu tego, jak można zastosować rozumowanie Bayesa i Twierdzenie Bayesa. Załóżmy, że grałeś w prostej grze, w której wielu uczestników opowiada ci historię, a ty musisz określić, który z uczestników kłamie. Wypełnijmy równanie Twierdzenia Bayesa zmiennymi w tym hipotetycznym scenariuszu.
Staramy się przewidzieć, czy każdy z uczestników kłamie, czy mówi prawdę, więc jeśli jest trzech graczy poza tobą, zmienne kategorialne można wyrazić jako A1, A2 i A3. Dowód kłamstwa/powiadania prawdy to ich zachowanie. Podobnie jak w pokera, szukałbyś pewnych „sygnałów” świadczących o tym, że osoba kłamie, i używałbyś ich jako informacji, aby poinformować swoją odpowiedź. Lub jeśli byłoby ci wolno ich przesłuchać, byłoby to dowód, że ich historia nie jest spójna. Możemy przedstawić dowód, że osoba kłamie, jako B.
Aby być jasnym, staramy się przewidzieć Prawdopodobieństwo (A kłamie/mówi prawdę|dane dowody ich zachowania). Chcemy określić prawdopodobieństwo B za A, czyli prawdopodobieństwo, że ich zachowanie wystąpiłoby pod warunkiem, że osoba naprawdę kłamie lub mówi prawdę. Staramy się określić, pod jakimi warunkami zachowanie, które widzimy, miałoby najwięcej sensu. Jeśli istnieją trzy zachowania, których jesteś świadkiem, wykonujesz obliczenie dla każdego zachowania. Na przykład P(B1, B2, B3 * A). Wykonujesz to dla każdego wystąpienia A/dla każdej osoby w grze poza tobą. To jest ta część równania powyżej:
P(B1, B2, B3,|A) * P|A
W końcu dzielimy to przez prawdopodobieństwo B.
Jeśli otrzymalibyśmy jakiekolwiek dowody dotyczące rzeczywistych prawdopodobieństw w tym równaniu, odtworzylibyśmy nasz model prawdopodobieństwa, biorąc pod uwagę nowe dowody. Nazywa się to aktualizacją naszych a priori, ponieważ aktualizujemy nasze założenia dotyczące wcześniejszego prawdopodobieństwa wystąpienia zaobserwowanych zdarzeń.
Zastosowania w uczeniu maszynowym Twierdzenia Bayesa
Najczęstszym zastosowaniem Twierdzenia Bayesa w uczeniu maszynowym jest w postaci algorytmu Naive Bayes.
Naive Bayes jest używany do klasyfikacji zarówno binarnych, jak i wieloklasowych zbiorów danych. Naive Bayes otrzymał swoją nazwę, ponieważ wartości przypisane do dowodów/cech świadków – B w P(B1, B2, B3 * A) – są zakładane jako niezależne od siebie. Zakłada się, że te atrybuty nie wpływają na siebie, aby uprościć model i umożliwić obliczenia, zamiast próbować obliczyć relacje między każdym z atrybutów. Pomimo tego uproszczonego modelu, Naive Bayes ma tendencję do dobrze radzenia sobie jako algorytm klasyfikacji, nawet gdy to założenie prawdopodobnie nie jest prawdziwe (co jest większości czasu).
Istnieją również powszechnie używane warianty klasyfikatora Naive Bayes, takie jak Multinomial Naive Bayes, Bernoulli Naive Bayes i Gaussian Naive Bayes.
Multinomial Naive Bayes algorytmy są często używane do klasyfikacji dokumentów, ponieważ są skuteczne w interpretowaniu częstotliwości słów w dokumencie.
Bernoulli Naive Bayes działa podobnie do Multinomial Naive Bayes, ale przewidywania wydawane przez algorytm są wartościami logicznymi. Oznacza to, że podczas przewidywania klasy wartości będą binarne, tak lub nie. W dziedzinie klasyfikacji tekstu, algorytm Bernoulli Naive Bayes przypisuje parametry tak lub nie, w zależności od tego, czy słowo jest znalezione w dokumencie.
Jeśli wartości predyktorów/cech nie są dyskretne, ale są ciągłe, Gaussian Naive Bayes można użyć. Zakłada się, że wartości ciągłych cech zostały wybrane z rozkładu normalnego.












