
AI ၅၀
Dimensionality Reduction ဆိုတာဘာလဲ။
Dimensionality Reduction ဆိုတာဘာလဲ။
Dimensionality လျှော့ချ ဒေတာအတွဲတစ်ခု၏ အတိုင်းအတာကို လျှော့ချရန်၊ အင်္ဂါရပ်များစွာကိုယူပြီး ၎င်းတို့ကို အင်္ဂါရပ်များနည်းပါးစွာ ကိုယ်စားပြုရန်အတွက် အသုံးပြုသည့် လုပ်ငန်းစဉ်တစ်ခုဖြစ်သည်။ ဥပမာအားဖြင့်၊ အတိုင်းအတာ လျှော့ချခြင်းကို အင်္ဂါရပ်အနည်းငယ်အထိ ဒေတာအတွဲနှစ်ဆယ်၏ ဒေတာအတွဲကို လျှော့ချရန် အသုံးပြုနိုင်သည်။ Dimensionality လျှော့ချခြင်းကို အများအားဖြင့် အသုံးပြုကြသည်။ ထိန်းချုပ်မှုမရှိသင်ယူမှု အင်္ဂါရပ်များစွာထဲမှ အတန်းများကို အလိုအလျောက်ဖန်တီးရန် အလုပ်များ။ ပိုနားလည်နိုင်စေရန် အတိုင်းအတာ လျှော့ချခြင်းကို အဘယ်ကြောင့် အသုံးပြုသနည်း။မြင့်မားသော အတိုင်းအတာဒေတာနှင့် အတိုင်းအတာ လျှော့ချခြင်း၏ ရေပန်းအစားဆုံး နည်းလမ်းများနှင့် ဆက်စပ်နေသော ပြဿနာများကို ကြည့်ရှုပါမည်။
ပို၍ အတိုင်းအတာများ သည် အလွန်အကျုံးဝင်ခြင်းသို့ ဦးတည်သည်။
Dimensionality သည် ဒေတာအတွဲတစ်ခုအတွင်းရှိ အင်္ဂါရပ်များ/ကော်လံများ အရေအတွက်ကို ရည်ညွှန်းသည်။
ပိုမိုတိကျသော မော်ဒယ်ကို ဖန်တီးပေးသောကြောင့် စက်သင်ယူခြင်းတွင် အင်္ဂါရပ်များ ပိုကောင်းသည်ဟု မကြာခဏ ယူဆပါသည်။ သို့သော်၊ လုပ်ဆောင်ချက်များသည် ပိုကောင်းသောမော်ဒယ်သို့ ဘာသာပြန်ဆိုရန် မလိုအပ်ပါ။
ဒေတာအတွဲတစ်ခု၏အင်္ဂါရပ်များသည် မော်ဒယ်အတွက် မည်မျှအသုံးဝင်သည်ဟူသော သတ်မှတ်ချက်များတွင် ကျယ်ပြန့်စွာကွဲပြားနိုင်ပြီး အင်္ဂါရပ်များစွာသည် အရေးမကြီးပါ။ ထို့အပြင်၊ ဒေတာအတွဲတွင် အင်္ဂါရပ်များ ပိုများလေ၊ မတူညီသော အင်္ဂါရပ်များ ပေါင်းစပ်မှုများကို ဒေတာအတွင်း ကောင်းမွန်စွာ ကိုယ်စားပြုကြောင်း သေချာစေရန် နမူနာများ ပိုမိုလိုအပ်ပါသည်။ ထို့ကြောင့်၊ နမူနာအရေအတွက်သည် အင်္ဂါရပ်များနှင့်အတူ အချိုးအစားတိုးလာသည်။ နမူနာများနှင့် နောက်ထပ်အင်္ဂါရပ်များက