
Artificial Intelligence
InstructIR: Wysokiej jakości przywracanie obrazu zgodnie z instrukcjami człowieka

Obraz może wiele przekazać, ale może być również zniekształcony przez różne problemy, takie jak rozmycie w ruchu, zamglenie, szum i niski zakres dynamiki. Problemy te, powszechnie określane jako pogorszenie widzenia komputerowego na niskim poziomie, mogą wynikać z trudnych warunków środowiskowych, takich jak upał lub deszcz, lub z ograniczeń samej kamery. Przywrócenie obrazu stanowi główne wyzwanie w dziedzinie wizji komputerowej, polegające na odzyskaniu wysokiej jakości, czystego obrazu z obrazu wykazującego taką degradację. Przywracanie obrazu jest złożone, ponieważ może istnieć wiele rozwiązań przywracania dowolnego obrazu. Niektóre podejścia skupiają się na konkretnych degradacjach, takich jak redukcja szumu lub usuwanie rozmycia lub zamglenia.
Chociaż metody te mogą dawać dobre wyniki w przypadku konkretnych problemów, często trudno jest im uogólnić różne typy degradacji. Wiele frameworków wykorzystuje ogólną sieć neuronową do szerokiego zakresu zadań przywracania obrazu, ale każda z tych sieci jest szkolona osobno. Zapotrzebowanie na różne modele dla każdego rodzaju degradacji sprawia, że podejście to jest kosztowne obliczeniowo i czasochłonne, co prowadzi do skupienia się w najnowszych opracowaniach na modelach renowacji typu „wszystko w jednym”. Modele te wykorzystują pojedynczy, głęboko ślepy model przywracania, który uwzględnia wiele poziomów i typów degradacji, często wykorzystując podpowiedzi lub wektory wskazówek dotyczące degradacji w celu zwiększenia wydajności. Chociaż modele All-In-One zazwyczaj dają obiecujące wyniki, nadal stoją przed wyzwaniami związanymi z problemami odwrotnymi.
InstructIR reprezentuje przełomowe podejście w tej dziedzinie, będąc pierwszym przywracanie obrazu ramy zaprojektowane w celu prowadzenia modelu renowacji za pomocą instrukcji pisanych przez człowieka. Może przetwarzać podpowiedzi w języku naturalnym, aby odzyskać wysokiej jakości obrazy z obrazów zdegradowanych, biorąc pod uwagę różne typy degradacji. InstructIR wyznacza nowy standard wydajności w szerokim spektrum zadań przywracania obrazu, w tym usuwania drenażu, usuwania szumów, usuwania zamgleń, usuwania rozmycia i ulepszania obrazów przy słabym oświetleniu.
Celem tego artykułu jest szczegółowe omówienie frameworku InstructIR, a także zbadanie mechanizmu, metodologii i architektury frameworku wraz z jego porównaniem z najnowocześniejszymi frameworkami do generowania obrazów i wideo. Więc zacznijmy.
InstructIR: Wysokiej jakości przywracanie obrazu
Przywracanie obrazu jest podstawowym problemem w widzeniu komputerowym, ponieważ ma na celu odzyskanie czystego obrazu o wysokiej jakości z obrazu wykazującego degradację. W obrazie komputerowym niskiego poziomu degradacje to termin używany do przedstawienia nieprzyjemnych efektów obserwowanych na obrazie, takich jak rozmycie w ruchu, zamglenie, szum, niski zakres dynamiki i inne. Powodem, dla którego przywracanie obrazu jest złożonym i odwrotnym wyzwaniem, jest to, że może istnieć wiele różnych rozwiązań przywracania dowolnego obrazu. Niektóre frameworki skupiają się na konkretnych degradacjach, takich jak redukcja szumu instancji lub odszumianie obrazu, podczas gdy inne mogą skupiać się bardziej na usuwaniu rozmycia lub usuwania rozmycia lub usuwania zamglenia lub usuwania zamglenia.
Najnowsze metody głębokiego uczenia się wykazały lepszą i bardziej spójną wydajność w porównaniu z tradycyjnymi metodami przywracania obrazu. Te modele przywracania obrazu metodą głębokiego uczenia się proponują wykorzystanie sieci neuronowych opartych na transformatorach i konwolucyjnych sieciach neuronowych. Modele te można trenować niezależnie pod kątem różnorodnych zadań przywracania obrazu, a także posiadają zdolność wychwytywania lokalnych i globalnych interakcji między funkcjami oraz ulepszania ich, co zapewnia zadowalającą i stałą wydajność. Chociaż niektóre z tych metod mogą działać odpowiednio w przypadku określonych typów degradacji, zazwyczaj nie można ich dobrze ekstrapolować na różne typy degradacji. Co więcej, chociaż wiele istniejących frameworków wykorzystuje tę samą sieć neuronową do wielu zadań odtwarzania obrazu, każda formuła sieci neuronowej jest trenowana oddzielnie. Dlatego oczywiste jest, że stosowanie oddzielnego modelu neuronowego dla każdej możliwej degradacji jest niepraktyczne i czasochłonne, dlatego też najnowsze ramy przywracania obrazu koncentrują się na uniwersalnych serwerach proxy przywracania.
Modele przywracania obrazu typu „wszystko w jednym”, modele przywracania wielu degradacji lub wielozadaniowości zyskują popularność w dziedzinie wizji komputerowej, ponieważ są w stanie przywrócić wiele typów i poziomów degradacji obrazu bez konieczności szkolenia modeli niezależnie dla każdej degradacji . Modele przywracania obrazu typu „wszystko w jednym” wykorzystują pojedynczy model przywracania obrazu w trybie głębokiej ślepej próby, aby radzić sobie z różnymi typami i poziomami degradacji obrazu. Różne modele All-In-One wdrażają różne podejścia do prowadzenia niewidomego modelu w celu przywrócenia zdegradowanego obrazu, na przykład model pomocniczy do klasyfikacji degradacji lub wielowymiarowe wektory prowadzące lub podpowiedzi pomagające modelowi przywrócić różne rodzaje degradacji w obrębie obraz.
Mając to na uwadze, dochodzimy do tekstowej manipulacji obrazami, ponieważ została ona wdrożona w kilku frameworkach w ciągu ostatnich kilku lat do generowania tekstu na obraz i zadań edycji obrazu w oparciu o tekst. Modele te często wykorzystują podpowiedzi tekstowe do opisywania działań lub obrazów modele oparte na dyfuzji wygenerować odpowiednie obrazy. Główną inspiracją dla platformy InstructIR jest platforma InstructPix2Pix, która umożliwia modelowi edycję obrazu przy użyciu instrukcji użytkownika, które instruują modela, jakie działania ma wykonać, zamiast etykiet tekstowych, opisów lub podpisów obrazu wejściowego. W rezultacie użytkownicy mogą używać naturalnych tekstów pisanych, aby poinstruować modela, jakie działania ma wykonać, bez konieczności dostarczania przykładowych zdjęć lub dodatkowych opisów obrazów.
Opierając się na tych podstawach, platforma InstructIR jest pierwszym w historii modelem widzenia komputerowego, który wykorzystuje napisane przez człowieka instrukcje w celu przywrócenia obrazu i rozwiązania odwrotnych problemów. W przypadku podpowiedzi w języku naturalnym model InstructIR może odzyskiwać obrazy o wysokiej jakości z ich zdegradowanych odpowiedników, a także uwzględnia wiele typów degradacji. Środowisko InstructIR zapewnia najnowocześniejszą wydajność w szerokiej gamie zadań przywracania obrazu, w tym usuwanie szumów, usuwanie zamgleń, usuwanie rozmycia i ulepszanie obrazu przy słabym oświetleniu. W przeciwieństwie do istniejących prac, w których przywracanie obrazu odbywa się za pomocą wyuczonych wektorów prowadzących lub osadzania podpowiedzi, platforma InstructIR wykorzystuje surowe podpowiedzi użytkownika w formie tekstowej. Środowisko InstructIR umożliwia uogólnienie przywracania obrazów przy użyciu instrukcji pisanych przez człowieka, a pojedynczy, kompleksowy model zaimplementowany przez InstructIR obejmuje więcej zadań przywracania niż wcześniejsze modele. Poniższy rysunek przedstawia różnorodne próbki rekonstrukcji w środowisku InstructIR.

InstructIR: Metoda i architektura
W swej istocie środowisko InstructIR składa się z kodera tekstu i modelu obrazu. Model wykorzystuje platformę NAFNet, wydajny model przywracania obrazu, który jako model obrazu wykorzystuje architekturę U-Net. Co więcej, model implementuje techniki routingu zadań, aby skutecznie uczyć się wielu zadań przy użyciu jednego modelu. Poniższy rysunek ilustruje podejście do szkolenia i oceny w ramach InstructIR.

