
AI ၅၀
Linear Regression ဆိုတာ ဘာလဲ။
Linear Regression ဆိုတာ ဘာလဲ။
Linear regression သည် ခန့်မှန်းရန် သို့မဟုတ် မြင်ယောင်ရန် အသုံးပြုသည့် algorithm တစ်ခုဖြစ်သည်။ မတူညီသော အင်္ဂါရပ်များ/ကိန်းရှင်နှစ်ခုကြား ဆက်စပ်မှု. linear regression tasks တွင်၊ variable နှစ်မျိုးကို ဆန်းစစ်နေသည်- the dependent variable နှင့် independent variable များ. အမှီအခိုကင်းသော ကိန်းရှင်သည် အခြားကိန်းရှင်မှ သက်ရောက်မှုမရှိသော သူ့အလိုလိုရပ်တည်သော ကိန်းရှင်ဖြစ်သည်။ အမှီအခိုကင်းသော ကိန်းရှင်အား ချိန်ညှိလိုက်သည်နှင့်အမျှ၊ မှီခိုနေသောကိန်းရှင်၏ အဆင့်များသည် အတက်အကျရှိပါမည်။ မှီခိုကိန်းရှင်သည် လေ့လာနေသည့် ကိန်းရှင်ဖြစ်ပြီး ၎င်းသည် ကြိုတင်ခန့်မှန်းရန် ကြိုးစားမှုများအတွက် ဆုတ်ယုတ်မှုပုံစံက ဖြေရှင်းပေးသည့်အရာဖြစ်သည်။ linear regression လုပ်ဆောင်ချက်များတွင်၊ ရှုမြင်မှု/ဥပမာတိုင်းတွင် မှီခိုကိန်းရှင်တန်ဖိုးနှင့် အမှီအခိုကင်းသော ကိန်းရှင်တန်ဖိုးနှစ်ခုလုံးပါဝင်သည်။
၎င်းသည် linear regression ၏ လျင်မြန်သော ရှင်းလင်းချက်ဖြစ်သည်၊ သို့သော် ၎င်းကို နမူနာတစ်ခုကြည့်ကာ ၎င်းကိုအသုံးပြုသည့်ဖော်မြူလာကို စစ်ဆေးခြင်းဖြင့် linear regression အကြောင်းကို ပိုမိုကောင်းမွန်စွာနားလည်လာကြောင်း သေချာပါစေ။
Linear Regression ကို နားလည်ခြင်း။
ကျွန်ုပ်တို့တွင် ဟာ့ဒ်ဒရိုက်အရွယ်အစားများနှင့် ထိုဟာ့ဒ်ဒရိုက်များ၏ ကုန်ကျစရိတ်များပါရှိသော ဒေတာအတွဲတစ်ခုရှိသည်ဟု ယူဆပါ။
ကျွန်ုပ်တို့တွင်ရှိသော ဒေတာအတွဲတွင် မမ်မိုရီပမာဏနှင့် ကုန်ကျစရိတ်ဟူ၍ မတူညီသော အင်္ဂါရပ်နှစ်ခုဖြင့် ပါဝင်သည်ဟု ဆိုကြပါစို့။ ကွန်ပြူတာတစ်လုံးအတွက် Memory များများဝယ်လေ၊ ဝယ်ယူမှုကုန်ကျစရိတ်က ပိုတက်လေပါပဲ။ အကယ်၍ ကျွန်ုပ်တို့သည် ဖြန့်ကျက်ကွက်တစ်ခုတွင် ဒေတာအချက်အလတ်များကို ပုံဖော်ပါက၊ ဤကဲ့သို့သော ပုံသဏ္ဌာန်ရှိသော ဂရပ်တစ်ခုကို ကျွန်ုပ်တို့ ရရှိနိုင်ပါသည်။

တိကျသော memory-to-cost အချိုးသည် ထုတ်လုပ်သူနှင့် ဟာ့ဒ်ဒရိုက်များ၏ မော်ဒယ်များကြားတွင် ကွဲပြားနိုင်သော်လည်း ယေဘူယျအားဖြင့်၊ ဒေတာ၏လမ်းကြောင်းသည် ဘယ်ဘက်အောက်ခြေမှ စတင်သည် (ဟာ့ဒ်ဒရိုက်များသည် စျေးသက်သာပြီး စွမ်းဆောင်ရည်ပိုသေးငယ်သည့်) သို့ ရွေ့လျားသည်။ ညာဘက်အပေါ်ပိုင်း ( drives တွေက ပိုစျေးကြီးပြီး စွမ်းရည်ပိုမြင့်တဲ့ နေရာမှာ)
