
AI ၅၀
Decision Tree ဆိုတာ ဘာလဲ။
Decision Tree ဆိုတာ ဘာလဲ။
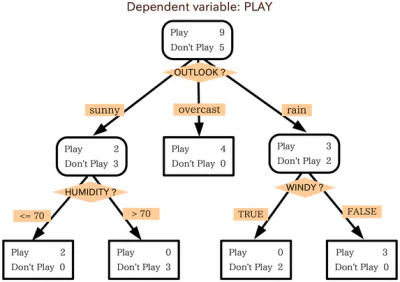
A ဆုံးဖြတ်ချက်သစ်ပင် ဆုတ်ယုတ်ခြင်းနှင့် အမျိုးအစားခွဲခြင်းလုပ်ငန်းများအတွက် အသုံးပြုသည့် အသုံးဝင်သော စက်သင်ယူမှု အယ်လဂိုရီသမ်တစ်ခုဖြစ်သည်။ “ဆုံးဖြတ်ချက်သစ်ပင်” ဟူသောအမည်သည် ဒေတာအတွဲများကို အသေးနှင့်အသေးစားအပိုင်းများအဖြစ် ဆက်လက်ခွဲဝေပေးသည့်အချက်မှ ဆင်းသက်လာကာ ဒေတာများကို ဖြစ်ရပ်တစ်ခုတည်းအဖြစ်သို့ ခွဲခြားမခံရမီအထိ၊ အယ်လဂိုရီသမ်၏ ရလဒ်များကို မြင်ယောင်ကြည့်မည်ဆိုလျှင်၊ အမျိုးအစားများကို ပိုင်းခြားပုံသည် သစ်ပင်တစ်ပင်နှင့် အရွက်များစွာနှင့် ဆင်တူသည်။
ဆုံးဖြတ်ချက်သစ်ပင်၏ လျင်မြန်သော အဓိပ္ပါယ်ဖွင့်ဆိုချက်ဖြစ်သည်၊ သို့သော် ဆုံးဖြတ်ချက်သစ်ပင်များ၏ အလုပ်လုပ်ပုံကို နက်နဲစွာ စေ့စေ့ငုကြည့်ကြပါစို့။ ဆုံးဖြတ်ချက်သစ်ပင်များ၏ လည်ပတ်ပုံအပြင် ၎င်းတို့၏အသုံးပြုမှုကိစ္စရပ်များကို ပိုမိုကောင်းမွန်စွာနားလည်သဘောပေါက်ခြင်းသည် သင့်စက်သင်ယူမှုပရောဂျက်များအတွင်း ၎င်းတို့ကို မည်သည့်အချိန်တွင် အသုံးပြုရမည်ကို သိရှိရန် ကူညီပေးပါမည်။
ဆုံးဖြတ်ချက်သစ်ပင်ပုံစံ
ဆုံးဖြတ်ချက်သစ်ပင်ဖြစ်ပါသည်။ flowchart တစ်ခုနဲ့ တော်တော်တူပါတယ်။ ဇယားကွက်ကို အသုံးပြုရန် သင်သည် ဇယား၏ အစမှတ် သို့မဟုတ် အမြစ်တွင် စတင်ပြီးနောက် ၎င်းစတင်သည့်နုဒ်၏ စစ်ထုတ်ခြင်းဆိုင်ရာ စံနှုန်းများကို သင်ဖြေဆိုပုံအပေါ် အခြေခံ၍ သင်သည် နောက်ဖြစ်နိုင်ချေရှိသော node များထဲမှ တစ်ခုကို ရွှေ့ပါ။ ပြီးဆုံးသည်အထိ ဤလုပ်ငန်းစဉ်ကို ထပ်ခါတလဲလဲ လုပ်ဆောင်သည်။
ဆုံးဖြတ်ချက်သစ်ပင်များသည် အခြေခံအားဖြင့် တူညီသောပုံစံဖြင့် လုပ်ဆောင်ကြပြီး၊ သစ်ပင်ရှိ အတွင်းပိုင်းနေရာတိုင်းသည် စမ်းသပ်မှု/စစ်ထုတ်ခြင်းဆိုင်ရာ စံနှုန်းအချို့ဖြစ်သည်။ အပြင်ဘက်ရှိ ဆုံမှတ်များ၊ သစ်ပင်၏ အဆုံးမှတ်များသည် မေးခွန်းထုတ်ထားသော ဒေတာမှတ်အတွက် အညွှန်းများဖြစ်ပြီး ၎င်းတို့ကို "ရွက်များ" ဟုခေါ်သည်။ အတွင်းပိုင်း node များမှ နောက် node သို့ ဦးတည်သော အကိုင်းအခက်များသည် အင်္ဂါရပ်များ သို့မဟုတ် ပေါင်းစပ်မှုများဖြစ်သည်။ ဒေတာမှတ်များကို အမျိုးအစားခွဲရာတွင် အသုံးပြုသည့် စည်းမျဉ်းများသည် အမြစ်မှ အရွက်ဆီသို့ လမ်းကြောင်းများဖြစ်သည်။
ဆုံးဖြတ်ချက်သစ်များ အတွက် အယ်လဂိုရီသမ်များ
ဆုံးဖြတ်ချက်သစ်များသည် မတူညီသောစံနှုန်းများအပေါ်အခြေခံ၍ dataset ကိုတစ်ဦးချင်းစီဒေတာအမှတ်များအဖြစ်ခွဲခြမ်းပေးသည့် algorithmic ချဉ်းကပ်မှုဖြင့်လုပ်ဆောင်သည်။ ဤခွဲခြမ်းများကို မတူညီသော ကိန်းရှင်များ သို့မဟုတ် ဒေတာအတွဲ၏ ကွဲပြားခြားနားသော အင်္ဂါရပ်များဖြင့် လုပ်ဆောင်ပါသည်။ ဥပမာအားဖြင့်၊ ရည်မှန်းချက်သည် ခွေး သို့မဟုတ် ကြောင်ကို ထည့်သွင်းမှုအင်္ဂါရပ်များဖြင့် ဖော်ပြခြင်းရှိ၊ မရှိ ဆုံးဖြတ်ရန်ဖြစ်ပါက၊ ဒေတာကို ကွဲကွဲပြားပြားဖြစ်စေသော ကွဲလွဲချက်များမှာ "ခြေသည်း" နှင့် "ဟောင်" ကဲ့သို့သော အရာများ ဖြစ်နိုင်သည်။
ဒါဆို data တွေကို အကိုင်းအခက် အရွက်တွေ ခွဲဖို့ ဘယ် algorithms ကို သုံးလဲ။ သစ်ပင်တစ်ပင်ကို ခွဲထုတ်ရာတွင် အသုံးပြုနိုင်သော နည်းလမ်းအမျိုးမျိုးရှိသော်လည်း ခွဲခြမ်းခြင်း၏ အသုံးအများဆုံးနည်းလမ်းမှာ "ဟု ရည်ညွှန်းသည့် နည်းပညာတစ်ခု ဖြစ်နိုင်သည်။recursive binary ခွဲခြမ်း” ဤခွဲခြမ်းနည်းကို လုပ်ဆောင်သောအခါ၊ လုပ်ငန်းစဉ်သည် အမြစ်မှစတင်ပြီး ဒေတာအတွဲရှိ အင်္ဂါရပ်အရေအတွက်သည် ဖြစ်နိုင်ချေရှိသော ခွဲခြမ်းအရေအတွက်ကို ကိုယ်စားပြုသည်။ ဖြစ်နိုင်ချေရှိသော ခွဲခြမ်းတိုင်းအတွက် မည်မျှတိကျမည်ကို ဆုံးဖြတ်ရန် လုပ်ဆောင်ချက်တစ်ခုကို အသုံးပြုပြီး ခွဲခြမ်းမှုကို တိကျမှုအနည်းဆုံးဖြစ်စေသည့် စံနှုန်းများကို အသုံးပြု၍ ခွဲခြမ်းခြင်းကို ပြုလုပ်ထားသည်။ ဤလုပ်ငန်းစဉ်ကို ထပ်ခါတလဲလဲလုပ်ဆောင်ပြီး တူညီသော ယေဘူယျဗျူဟာကို အသုံးပြု၍ အုပ်စုခွဲများကို ဖွဲ့စည်းထားပါသည်။