Czerpiąc inspirację z modelu InstructPix2Pix, platforma InstructIR wykorzystuje pisane przez człowieka instrukcje jako mechanizm kontrolny, ponieważ użytkownik nie musi podawać dodatkowych informacji. Instrukcje te zapewniają wyrazisty i przejrzysty sposób interakcji, umożliwiając użytkownikom wskazanie dokładnej lokalizacji i rodzaju degradacji obrazu. Co więcej, używanie podpowiedzi użytkownika zamiast podpowiedzi dotyczących ustalonej degradacji zwiększa użyteczność i zastosowania modelu, ponieważ może być on również używany przez użytkowników, którym brakuje wymaganej wiedzy specjalistycznej w danej dziedzinie. Aby wyposażyć platformę InstructIR w możliwość rozumienia różnorodnych podpowiedzi, model wykorzystuje GPT-4, duży model językowy do tworzenia różnorodnych żądań, z niejednoznacznymi i niejasnymi podpowiedziami usuwanymi w procesie filtrowania.
Koder tekstu
Koder tekstu jest używany w modelach językowych do mapowania podpowiedzi użytkownika na osadzony tekst lub reprezentację wektorową o stałym rozmiarze. Tradycyjnie, koder tekstu A Model KLIPS jest istotnym elementem generowania obrazów w oparciu o tekst i modeli manipulacji obrazami w oparciu o tekst w celu kodowania podpowiedzi użytkownika, ponieważ platforma CLIP przoduje w podpowiedziach wizualnych. Jednakże w większości przypadków monity użytkownika dotyczące degradacji funkcji zawierają niewiele treści wizualnych lub nie zawierają ich wcale, co sprawia, że duże kodery CLIP stają się bezużyteczne do takich zadań, ponieważ znacznie zmniejsza to wydajność. Aby rozwiązać ten problem, w środowisku InstructIR wybrano tekstowy koder zdań, który jest przeszkolony do kodowania zdań w znaczącej przestrzeni do osadzania. Kodery zdań są wstępnie przeszkolone na milionach przykładów, a mimo to są kompaktowe i wydajne w porównaniu z tradycyjnymi koderami tekstu opartymi na CLIP, a jednocześnie mają możliwość kodowania semantyki różnorodnych podpowiedzi użytkownika.
Wskazówki tekstowe
Głównym aspektem struktury InstructIR jest implementacja zakodowanych instrukcji jako mechanizmu kontrolnego modelu obrazu. Bazując na tym i zainspirowany routingiem zadań w przypadku uczenia się wielu zadań, platforma InstructIR proponuje blok konstrukcyjny instrukcji, czyli ICB, umożliwiający transformacje w modelu specyficzne dla zadania. Konwencjonalne routing zadań stosuje maski binarne specyficzne dla zadania do funkcji kanału. Ponieważ jednak środowisko InstructIR nie zna degradacji, technika ta nie jest wdrażana bezpośrednio. Co więcej, w przypadku cech obrazu i zakodowanych instrukcji środowisko InstructIR stosuje routing zadań i tworzy maskę przy użyciu warstwy liniowej aktywowanej za pomocą funkcji Sigmoid w celu wytworzenia zestawu wag w zależności od osadzania tekstu, uzyskując w ten sposób wymiar c na maska binarna kanału. Model dodatkowo ulepsza uwarunkowane funkcje za pomocą bloku NAFBlock i wykorzystuje blok NAFBlock i blok warunkowy instrukcji do warunkowania funkcji zarówno w bloku kodera, jak i bloku dekodera.
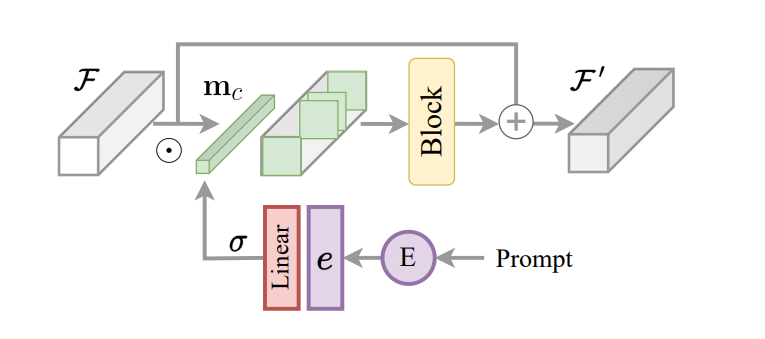
Chociaż struktura InstructIR nie warunkuje bezpośrednio filtrów sieci neuronowej, maska ułatwia modelowi wybór najbardziej odpowiednich kanałów na podstawie instrukcji obrazu i informacji.
