AI 101
Hva er et beslutningstre?
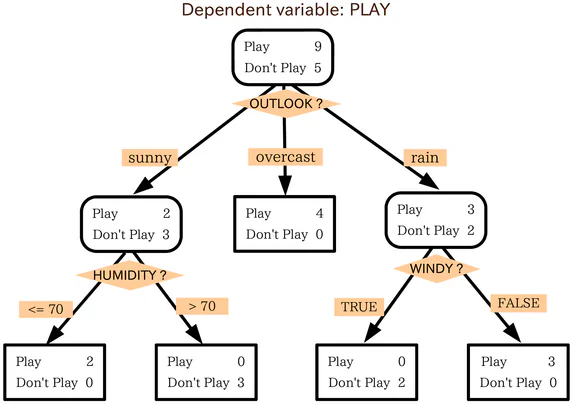
Hva er et beslutningstre?
Et beslutningstre er en nyttig maskinlæringsalgoritme som brukes til både regresjon og klassifiseringsoppgaver. Navnet «beslutningstre» kommer fra at algoritmen fortsetter å dele datasett ned i mindre og mindre deler til dataene er delt inn i enkeltinstanser, som deretter klassifiseres. Hvis du skulle visualisere resultater fra algoritmen, ville måten kategorier deles på ligne et tre med mange blader.
Dette er en rask definisjon av et beslutningstre, men la oss dykke dyptere inn i hvordan beslutningstre virker. Å ha en bedre forståelse av hvordan beslutningstre opererer, samt deres bruksområder, vil hjelpe deg med å vite når du skal bruke dem under dine maskinlæringsprosjekter.
Format for et beslutningstre
Et beslutningstre er mye likt en flytskjema. For å bruke et flytskjema starter du ved startpunktet eller roten av skjemaet og deretter, basert på hvordan du svarer på filterkriteriene for startnoden, flytter du til en av de neste mulige nodene. Denne prosessen gjentas til en sluttning nås.
Beslutningstre opererer på samme måte, med hver intern node i treet som en slags test/filterkriterium. Nodene på utsiden, endepunktene for treet, er merkelappene for datapunktet i question og de kalles «blader». Greinene som fører fra de interne nodene til den neste noden er egenskaper eller kombinasjoner av egenskaper. Reglene som brukes til å klassifisere datapunktene er stier som løper fra roten til bladene.

Algoritmer for beslutningstre
Beslutningstre opererer på en algoritmsk tilnærming som deler datasett opp i enkeltdata punkter basert på forskjellige kriterier. Disse delingene gjøres med forskjellige variabler eller forskjellige egenskaper i datasett. For eksempel, hvis målet er å bestemme om det er en hund eller en katt som beskrives av inndataegenskapene, kan variablene dataene deles på være ting som «klør» og «bjeffer».
Hva algoritmer brukes til å faktisk dele dataene inn i greiner og blader? Det finnes flere metoder som kan brukes til å dele et tre opp, men den vanligste metoden for deling er kanskje en teknikk som kalles «rekursiv binær deling». Når denne metoden for deling utføres, starter prosessen ved roten og antallet egenskaper i datasett representerer det mulige antallet mulige delinger. En funksjon brukes til å bestemme hvor mye nøyaktighet hver mulig deling vil koste, og delingen gjøres ved å bruke kriteriet som ofrer minst nøyaktighet. Denne prosessen utføres rekursivt og undergrupper dannes ved å bruke samme generelle strategi.
For å bestemme kostnaden av delingen, brukes en kostfunksjon. En annen kostfunksjon brukes for regresjonsoppgaver og klassifiseringsoppgaver. Målet for begge kostfunksjoner er å bestemme hvilke greiner som har de mest like svarverdier eller de mest homogene greinene. Overveur at du ønsker testdata av en bestemt klasse å følge bestemte stier, og dette er intuitivt forståelig.
I forhold til regresjonskostfunksjonen for rekursiv binær deling, er algoritmen som brukes til å beregne kostnaden som følger:
sum(y – forutsagt)^2
Forutsagnet for en bestemt gruppe data punkter er gjennomsnittet av responsene fra treningdata for den gruppen. Alle datapunktene kjøres gjennom kostfunksjonen for å bestemme kostnaden for alle mulige delinger, og delingen med lavest kostnad velges.
Med hensyn til kostfunksjonen for klassifisering, er funksjonen som følger:
G = sum(pk * (1 – pk))
Dette er Gini-scoren, og det er et mål på effektiviteten av en deling, basert på hvor mange eksempler av forskjellige klasser som er i gruppene som resulterer fra delingen. Med andre ord, det kvantifiserer hvor blandet gruppene er etter delingen. En optimal deling er når alle gruppene som resulterer fra delingen består bare av inndata fra en klasse. Hvis en optimal deling er opprettet, vil «pk»-verdien være enten 0 eller 1, og G vil være lik 0. Du kan kanskje gjette at den verste delingen er en hvor det er en 50-50-representasjon av klassene i delingen, i tilfelle binær klassifisering. I dette tilfellet vil «pk»-verdien være 0,5, og G vil også være 0,5.
Dellingsprosessen avsluttes når alle datapunktene er blitt omgjort til blader og klassifisert. Imidlertid kan du ønske å stoppe veksten av treet tidlig. Store komplekse tre er utsatt for overfitting, men flere forskjellige metoder kan brukes til å bekjempe dette. En metode for å redusere overfitting er å angi et minimum antall datapunkter som vil brukes til å opprette et blad. En annen metode for å kontrollere overfitting er å begrense treet til en bestemt maksimal dybde, som kontrollerer hvor lang en sti kan strekke seg fra roten til et blad.
En annen prosess som er involvert i opprettelsen av beslutningstre er beskjæring. Beskjæring kan hjelpe med å øke ytelsen av et beslutningstre ved å fjerne greiner som inneholder egenskaper som har liten prediktiv kraft/liten viktighet for modellen. På denne måten reduseres kompleksiteten av treet, og det blir mindre sannsynlig at det overfitter, og den prediktive nytten av modellen øker.
Når beskjæring utføres, kan prosessen starte enten ved toppen av treet eller bunnen av treet. Imidlertid er den enkleste metoden for beskjæring å starte med bladene og prøve å dropppe noden som inneholder den mest vanlige klassen i bladet. Hvis nøyaktigheten av modellen ikke forverres når dette gjøres, så beholdes endringen. Det finnes andre teknikker som brukes til å utføre beskjæring, men metoden som er beskrevet ovenfor – reduksjon av feil beskjæring – er kanskje den vanligste metoden for beslutningstrebeksjæring.
Overveielser for å bruke beslutningstre
Beslutningstre er ofte nyttige når klassifisering må utføres, men beregnings tid er en stor begrensning. Beslutningstre kan gjøre det klart hvilke egenskaper i de valgte datasett som har mest prediktiv kraft. I tillegg, til forskjell fra mange maskinlæringsalgoritmer hvor reglene som brukes til å klassifisere dataene kan være vanskelige å tolke, kan beslutningstre rendre tolkbare regler. Beslutningstre er også i stand til å bruke både kategoriske og kontinuerlige variabler, noe som betyr at mindre forbehandling er nødvendig, sammenlignet med algoritmer som bare kan håndtere en av disse variabeltypene.
Beslutningstre tenderer ikke å fungere svært godt når de brukes til å bestemme verdiene av kontinuerlige attributter. En annen begrensning av beslutningstre er at, når klassifisering utføres, hvis det er få treningseksempler men mange klasser, tenderer beslutningstreet å være uakkurat.