အလို့ငှာ ခွဲခြမ်း၏ကုန်ကျစရိတ်ကိုဆုံးဖြတ်ပါ။ကုန်ကျစရိတ် လုပ်ဆောင်ချက်ကို အသုံးပြုသည်။ ကွဲပြားသော ကုန်ကျစရိတ်လုပ်ဆောင်ချက်ကို ဆုတ်ယုတ်မှုလုပ်ဆောင်မှုများနှင့် အမျိုးအစားခွဲခြားခြင်းလုပ်ငန်းများအတွက် အသုံးပြုသည်။ ကုန်ကျစရိတ်လုပ်ဆောင်မှုနှစ်ခုလုံး၏ ရည်မှန်းချက်မှာ မည်သည့်အကိုင်းအခက်များတွင် ဆင်တူသည့်တုံ့ပြန်မှုတန်ဖိုးများ သို့မဟုတ် တစ်သားတည်းဖြစ်မှုအရှိဆုံးအကိုင်းအခက်များကို ဆုံးဖြတ်ရန်ဖြစ်သည်။ သင်သည် အချို့သော အတန်း၏ စမ်းသပ်ဒေတာကို အချို့သောလမ်းကြောင်းများအတိုင်း လိုက်လျှောက်လိုကြောင်း ဆင်ခြင်ပါ၊ ၎င်းသည် အလိုလိုနားလည်သဘောပေါက်စေသည်။
recursive binary ခွဲခြင်းအတွက် regression cost function ၏စည်းကမ်းချက်များအရ၊ ကုန်ကျစရိတ်တွက်ချက်ရန်အသုံးပြုသည့် algorithm မှာ အောက်ပါအတိုင်းဖြစ်သည်-
sum(y – ခန့်မှန်းချက်)^2
ဒေတာအမှတ်အုပ်စုတစ်စုအတွက် ခန့်မှန်းချက်သည် ထိုအုပ်စုအတွက် လေ့ကျင့်ရေးဒေတာ၏ တုံ့ပြန်မှုများ၏ ဆိုလိုရင်းဖြစ်သည်။ ဖြစ်နိုင်ချေရှိသော ခွဲခြမ်းများအားလုံးအတွက် ကုန်ကျစရိတ်ကို ဆုံးဖြတ်ရန် ဒေတာအချက်များအားလုံးကို ကုန်ကျစရိတ်လုပ်ဆောင်ချက်မှတစ်ဆင့် လုပ်ဆောင်ပြီး ကုန်ကျစရိတ်အနည်းဆုံးဖြင့် ခွဲခြမ်းကို ရွေးချယ်ပါသည်။
အမျိုးအစားခွဲခြင်းအတွက် ကုန်ကျစရိတ်လုပ်ဆောင်ချက်နှင့်ပတ်သက်၍၊ လုပ်ဆောင်ချက်မှာ အောက်ပါအတိုင်းဖြစ်သည်။
G = sum(pk * (1 – pk))
ဤသည်မှာ Gini ရမှတ်ဖြစ်ပြီး ခွဲထွက်ခြင်းမှ ထွက်ပေါ်လာသော အုပ်စုများတွင် မတူညီသော အတန်းအရေအတွက် မည်မျှရှိသည်ကို အခြေခံ၍ ခွဲထွက်ခြင်း၏ ထိရောက်မှုကို တိုင်းတာခြင်းဖြစ်သည်။ တစ်နည်းဆိုရသော် ၎င်းသည် ခွဲထွက်ပြီးနောက် အုပ်စုများ မည်ကဲ့သို့ ရောနှောသည်ကို တွက်ချက်သည်။ ခွဲထွက်ခြင်းမှ ထွက်ပေါ်လာသော အုပ်စုအားလုံးသည် အတန်းတစ်ခုမှ သွင်းအားစုများသာ ပါဝင်နေသောအခါ အကောင်းဆုံးသော ခွဲထွက်ခြင်းဖြစ်ပါသည်။ အကောင်းဆုံးခွဲခြမ်းတစ်ခုကို ဖန်တီးပြီးပါက "pk" တန်ဖိုးသည် 0 သို့မဟုတ် 1 ဖြစ်မည်ဖြစ်ပြီး G သည် သုညနှင့် ညီမျှမည်ဖြစ်သည်။ အဆိုးဆုံး-ဖြစ်ရပ်ခွဲခွဲသည် ဒွိအမျိုးအစားခွဲခြားမှုကိစ္စတွင် ခွဲခြမ်းရှိ အတန်းများ၏ 50-50 ကိုယ်စားပြုမှုရှိသည့် နေရာတစ်ခုဖြစ်ကြောင်း သင် ခန့်မှန်းနိုင်ပေမည်။ ဤကိစ္စတွင်၊ "pk" တန်ဖိုးသည် 0.5 ဖြစ်မည်ဖြစ်ပြီး G သည်လည်း 0.5 ဖြစ်လိမ့်မည်။
ဒေတာအချက်များအားလုံးကို အရွက်အဖြစ်ပြောင်းလဲပြီး အမျိုးအစားခွဲလိုက်သောအခါ ခွဲခြမ်းခြင်းလုပ်ငန်းစဉ်ကို ရပ်ဆိုင်းလိုက်ပါသည်။ သို့သော် သင်သည် သစ်ပင်ကြီးထွားမှုကို စောစီးစွာ ရပ်တန့်ချင်ပေမည်။ ကြီးမားရှုပ်ထွေးသောသစ်ပင်များသည် အလွန်အကျုံးဝင်နိုင်သော်လည်း ၎င်းကို တိုက်ဖျက်ရန် မတူညီသောနည်းလမ်းများစွာကို အသုံးပြုနိုင်သည်။ အရွက်တစ်ခုဖန်တီးရန် အသုံးပြုမည့် အနည်းဆုံးဒေတာအချက်အရေအတွက်ကို သတ်မှတ်ရန်မှာ အလွန်အကျွံ အံဝင်ခွင်ကျမှုကို လျှော့ချရန် နည်းလမ်းတစ်ခုဖြစ်သည်။ အံဝင်ခွင်ကျမဖြစ်စေရန် ထိန်းချုပ်ခြင်း၏ နောက်ထပ်နည်းလမ်းတစ်ခုမှာ အပင်၏ အမြစ်မှ အရွက်တစ်ခုအထိ လမ်းကြောင်းမည်မျှကြာအောင် ဆန့်နိုင်သည်ကို ထိန်းချုပ်သည့် အမြင့်ဆုံးအတိမ်အနက်တစ်ခုအထိ ကန့်သတ်ထားသည်။
ဆုံးဖြတ်ချက်သစ်ပင်များ ဖန်တီးခြင်းတွင် ပါ၀င်သည့် နောက်လုပ်ငန်းစဉ်တစ်ခု တံစဉ်များ။ တံစဉ်များဖြတ်ခြင်းသည် မော်ဒယ်အတွက် ကြိုတင်ခန့်မှန်းနိုင်သော ပါဝါအနည်းငယ်/အရေးပါမှု အနည်းငယ်ပါရှိသော အကိုင်းအခက်များပါရှိသော အကိုင်းအခက်များကို ဖယ်ထုတ်ခြင်းဖြင့် ဆုံးဖြတ်ချက်သစ်ပင်၏ စွမ်းဆောင်ရည်ကို တိုးမြင့်လာစေနိုင်သည်။ ဤနည်းအားဖြင့် သစ်ပင်၏ ရှုပ်ထွေးမှု လျော့နည်းသွားသည်၊ ၎င်းသည် အံကိုက်ဖြစ်နိုင်ခြေနည်းလာပြီး မော်ဒယ်၏ ကြိုတင်ခန့်မှန်းနိုင်မှု တိုးလာပါသည်။