InstructIR: wdrożenie i wyniki
Model InstructIR można kompleksowo przeszkolić, a model obrazu nie wymaga wstępnego szkolenia. Należy jedynie przeszkolić tekst osadzający projekcje i głowicę klasyfikacyjną. Koder tekstu jest inicjowany przy użyciu kodera BGE, kodera podobnego do BERT, który jest wstępnie szkolony na ogromnej ilości nadzorowanych i nienadzorowanych danych w celu ogólnego kodowania zdań. Struktura InstructIR wykorzystuje model NAFNet jako model obrazu, a architektura NAFNet składa się z 4-poziomowego dekodera-kodera z różną liczbą bloków na każdym poziomie. Model dodaje również 4 środkowe bloki pomiędzy koderem i dekoderem, aby jeszcze bardziej ulepszyć funkcje. Co więcej, zamiast łączyć połączenia pomijane, dekoder implementuje dodawanie, a model InstructIR implementuje tylko ICB lub blok warunkowy instrukcji do routingu zadań tylko w koderze i dekoderze. Idąc dalej, model InstructIR jest optymalizowany przy użyciu strat między przywróconym obrazem a czystym obrazem w rzeczywistości, a utrata entropii krzyżowej jest wykorzystywana do klasyfikacji zamiarów kodera tekstu. Model InstructIR wykorzystuje optymalizator AdamW o wielkości partii 32 i szybkości uczenia się 5e-4 dla prawie 500 epok, a także implementuje spadek szybkości uczenia się przy wyżarzaniu cosinusowym. Ponieważ model obrazu w środowisku InstructIR zawiera tylko 16 milionów parametrów, a wyuczonych parametrów projekcji tekstu jest tylko 100 tysięcy, środowisko InstructIR można łatwo trenować na standardowych procesorach graficznych, zmniejszając w ten sposób koszty obliczeniowe i zwiększając zastosowanie.
Wyniki wielokrotnej degradacji
W przypadku wielokrotnych degradacji i wielozadaniowych odbudów środowisko InstructIR definiuje dwie początkowe konfiguracje:
- Modele 3D dla modeli trzech degradacji w celu rozwiązania problemów związanych z degradacją, takich jak odmgławianie, odszumianie i odwadnianie.
- 5D dla pięciu modeli degradacji w celu rozwiązania problemów związanych z degradacją, takich jak odszumianie obrazu, ulepszenia przy słabym oświetleniu, usuwanie zamglenia, odszumianie i odwadnianie.
Wydajność modeli 5D przedstawiono w poniższej tabeli i porównano ją z najnowocześniejszymi modelami przywracania obrazu i modelami typu „wszystko w jednym”.

Jak można zaobserwować, platforma InstructIR z prostym modelem obrazu i zaledwie 16 milionami parametrów może z powodzeniem obsłużyć pięć różnych zadań przywracania obrazu dzięki wskazówkom opartym na instrukcjach i zapewnia konkurencyjne wyniki. Poniższa tabela przedstawia wydajność frameworka na modelach 3D, a wyniki są porównywalne z powyższymi wynikami.

Główną cechą platformy InstructIR jest przywracanie obrazu w oparciu o instrukcje, a poniższy rysunek przedstawia niesamowite możliwości modelu InstructIR w zakresie zrozumienia szerokiego zakresu instrukcji dotyczących danego zadania. Ponadto w przypadku instrukcji kontradyktoryjnej model InstructIR realizuje tożsamość, która nie jest wymuszona.

Final Thoughts
Przywracanie obrazu jest podstawowym problemem w widzeniu komputerowym, ponieważ ma na celu odzyskanie czystego obrazu o wysokiej jakości z obrazu wykazującego degradację. W obrazie komputerowym niskiego poziomu degradacje to termin używany do przedstawienia nieprzyjemnych efektów obserwowanych na obrazie, takich jak rozmycie w ruchu, zamglenie, szum, niski zakres dynamiki i inne. W tym artykule omówiliśmy InstructIR, pierwszą na świecie platformę przywracania obrazu, której celem jest prowadzenie modelu przywracania obrazu przy użyciu instrukcji napisanych przez człowieka. W przypadku podpowiedzi w języku naturalnym model InstructIR może odzyskiwać obrazy o wysokiej jakości z ich zdegradowanych odpowiedników, a także uwzględnia wiele typów degradacji. Środowisko InstructIR zapewnia najnowocześniejszą wydajność w szerokiej gamie zadań przywracania obrazu, w tym usuwanie szumów, usuwanie zamgleń, usuwanie rozmycia i ulepszanie obrazu przy słabym oświetleniu.















