
AI ၅၀
CNNs (Convolutional Neural Networks) ဆိုတာ ဘာလဲ။
Facebook သို့မဟုတ် Instagram သည် ပုံတစ်ပုံရှိ မျက်နှာများကို အလိုအလျောက်မှတ်မိနိုင်ပုံ၊ သို့မဟုတ် သင့်ကိုယ်ပိုင်ဓာတ်ပုံကို တင်ရုံဖြင့် အလားတူဓာတ်ပုံများအတွက် Google က ဝဘ်ပေါ်တွင် ရှာဖွေနိုင်ပုံကို သင် သိချင်နေပေမည်။ ဤအင်္ဂါရပ်များသည် ကွန်ပြူတာအမြင်၏ ဥပမာများဖြစ်ပြီး ၎င်းတို့ကို စွမ်းဆောင်ထားသည်။ convolutional neural networks (CNNs). သို့တိုင် convolutional neural networks များသည် အဘယ်နည်း။ CNN ၏ ဗိသုကာလက်ရာကို နက်ရှိုင်းစွာ စေ့စေ့ငုငု လေ့လာပြီး ၎င်းတို့ လုပ်ဆောင်ပုံကို နားလည်ကြပါစို့။
Neural Networks ဆိုတာ ဘာလဲ။
convolutional neural networks တွေအကြောင်း မပြောခင် ပုံမှန် neural network ကို သတ်မှတ်ဖို့ ခဏလောက် အချိန်ယူကြည့်ရအောင်။ ဟိုမှာ အခြားဆောင်းပါး ရရှိနိုင်သော neural networks ၏ ခေါင်းစဉ်ဖြင့်၊ ထို့ကြောင့် ၎င်းတို့ကို ဤနေရာတွင် အလွန်နက်ရှိုင်းစွာ နားမလည်ပါ။ သို့သော် ၎င်းတို့ကို အတိုချုံးအဓိပ္ပာယ်ဖွင့်ဆိုရန် ၎င်းတို့သည် လူ့ဦးနှောက်မှ မှုတ်သွင်းထားသော တွက်ချက်မှုပုံစံများဖြစ်သည်။ အာရုံကြောကွန်ရက်တစ်ခုသည် ဒေတာကိုရယူပြီး ဒေတာကို ထိန်းညှိခြင်းဖြင့် လည်ပတ်လုပ်ဆောင်သည်၊ ၎င်းသည် ထည့်သွင်းမှုအင်္ဂါရပ်များသည် တစ်ခုနှင့်တစ်ခု ဆက်စပ်နေပြီး အရာဝတ္ထု၏အတန်းအစားများနှင့်ပတ်သက်၍ ယူဆချက်ဖြစ်သည့် “အလေးချိန်များ” ကို ချိန်ညှိခြင်းဖြင့် လုပ်ဆောင်သည်။ ကွန်ရက်ကို လေ့ကျင့်ထားသောကြောင့် အလေးများ၏တန်ဖိုးများကို ချိန်ညှိပြီး အင်္ဂါရပ်များကြားရှိ ဆက်ဆံရေးများကို တိကျစွာဖမ်းယူနိုင်သော အလေးများအဖြစ် ပေါင်းစည်းနိုင်မည်ဟု မျှော်လင့်ပါသည်။
ဤသည်မှာ feed-forward neural network လည်ပတ်ပုံဖြစ်ပြီး CNN များသည် feed-forward neural network နှင့် convolutional layers အုပ်စုနှစ်ခုဖြင့် ပါဝင်ပါသည်။
Convolution Neural Networks (CNNs) ဆိုတာ ဘာလဲ။
convolutional neural network တွင် ဖြစ်ပျက်နေသော "convolutions" များသည် အဘယ်နည်း။ convolution ဆိုသည်မှာ ပုံ၏ အစိတ်အပိုင်းများကို ကိုယ်စားပြုသည့် အလေးများကို ဖန်တီးပေးသည့် သင်္ချာဆိုင်ရာ လုပ်ဆောင်ချက်တစ်ခုဖြစ်သည်။ ဤအလေးများအစုအဝေးဟုခေါ်သည်။ kernel သို့မဟုတ် filter တစ်ခု. ဖန်တီးထားသည့် filter သည် ပုံ၏ အပိုင်းခွဲတစ်ခုမျှသာ ပါဝင်သည့် input image တစ်ခုလုံးထက် သေးငယ်ပါသည်။ ဇကာရှိတန်ဖိုးများကို ပုံရှိတန်ဖိုးများနှင့် မြှောက်ထားသည်။ ထို့နောက် ရုပ်ပုံ၏ အစိတ်အပိုင်းအသစ်ကို ကိုယ်စားပြုမှုအဖြစ် ဖန်တီးရန် ဇကာကို ရွှေ့လိုက်ပြီး ရုပ်ပုံတစ်ခုလုံးကို ဖုံးလွှမ်းသွားသည်အထိ ထပ်ခါတလဲလဲ လုပ်ဆောင်သည်။
၎င်းကိုစဉ်းစားရန် နောက်တစ်နည်းမှာ ထည့်သွင်းပုံရှိ pixels များကို ကိုယ်စားပြုသော အုတ်များဖြင့် အုတ်နံရံတစ်ခုကို စိတ်ကူးကြည့်ရန်ဖြစ်သည်။ ဇကာဖြစ်သည့် နံရံတစ်လျှောက် “ပြတင်းပေါက်” သည် အနောက်သို့ လျှောကျနေသည်။ ပြတင်းပေါက်မှတဆင့် ကြည့်ရှုနိုင်သော အုတ်များသည် စစ်ထုတ်မှုအတွင်း တန်ဖိုးများဖြင့် မြှောက်ထားသော pixels များဖြစ်သည်။ ထို့ကြောင့်၊ filter တစ်ခုဖြင့်အလေးများဖန်တီးခြင်းနည်းလမ်းကို "လျှောပြတင်းပေါက်များ" နည်းပညာအဖြစ်မကြာခဏရည်ညွှန်းသည်။
input image တစ်ခုလုံးကို လှည့်ပတ်နေသော filters များမှ output သည် ပုံတစ်ခုလုံးကို ကိုယ်စားပြုသည့် နှစ်ဖက်မြင် array တစ်ခုဖြစ်သည်။ ဤ array ကို a ဟုခေါ်သည်။ "အင်္ဂါရပ်မြေပုံ".