မော်ဒယ်ပိုမိုရှုပ်ထွေးရန် လိုအပ်ပြီး မော်ဒယ်များ ပိုမိုရှုပ်ထွေးလာသည်နှင့်အမျှ ၎င်းတို့သည် အံဝင်ခွင်ကျဖြစ်ရန် ပိုမိုအကဲဆတ်လာပါသည်။ မော်ဒယ်သည် လေ့ကျင့်ရေးဒေတာရှိ ပုံစံများကို ကောင်းစွာလေ့လာနိုင်ပြီး နမူနာဒေတာများကို ယေဘုယျဖော်ပြရန် ပျက်ကွက်သည်။
ဒေတာအတွဲတစ်ခု၏ အတိုင်းအတာကို လျှော့ချခြင်းသည် အကျိုးကျေးဇူးများစွာရှိသည်။ ဖော်ပြခဲ့သည့်အတိုင်း၊ ရိုးရှင်းသောမော်ဒယ်များသည် အင်္ဂါရပ်တစ်ခုနှင့်တစ်ခု မည်သို့ဆက်စပ်နေသည်ဟူသော ယူဆချက်ကို နည်းပါးစေရသောကြောင့် မော်ဒယ်သည် အံဝင်ခွင်ကျဖြစ်မှုနည်းပါသည်။ ထို့အပြင်၊ ကိန်းဂဏန်းများ နည်းပါးခြင်းသည် algorithms များကိုလေ့ကျင့်ရန် တွက်ချက်မှုစွမ်းအား နည်းပါးသည်ဟု ဆိုလိုသည်။ အလားတူ၊ ပိုမိုသေးငယ်သောအတိုင်းအတာရှိသော ဒေတာအတွဲအတွက် သိုလှောင်မှုနေရာလွတ်လိုအပ်ပါသည်။ ဒေတာအတွဲတစ်ခု၏ အတိုင်းအတာကို လျှော့ချခြင်းဖြင့် အင်္ဂါရပ်များစွာပါရှိသော ဒေတာအတွဲများအတွက် မသင့်လျော်သော အယ်လဂိုရီသမ်များကို အသုံးပြုနိုင်သည်။
အသုံးများသော Dimensionality လျှော့ချရေးနည်းလမ်းများ
အတိုင်းအတာ လျှော့ချခြင်းသည် အင်္ဂါရပ်ရွေးချယ်ခြင်း သို့မဟုတ် အင်္ဂါရပ်အင်ဂျင်နီယာအားဖြင့် ဖြစ်နိုင်သည်။ အင်္ဂါရပ်ရွေးချယ်မှုမှာ အင်ဂျင်နီယာသည် ဒေတာအတွဲ၏ အသက်ဆိုင်ဆုံး အင်္ဂါရပ်များကို ဖော်ထုတ်ပေးသည့်နေရာဖြစ်သည်။ အင်္ဂါရပ်အင်ဂျင်နီယာ အခြားအင်္ဂါရပ်များကို ပေါင်းစပ်ခြင်း သို့မဟုတ် အသွင်ပြောင်းခြင်းဖြင့် အင်္ဂါရပ်အသစ်များကို ဖန်တီးခြင်းလုပ်ငန်းစဉ်ဖြစ်သည်။
အင်္ဂါရပ်ရွေးချယ်ခြင်းနှင့် အင်ဂျင်နီယာပညာကို ပရိုဂရမ်စနစ်ဖြင့် သို့မဟုတ် ကိုယ်တိုင်လုပ်ဆောင်နိုင်သည်။ ကိုယ်တိုင်ရွေးချယ်ခြင်းနှင့် အင်ဂျင်နီယာအင်္ဂါရပ်များကို ရွေးချယ်သည့်အခါ၊ အင်္ဂါရပ်များနှင့် အတန်းများကြားဆက်စပ်မှုများကို ရှာဖွေတွေ့ရှိရန် ဒေတာကို မြင်ယောင်ခြင်းသည် ပုံမှန်ဖြစ်သည်။ ဤနည်းဖြင့် အတိုင်းအတာ လျှော့ချခြင်းကို လုပ်ဆောင်ခြင်းသည် အချိန်အတော်အတန် ပြင်းထန်နိုင်ပြီး ထို့ကြောင့် အတိုင်းအတာ လျှော့ချခြင်း၏ အသုံးအများဆုံး နည်းလမ်းအချို့တွင် Python အတွက် Scikit-learn ကဲ့သို့ စာကြည့်တိုက်များတွင် ရရှိနိုင်သော algorithms ကို အသုံးပြုခြင်း ပါဝင်သည်။ ဤဘုံအတိုင်းအတာ လျော့ချရေး အယ်လဂိုရီသမ်များတွင်- Principal Component Analysis (PCA)၊ Singular Value Decomposition (SVD) နှင့် Linear Discriminant Analysis (LDA) တို့ ပါဝင်သည်။
ကြီးကြပ်မှုမရှိဘဲ သင်ယူမှုလုပ်ဆောင်စရာများအတွက် အတိုင်းအတာလျှော့ချရေးတွင် အသုံးပြုသည့် အယ်လဂိုရီသမ်များသည် ပုံမှန်အားဖြင့် PCA နှင့် SVD များဖြစ်ပြီး ကြီးကြပ်ထားသော သင်ယူမှုအတိုင်းအတာကို လျှော့ချရန်အတွက် အသုံးချမှုများကို ပုံမှန်အားဖြင့် LDA နှင့် PCA တို့ဖြစ်သည်။ ကြီးကြပ်ထားသော သင်ယူမှုပုံစံများတွင်၊ အသစ်ထုတ်လုပ်လိုက်သော အင်္ဂါရပ်များကို machine learning classifier တွင် ထည့်သွင်းပေးထားပါသည်။ ဤတွင်ဖော်ပြထားသောအသုံးပြုမှုများသည် ယေဘူယျအသုံးပြုမှုကိစ္စများသာဖြစ်ပြီး အဆိုပါနည်းပညာများကို အသုံးပြုနိုင်သည့်တစ်ခုတည်းသောအခြေအနေများမဟုတ်ကြောင်း သတိပြုပါ။ အထက်တွင်ဖော်ပြထားသောအတိုင်းအတာလျှော့ချရေးဆိုင်ရာ အယ်လဂိုရီသမ်များသည် ရိုးရှင်းသောစာရင်းအင်းနည်းလမ်းများဖြစ်ပြီး ၎င်းတို့ကို စက်သင်ယူမှုမော်ဒယ်များအပြင်တွင် အသုံးပြုပါသည်။
အဓိကအစိတ်အပိုင်းခွဲခြမ်းစိတ်ဖြာခြင်း

ဓာတ်ပုံ- အဓိကအစိတ်အပိုင်းများနှင့်အတူ Matrix ကို ဖော်ထုတ်ထားသည်။
အဓိကအစိတ်အပိုင်းခွဲခြမ်းစိတ်ဖြာခြင်း (PCA) ဒေတာအတွဲတစ်ခု၏ ဝိသေသလက္ခဏာများ/အင်္ဂါရပ်များကို ပိုင်းခြားစိတ်ဖြာပြီး သြဇာအရှိဆုံးသော အင်္ဂါရပ်များကို အကျဉ်းချုပ်ဖော်ပြသည့် ကိန်းဂဏန်းဆိုင်ရာ နည်းလမ်းတစ်ခုဖြစ်သည်။ ဒေတာအတွဲ၏အင်္ဂါရပ်များကို ဒေတာ၏ဝိသေသလက္ခဏာအများစုကို ထိန်းသိမ်းထားသော်လည်း အတိုင်းအတာအနည်းငယ်အထိ ပျံ့နှံ့သွားသည့် ကိုယ်စားပြုမှုများအဖြစ် ပေါင်းစပ်ထားသည်။ ၎င်းကို အတိုင်းအတာအနည်းငယ်မျှသာရှိသော ပိုမိုမြင့်မားသောအတိုင်းအတာကိုယ်စားပြုမှုတစ်ခုမှတစ်ခုသို့ ဒေတာကို "squishing" အဖြစ် သင်ယူဆနိုင်သည်။