တံစဉ်များကိုလုပ်ဆောင်သောအခါ၊ လုပ်ငန်းစဉ်သည် သစ်ပင်၏ထိပ် သို့မဟုတ် သစ်ပင်အောက်ခြေတွင် စတင်နိုင်သည်။ သို့သော် အလွယ်ဆုံးနည်းမှာ အရွက်မှအစပြု၍ ထိုအရွက်အတွင်းတွင် အသုံးအများဆုံးအတန်းများပါရှိသော node ကို ချရန်ကြိုးစားခြင်းဖြစ်သည်။ မော်ဒယ်၏ တိကျမှုမှာ ၎င်းကို ပြီးမြောက်သောအခါတွင် ဆိုးရွားခြင်းမရှိပါက၊ အပြောင်းအလဲကို ထိန်းသိမ်းထားသည်။ တံစဉ်များကို ဖြတ်တောက်ရာတွင် အသုံးပြုသည့် အခြားသော နည်းလမ်းများ ရှိသော်လည်း အထက်တွင် ဖော်ပြထားသော နည်းလမ်း - အမှားအယွင်း လျှော့ချ တံစဉ်းခြင်း - သည် သစ်ပင် တံစဉ်များကို ဖြတ်တောက်ခြင်း၏ အဆုံးအဖြတ်ပေးသည့် နည်းလမ်း ဖြစ်နိုင်သည်။
ဆုံးဖြတ်ချက်သစ်ပင်များကို အသုံးပြုရန်အတွက် ထည့်သွင်းစဉ်းစားမှုများ
ဆုံးဖြတ်ချက်သစ်ပင်များ မကြာခဏအသုံးဝင်သည်။ အမျိုးအစားခွဲခြားရန် လိုအပ်သော်လည်း တွက်ချက်ချိန်သည် အဓိကကန့်သတ်ချက်ဖြစ်သည်။ ဆုံးဖြတ်ချက်သစ်များသည် ရွေးချယ်ထားသော ဒေတာအတွဲများတွင် မည်သည့်အင်္ဂါရပ်များက ကြိုတင်ခန့်မှန်းနိုင်သော စွမ်းအားကို အများဆုံးကိုင်ဆောင်ထားသည်ကို ရှင်းလင်းစေနိုင်သည်။ ထို့အပြင်၊ ဒေတာကို အမျိုးအစားခွဲရာတွင် အသုံးပြုသည့် စည်းမျဉ်းများသည် အနက်ဖွင့်ရန်ခက်ခဲသော စက်သင်ယူမှု algorithms အများအပြားနှင့်မတူဘဲ၊ ဆုံးဖြတ်ချက်သစ်များသည် အဓိပ္ပာယ်ဖွင့်ဆိုနိုင်သော စည်းမျဉ်းများကို ထုတ်ပေးနိုင်သည်။ Decision tree များသည် အမျိုးအစားအလိုက် နှင့် စဉ်ဆက်မပြတ် variable များကို အသုံးပြုနိုင်သည့်အပြင် အဆိုပါ variable အမျိုးအစားများထဲမှ တစ်ခုကိုသာ ကိုင်တွယ်နိုင်သော algorithms များနှင့် နှိုင်းယှဉ်ပါက ကြိုတင်လုပ်ဆောင်မှု နည်းပါးကြောင်း ဆိုလိုသည်။
စဉ်ဆက်မပြတ် attribute များ၏တန်ဖိုးများကိုဆုံးဖြတ်ရန်အသုံးပြုသောအခါ ဆုံးဖြတ်ချက်သစ်များသည် ကောင်းစွာလုပ်ဆောင်လေ့မရှိပေ။ ဆုံးဖြတ်ချက်သစ်ပင်၏နောက်ထပ်ကန့်သတ်ချက်မှာ၊ အမျိုးအစားခွဲခြင်းလုပ်ဆောင်သောအခါ၊ လေ့ကျင့်ရေးနမူနာအနည်းငယ်ရှိသော်လည်း အတန်းများစွာသည် ဆုံးဖြတ်ချက်သစ်ပင် မှားယွင်းနေတတ်သည်။