အကယ်၍ ကျွန်ုပ်တို့တွင် X-axis တွင် memory ပမာဏရှိပြီး Y-axis တွင် ကုန်ကျစရိတ်ရှိပါက၊ X နှင့် Y variables များကြားရှိ ဆက်နွယ်မှုကို ဖမ်းယူသည့် မျဉ်းတစ်ကြောင်းသည် ဘယ်ဘက်အောက်ထောင့်မှ စတင်ပြီး ညာဘက်အပေါ်ဘက်သို့ လည်ပတ်မည်ဖြစ်သည်။
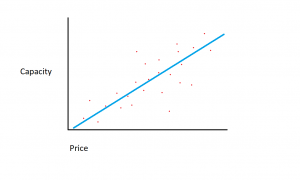
ဆုတ်ယုတ်မှုပုံစံတစ်ခု၏လုပ်ဆောင်ချက်မှာ ကိန်းရှင်နှစ်ခုကြားရှိ ဆက်နွယ်မှုကို အကောင်းဆုံးဖော်ပြသည့် X နှင့် Y ကိန်းရှင်များကြား မျဉ်းနားလုပ်ဆောင်မှုကို ဆုံးဖြတ်ရန်ဖြစ်သည်။ linear regression တွင်၊ input variable များပေါင်းစပ်မှုမှ Y ကို တွက်ချက်နိုင်သည်ဟု ယူဆပါသည်။ input variables (X) နှင့် target variables (Y) အကြား ဆက်စပ်မှုကို ဂရပ်ရှိ အမှတ်များမှတဆင့် မျဉ်းတစ်ကြောင်းဆွဲခြင်းဖြင့် ပုံဖော်နိုင်ပါသည်။ မျဉ်းသည် X နှင့် Y အကြား ဆက်နွယ်မှုကို အကောင်းဆုံးဖော်ပြသည့် လုပ်ဆောင်ချက်ကို ကိုယ်စားပြုသည် (ဥပမာ၊ X တိုးလာတိုင်း၊ Y သည် 3 တိုးလာသည်)။ ရည်မှန်းချက်မှာ အကောင်းဆုံး "ဆုတ်ယုတ်မှုမျဉ်း" သို့မဟုတ် ဒေတာနှင့် အသင့်တော်ဆုံး လိုင်း/လုပ်ဆောင်ချက်ကို ရှာဖွေရန်ဖြစ်သည်။
မျဉ်းများကို ညီမျှခြင်းအားဖြင့် ကိုယ်စားပြုသည်- Y = m*X + b။ X သည် Y သည် အမှီအခိုကင်းသော ကိန်းရှင်ဖြစ်ပြီး၊ မှီခိုကိန်းရှင်ကို ရည်ညွှန်းသည်။ ဤအတောအတွင်း၊ m သည် မျဉ်းကြောင်း၏ လျှောစောက်၊ "ထခြင်း" မှ "ပြေးခြင်း" ကို ကျော်တက်ခြင်းဟု သတ်မှတ်သည်။ စက်သင်ယူမှု လေ့ကျင့်သူများသည် ဤညီမျှခြင်းအစား ဤညီမျှခြင်းကို အသုံးပြု၍ နာမည်ကျော် slope-line equation ကို အနည်းငယ်ကွဲပြားစွာ ကိုယ်စားပြုသည်-
y(x) = w0 + w1 * x
အထက်ပါညီမျှခြင်းတွင် y သည် ပစ်မှတ်ကိန်းရှင်ဖြစ်ပြီး “w” သည် မော်ဒယ်၏ ဘောင်များဖြစ်ပြီး ထည့်သွင်းမှုမှာ “x” ဖြစ်သည်။ ထို့ကြောင့် ညီမျှခြင်းအား “X ပေါ်မူတည်၍ Y ပေးသော လုပ်ဆောင်ချက်သည် အင်္ဂါရပ်များဖြင့် မြှောက်ထားသော မော်ဒယ်များ၏ ကန့်သတ်ချက်များနှင့် ညီမျှသည်” ဟူ၍ ဖြစ်သည်။ အသင့်တော်ဆုံး ဆုတ်ယုတ်မှုမျဉ်းကို ရရှိရန် လေ့ကျင့်ချိန်အတွင်း မော်ဒယ်၏ ဘောင်များကို ချိန်ညှိထားသည်။