PCA အသုံးဝင်မည့် အခြေအနေတစ်ခု၏ ဥပမာတစ်ခုအနေဖြင့် ဝိုင်ကို ဖော်ပြနိုင်သည့် နည်းလမ်းအမျိုးမျိုးကို စဉ်းစားကြည့်ပါ။ CO2 အဆင့်၊ လေဝင်လေထွက်အဆင့် စသည်တို့ကို အသုံးပြု၍ ဝိုင်ကို ဖော်ပြနိုင်သော်လည်း၊ ဝိုင်အမျိုးအစားကို ခွဲခြားသတ်မှတ်ရန် ကြိုးစားသောအခါတွင် အဆိုပါ သီးခြားအင်္ဂါရပ်များသည် အသုံးမဝင်ပေ။ ယင်းအစား၊ အရသာ၊ အရောင်နှင့် အသက်အရွယ်တို့ကဲ့သို့ ယေဘုယျအသွင်အပြင်များပေါ်မူတည်၍ အမျိုးအစားကို ခွဲခြားသတ်မှတ်ခြင်းသည် ပို၍သတိထားရပေမည်။ ပိုမိုတိကျသော အင်္ဂါရပ်များကို ပေါင်းစပ်ရန်နှင့် ပိုမိုယေဘူယျ၊ အသုံးဝင်ပြီး အံကိုက်ဖြစ်စေရန် ဖြစ်နိုင်ခြေနည်းသော အင်္ဂါရပ်များကို ဖန်တီးရန်အတွက် PCA ကို အသုံးပြုနိုင်သည်။
PCA သည် input features များ အချင်းချင်း စပ်လျဉ်း၍ ဆိုလိုရင်းမှ မည်ကဲ့သို့ ကွဲပြားသည်ကို ဆုံးဖြတ်ပြီး အင်္ဂါရပ်များကြားတွင် ဆက်ဆံရေးရှိမရှိကို ဆုံးဖြတ်ခြင်းဖြင့် လုပ်ဆောင်သည်။ ထိုသို့လုပ်ဆောင်ရန်အတွက်၊ ဒေတာအတွဲများ၏ ဖြစ်နိုင်ချေရှိသောအတွဲများနှင့်စပ်လျဉ်း၍ ကွဲလွဲမှုများဖြင့်ဖွဲ့စည်းထားသော မက်ထရစ်ကို ကာဗရီယန်မက်ထရစ်ကို ဖန်တီးထားသည်။ ပြောင်းပြန်ဆက်စပ်ဆက်နွယ်မှုကို ညွှန်ပြသော အနုတ်သဘောဆောင်သော ဆက်စပ်မှုများနှင့် အပြုသဘောဆက်စပ်ဆက်စပ်မှုကို ညွှန်ပြသည့် အပြုသဘောဆောင်သောဆက်စပ်ဆက်နွယ်မှုကို ကိန်းရှင်များအကြားဆက်စပ်မှုများကို ဆုံးဖြတ်ရန် ၎င်းကိုအသုံးပြုသည်။