ဘာကြောင့် Convolutions တွေက မရှိမဖြစ်လိုအပ်တာလဲ။
မည်သို့ပင်ဖြစ်စေ အလှည့်အပြောင်းများ ဖန်တီးရခြင်း၏ ရည်ရွယ်ချက်မှာ အဘယ်နည်း။ အာရုံကြောကွန်ရက်တစ်ခုသည် ပုံတစ်ပုံရှိ pixels များကို ဂဏန်းတန်ဖိုးများအဖြစ် အဓိပ္ပာယ်ပြန်ဆိုနိုင်စေသောကြောင့် ရှုပ်ထွေးမှုများ လိုအပ်ပါသည်။ convolutional အလွှာများ၏လုပ်ဆောင်ချက်မှာ ရုပ်ပုံအား အာရုံကြောကွန်ရက်မှ အဓိပ္ပာယ်ဖွင့်ဆိုနိုင်သော ဂဏန်းတန်ဖိုးများအဖြစ်သို့ ပြောင်းလဲပြီးနောက် သက်ဆိုင်ရာပုံစံများမှ ထုတ်ယူရန်ဖြစ်သည်။ convolutional network ရှိ filters များ၏ အလုပ်မှာ ပုံရှိ ပုံစံများကို လေ့လာမည့် neural network ၏ နောက်ပိုင်း အလွှာများ သို့ ဖြတ်သန်းနိုင်သည့် နှစ်ဖက်မြင် တန်ဖိုးများကို ဖန်တီးရန် ဖြစ်သည်။
စစ်ထုတ်မှုများနှင့် ချန်နယ်များ
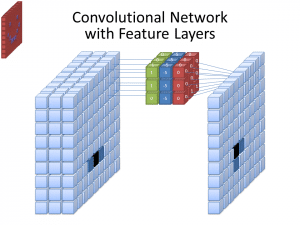
ဓာတ်ပုံ- Wikimedia Commons မှတဆင့် cecebur၊ CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
ထည့်သွင်းပုံများမှ ပုံစံများကို လေ့လာရန် CNN များသည် စစ်ထုတ်မှုတစ်ခုတည်းကို မသုံးပါ။ Filter အများအပြားကို အသုံးပြုထားသည်။မတူညီသော စစ်ထုတ်မှုများမှ ဖန်တီးထားသော မတူညီသော arrays များသည် input image ၏ ပိုမိုရှုပ်ထွေးပြီး ကြွယ်ဝသော ကိုယ်စားပြုမှုကို ဖြစ်စေသောကြောင့်၊ CNN များအတွက် အသုံးများသော filter အရေအတွက်များမှာ 32၊ 64၊ 128 နှင့် 512 ဖြစ်သည်။ စစ်ထုတ်မှုများများလေလေ၊ CNN မှ ထည့်သွင်းဒေတာများကို စစ်ဆေးပြီး ၎င်းထံမှ သင်ယူရန် အခွင့်အလမ်းများလေလေဖြစ်သည်။
အရာဝတ္ထုများ၏ နယ်နိမိတ်များကို ဆုံးဖြတ်ရန်အတွက် CNN သည် pixel တန်ဖိုးများ ကွဲပြားမှုများကို ပိုင်းခြားစိတ်ဖြာသည်။ မီးခိုးရောင်စကေးပုံတွင်၊ CNN သည် အနက်ရောင်နှင့် အဖြူ၊ အလင်းမှ အမှောင်ဟူသော ကွဲပြားချက်များကိုသာ ကြည့်ရှုမည်ဖြစ်သည်။ ရုပ်ပုံများသည် ရောင်စုံရုပ်ပုံများဖြစ်သည့်အခါ CNN သည် အမှောင်နှင့်အလင်းကို ထည့်သွင်းတွက်ချက်သည်သာမက အနီရောင်၊ အစိမ်းနှင့် အပြာဟူ၍ ကွဲပြားသောအရောင်လိုင်းသုံးမျိုးကိုလည်း ထည့်သွင်းစဉ်းစားရမည်ဖြစ်သည်။ ဤကိစ္စတွင်၊ စစ်ထုတ်မှုများသည် ပုံတွင်ပြထားသည့်အတိုင်း ချန်နယ် 3 လိုင်းရှိသည်။ စစ်ထုတ်မှုတစ်ခုရှိ ချန်နယ်အရေအတွက်ကို ၎င်း၏အတိမ်အနက်အဖြစ် ရည်ညွှန်းပြီး စစ်ထုတ်ခြင်းရှိ ချန်နယ်အရေအတွက်သည် ပုံရှိချန်နယ်အရေအတွက်နှင့် တူညီရပါမည်။