ဒေတာအတွဲ၏ အဓိက (သြဇာအရှိဆုံး) အစိတ်အပိုင်းများကို ကနဦး variables များ၏ linear ပေါင်းစပ်မှုများ ဖန်တီးခြင်းဖြင့် ဖန်တီးထားခြင်းဖြစ်ပြီး၊ linear algebra concepts များ၏ အကူအညီဖြင့် လုပ်ဆောင်ပါသည်။ eigenvalues နှင့် eigenvectors. အဓိကအစိတ်အပိုင်းများကို တစ်ခုနှင့်တစ်ခု မဆက်စပ်စေရန် ပေါင်းစပ်မှုများကို ဖန်တီးထားသည်။ ကနဦး variables များတွင်ပါရှိသော အချက်အလက်အများစုကို သေးငယ်သော အတိုင်းအတာနေရာရှိ အင်္ဂါရပ်အသစ်များ (အဓိက အစိတ်အပိုင်းများ) ကို ဖန်တီးထားပြီး ဆိုလိုသည်မှာ မူလဒေတာအတွဲမှ အချက်အလက်အများစုကို ပထမအဓိကအစိတ်အပိုင်းများထဲသို့ ဖိသိပ်ထားသည်။
Singular Value Decomposition
ဓာတ်ပုံ- By Cmglee – ကိုယ်ပိုင်အလုပ်၊ CC BY-SA 4.0၊ https://commons.wikimedia.org/w/index.php?curid=67853297
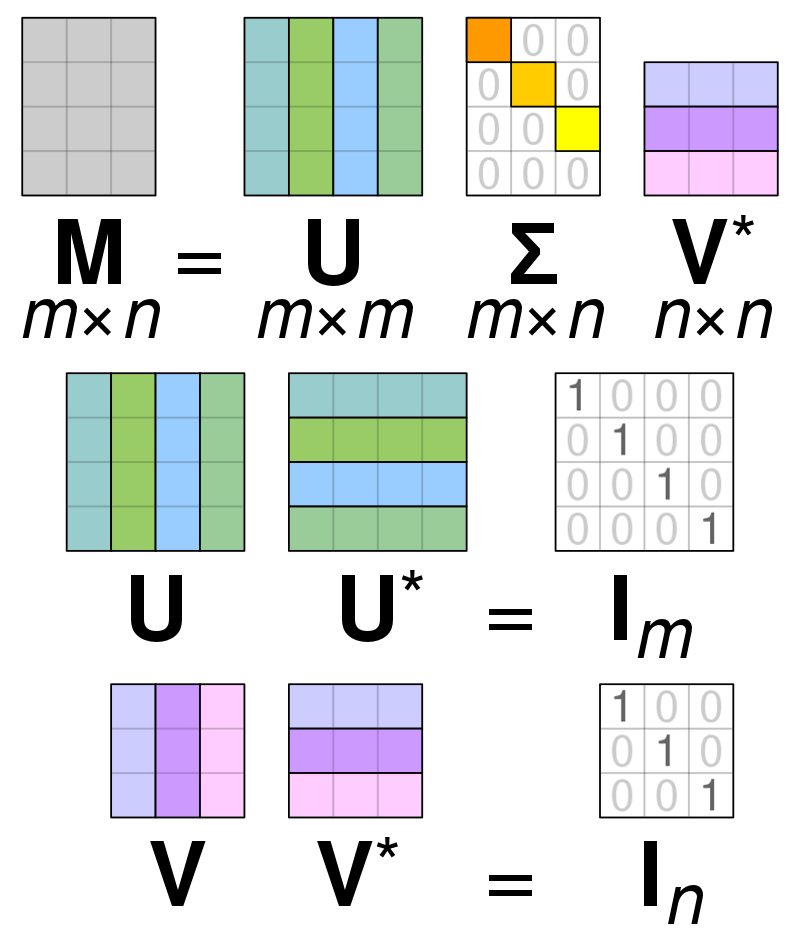
Singular Value Decomposition (SVD) is matrix အတွင်းရှိ တန်ဖိုးများကို ရိုးရှင်းစေရန် အသုံးပြုသည်။မက်ထရစ်ကို ၎င်း၏ အစိတ်အပိုင်းများအထိ လျှော့ချပြီး ထိုမက်ထရစ်ဖြင့် တွက်ချက်မှုများကို ပိုမိုလွယ်ကူစေသည်။ SVD ကို အစစ်အမှန်တန်ဖိုးနှင့် ရှုပ်ထွေးသော matrices နှစ်ခုလုံးအတွက် အသုံးချနိုင်သော်လည်း ဤရှင်းပြချက်၏ ရည်ရွယ်ချက်များအတွက်၊ စစ်မှန်သောတန်ဖိုးများ၏ matrix ကို မည်သို့ပြိုကွဲစေသည်ကို ဆန်းစစ်ပါမည်။
ကျွန်ုပ်တို့တွင် တန်ဖိုးအမှန်ဒေတာဖြင့် ဖွဲ့စည်းထားသည့် matrix တစ်ခုရှိသည်ဟု ယူဆရပြီး ကျွန်ုပ်တို့၏ပန်းတိုင်မှာ PCA ၏ပန်းတိုင်နှင့်ဆင်တူသော matrix အတွင်း ကော်လံ/အင်္ဂါရပ်များ အရေအတွက်ကို လျှော့ချရန်ဖြစ်သည်။ PCA ကဲ့သို့ပင်၊ SVD သည် matrix ၏ ကွဲပြားမှုကို တတ်နိုင်သမျှ ထိန်းသိမ်းထားစဉ်တွင် matrix ၏ အတိုင်းအတာကို ချုံ့သွားမည်ဖြစ်သည်။ matrix A ပေါ်တွင် လည်ပတ်လိုပါက U, D, & V ဟုခေါ်သော အခြား matrices သုံးခုအဖြစ် matrix A ကို ကိုယ်စားပြုနိုင်ပါသည်။ Matrix A သည် မူလ x* y ဒြပ်စင်များနှင့် ဖွဲ့စည်းထားပြီး matrix U သည် X * X (၎င်းသည် orthogonal matrix)။ Matrix V သည် y*y ဒြပ်စင်များပါရှိသော မတူညီသော ထောင့်မှန်မက်ထရစ်ဖြစ်သည်။ Matrix D တွင် ဒြပ်စင် x * y ပါ၀င်ပြီး ၎င်းသည် ထောင့်ဖြတ်မက်ထရစ်ဖြစ်သည်။
matrix A အတွက် တန်ဖိုးများကို ပြိုကွဲစေရန်အတွက်၊ ကျွန်ုပ်တို့သည် မူရင်း အနည်းကိန်း matrix တန်ဖိုးများကို အသစ်တစ်ခုအတွင်း တွေ့ရသော ထောင့်ဖြတ်တန်ဖိုးများအဖြစ်သို့ ပြောင်းရန် လိုအပ်ပါသည်။ orthogonal matrices ဖြင့် အလုပ်လုပ်သောအခါ၊ ၎င်းတို့ကို အခြားဂဏန်းများဖြင့် မြှောက်ပါက ၎င်းတို့၏ ဂုဏ်သတ္တိများ မပြောင်းလဲပါ။ ထို့ကြောင့်၊ ဤပိုင်ဆိုင်မှုကို အသုံးချခြင်းဖြင့် ကျွန်ုပ်တို့သည် အနီးစပ်ဆုံး matrix A ကို လုပ်ဆောင်နိုင်သည်။ ကျွန်ုပ်တို့သည် Matrix V ၏ အသွင်ကူးပြောင်းမှုနှင့်အတူ ထောင့်မှန်မက်ထရစ်များကို မြှောက်သောအခါ၊ ရလဒ်သည် ကျွန်ုပ်တို့၏ မူရင်း A နှင့် ညီမျှသော matrix ဖြစ်သည်။
Matrix a ကို matrices U၊ D နှင့် V များအဖြစ်သို့ ပြိုကွဲသွားသောအခါ၊ ၎င်းတို့တွင် Matrix A တွင်တွေ့ရှိရသော ဒေတာများ ပါဝင်ပါသည်။ သို့သော်၊ matrices များ၏ ဘယ်ဘက်စွန်းမှ ကော်လံများသည် ဒေတာအများစုကို ထိန်းထားမည်ဖြစ်သည်။ ကျွန်ုပ်တို့သည် ဤပထမကော်လံအနည်းငယ်ကိုသာ ယူနိုင်ပြီး A အတွင်းရှိ ဒေတာအများစုသည် ပိုနည်းသောအတိုင်းအတာနှင့် A အတွင်းရှိဒေတာအများစုပါရှိသော Matrix A ကို ကိုယ်စားပြုမှုရှိသည်။
Linear Discriminant Analysis

ဘယ်- LDA မတိုင်မီ မက်ထရစ်၊ ညာဘက်- LDA ပြီးနောက် ဝင်ရိုး၊ ယခု ခွဲခြားနိုင်သည်။
Linear Discriminant Analysis (LDA) Multidimensional graph မှ data ကိုယူတဲ့ process တစ်ခုဖြစ်ပါတယ်။ မျဉ်းကြောင်းဂရပ်ပေါ်တွင် ၎င်းကို ပယ်ချသည်။. မတူညီသောအတန်းနှစ်ခုရှိ ဒေတာအမှတ်များဖြည့်ထားသော နှစ်ဖက်မြင်ဂရပ်ကို စဉ်းစားခြင်းဖြင့် ၎င်းကို သင်မြင်ယောင်နိုင်သည်။ မတူညီသောအတန်းနှစ်ခုကို သေသေသပ်သပ်ခွဲထုတ်မည့် စာကြောင်းတစ်ကြောင်းမျှ မဆွဲနိုင်စေရန် အမှတ်များ ပြန့်ကျဲနေသည်ဟု ယူဆပါ။ ဤအခြေအနေကို ကိုင်တွယ်ရန်အတွက် 2D ဂရပ်တွင် တွေ့ရသော အချက်များကို 1D ဂရပ် (တစ်ကြောင်း) သို့ လျှော့ချနိုင်သည်။ ဤစာကြောင်းတွင် ဒေတာအချက်များအားလုံးကို ဖြန့်ဝေပေးမည်ဖြစ်ပြီး ၎င်းကို ဒေတာ၏ ဖြစ်နိုင်ချေအကောင်းဆုံး ခွဲခြားမှုကို ကိုယ်စားပြုသည့် အပိုင်းနှစ်ပိုင်းအဖြစ် ပိုင်းခြားနိုင်မည်ဟု မျှော်လင့်ပါသည်။
LDA ကို ဆောင်ရွက်ရာတွင် အဓိက ရည်မှန်းချက် နှစ်ခုရှိသည်။ ပထမပန်းတိုင်မှာ အတန်းများအတွက် ကွဲလွဲမှုကို လျှော့ချရန်ဖြစ်ပြီး ဒုတိယပန်းတိုင်မှာ အတန်းနှစ်ခု၏ နည်းလမ်းများကြား အကွာအဝေးကို အမြင့်ဆုံးဖြစ်အောင် လုပ်ဆောင်ခြင်းဖြစ်သည်။ 2D ဂရပ်တွင် တည်ရှိမည့် ဝင်ရိုးအသစ်ကို ဖန်တီးခြင်းဖြင့် ဤပန်းတိုင်များကို ပြီးမြောက်စေသည်။ အသစ်ဖန်တီးထားသော ဝင်ရိုးသည် ယခင်က ဖော်ပြထားသည့် ပန်းတိုင်များပေါ်မူတည်၍ အတန်းနှစ်ခုကို ခွဲခြားရန် လုပ်ဆောင်သည်။ ဝင်ရိုးကို ဖန်တီးပြီးပါက၊ 2D ဂရပ်တွင် တွေ့ရသော အမှတ်များကို ဝင်ရိုးတစ်လျှောက် ထားရှိမည်ဖြစ်သည်။
မူလအမှတ်များကို ဝင်ရိုးအသစ်တစ်လျှောက် အနေအထားအသစ်သို့ ရွှေ့ရန် အဆင့်သုံးဆင့်ရှိသည်။ ပထမအဆင့်တွင်၊ အတန်းတစ်ခုချင်းကြားအကွာအဝေးကို အတန်းများ၏ခွဲထွက်နိုင်မှုကို တွက်ချက်ရန် (ကြား-လူတန်းစားကွဲလွဲမှုကို ဆိုလိုသည်) ကိုအသုံးပြုသည်။ ဒုတိယအဆင့်တွင်၊ မေးခွန်းရှိအတန်းအတွက် နမူနာနှင့် ပျမ်းမျှကြားအကွာအဝေးကို ဆုံးဖြတ်ခြင်းဖြင့် မတူညီသောအတန်းများအတွင်းကွဲလွဲမှုကို တွက်ချက်သည်။ နောက်ဆုံးအဆင့်တွင်၊ အတန်းများကြားကွဲလွဲမှုကို အမြင့်ဆုံးဖြစ်စေသော အောက်ဖက်မြင် အာကာသကို ဖန်တီးထားသည်။
ပစ်မှတ်အတန်းများအတွက် နည်းလမ်းများသည် တစ်ခုနှင့်တစ်ခု ဝေးကွာနေချိန်တွင် LDA နည်းပညာသည် အကောင်းဆုံးရလဒ်များကို ရရှိသည်။ ဖြန့်ဖြူးမှုအတွက် ဆိုလိုသည်မှာ ထပ်နေပါက LDA သည် အတန်းများကို linear axis ဖြင့် ထိရောက်စွာ ခွဲခြား၍မရပါ။