Convolutional Neural Network (CNN) ဗိသုကာအတတ်ပညာ
ဗိသုကာလက်ရာ အပြည့်အစုံကို လေ့လာကြည့်ရအောင် convolutional neural network တစ်ခု။ ပုံဒေတာကို ကိန်းဂဏာန်းခင်းများအဖြစ်သို့ ပြောင်းလဲရန် လိုအပ်သောကြောင့် convolutional အလွှာတစ်ခုအား convolutional network တစ်ခုစီ၏အစတွင် တွေ့နိုင်သည်။ သို့ရာတွင်၊ convolutional layers များသည် အခြားသော convolutional layers များနောက်သို့ ထွက်လာနိုင်သည်၊ ဆိုလိုသည်မှာ ထိုအလွှာများသည် တစ်ခုနှင့်တစ်ခု အပေါ်ထပ်တွင် စုထားနိုင်သည်။ Convolutional Layer အများအပြားရှိခြင်းဆိုသည်မှာ အလွှာတစ်ခုမှထွက်ရှိချက်များကို ပိုမိုရှုပ်ထွေးစေပြီး သက်ဆိုင်ရာပုံစံများဖြင့် အုပ်စုဖွဲ့နိုင်သည်ကို ဆိုလိုသည်။ လက်တွေ့အားဖြင့်၊ ဆိုလိုသည်မှာ ရုပ်ပုံဒေတာသည် convolutional အလွှာများမှတဆင့် စီးဆင်းလာသည်နှင့်အမျှ ကွန်ရက်သည် ရုပ်ပုံ၏ ပိုမိုရှုပ်ထွေးသောအင်္ဂါရပ်များကို “အသိအမှတ်ပြု” ရန် စတင်လာသည်။
ConvNet ၏ အစောပိုင်းအလွှာများသည် ရိုးရှင်းသောလိုင်းများဖန်တီးသည့် pixels ကဲ့သို့သော အဆင့်နိမ့်အင်္ဂါရပ်များကို ထုတ်ယူရန်အတွက် တာဝန်ရှိပါသည်။ ConvNet ၏ နောက်ပိုင်းအလွှာများသည် ဤမျဉ်းများကို ပုံသဏ္ဍာန်အဖြစ် ပေါင်းစည်းမည်ဖြစ်သည်။ မျက်နှာပြင်အဆင့်ခွဲခြမ်းစိတ်ဖြာခြင်းမှ နက်နဲသောအဆင့်ခွဲခြမ်းစိတ်ဖြာခြင်းသို့ ရွှေ့ခြင်းလုပ်ငန်းစဉ်သည် ConvNet သည် တိရိစ္ဆာန်များ၊ လူမျက်နှာများနှင့် ကားများကဲ့သို့ ရှုပ်ထွေးသောပုံစံများကို အသိအမှတ်ပြုမထားပါ။
ဒေတာသည် convolutional အလွှာများအားလုံးကိုဖြတ်သန်းပြီးနောက်၊ ၎င်းသည် CNN ၏သိပ်သည်းစွာချိတ်ဆက်ထားသောအပိုင်းသို့ရောက်ရှိသွားသည်။ သိပ်သည်းစွာ ချိတ်ဆက်ထားသော အလွှာများသည် တစ်ခုနှင့်တစ်ခု ချိတ်ဆက်ထားသည့် အလွှာများအဖြစ် ပေါင်းစပ်ထားသော node များကို ရိုးရာအစာ-ရှေ့သို့ အာရုံကြောကွန်ရက်ပုံစံနှင့် တူသည်။ ဒေတာများသည် ကွန်မြူလာအလွှာများမှ ထုတ်ယူထားသော ပုံစံများကို လေ့လာသည့် ဤသိပ်သည်းစွာ ချိတ်ဆက်ထားသော အလွှာများမှတဆင့် စီးဆင်းသွားကာ ကွန်ရက်သည် အရာဝတ္ထုများကို မှတ်မိနိုင်စွမ်းရှိလာပါသည်။