Multiple Linear Regression

ဓာတ်ပုံ- Cbaf မှတဆင့် Wikimedia Commons၊ အများသူငှာ Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
အထက်တွင်ဖော်ပြထားသော လုပ်ငန်းစဉ်သည် ရိုးရှင်းသောမျဉ်းကြောင်းအတိုင်း ဆုတ်ယုတ်ခြင်း သို့မဟုတ် အင်္ဂါရပ်တစ်ခုတည်းသာ/အမှီအခိုကင်းသော ကိန်းရှင်တစ်ခုသာရှိသည့် ဒေတာအတွဲများပေါ်တွင် ဆုတ်ယုတ်ခြင်းများနှင့် သက်ဆိုင်ပါသည်။ သို့သော်၊ ဆုတ်ယုတ်မှုအား အင်္ဂါရပ်များစွာဖြင့် လုပ်ဆောင်နိုင်သည်။ ဖြစ်လာခဲ့လျှင် "multiple linear regression”၊ ဒေတာအတွဲအတွင်း တွေ့ရှိသော ကိန်းရှင်အရေအတွက်ဖြင့် ညီမျှခြင်းကို တိုးချဲ့သည်။ တစ်နည်းဆိုရသော် ပုံမှန် linear regression အတွက် equation သည် y(x) = w0 + w1 * x ဖြစ်ပြီး၊ multiple linear regression အတွက် equation သည် y(x) = w0 + w1x1 အပေါင်း အမျိုးမျိုးသော အင်္ဂါရပ်များအတွက် အလေးနှင့် inputs များ ဖြစ်လိမ့်မည်။ w(n)x(n) အဖြစ် အလေးနှင့်အင်္ဂါရပ် စုစုပေါင်း အရေအတွက်ကို ကိုယ်စားပြုပါက၊ ဤကဲ့သို့သော ဖော်မြူလာကို ကိုယ်စားပြုနိုင်သည်-
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
မျဉ်းကြောင်းပြန်ဆုတ်ခြင်းအတွက် ဖော်မြူလာကို တည်ထောင်ပြီးနောက်၊ စက်သင်ယူမှုမော်ဒယ်သည် အလေးချိန်များအတွက် မတူညီသောတန်ဖိုးများကို အသုံးပြုမည်ဖြစ်ပြီး တူညီသောမျဉ်းကြောင်းများကို ရေးဆွဲမည်ဖြစ်သည်။ ပန်းတိုင်သည် ဒေတာနှင့် ကိန်းရှင်များကြား ဆက်စပ်မှုကို ရှင်းပြရန်အတွက် ဖြစ်နိုင်ခြေရှိသော အလေးချိန် ပေါင်းစပ်မှုများ (ထို့ကြောင့် ဖြစ်နိုင်ခြေရှိသော မျဉ်း) ကို ဆုံးဖြတ်ရန်အတွက် ပန်းတိုင်မှာ ဒေတာနှင့် အကိုက်ညီဆုံး လိုင်းကို ရှာဖွေရန်ဖြစ်သည်ကို သတိရပါ။
သတ်မှတ်ထားသောအလေးချိန်တန်ဖိုးတစ်ခုပေးသောအခါတွင် ယူဆရသည့် Y တန်ဖိုးများသည် အမှန်တကယ် Y တန်ဖိုးများနှင့် မည်မျှနီးကပ်သည်ကို တိုင်းတာရန်အတွက် ကုန်ကျစရိတ်လုပ်ဆောင်ချက်ကို အသုံးပြုသည်။ ကုန်ကျစရိတ်က function ပါ။ linear regression အတွက်ဆိုလိုသည်မှာ နှစ်ထပ်ကိန်းအမှားဖြစ်ပြီး၊ ခန့်မှန်းထားသောတန်ဖိုးနှင့် dataset ရှိ အမျိုးမျိုးသောဒေတာအမှတ်အားလုံးအတွက် စစ်မှန်သောတန်ဖိုးအကြား ပျမ်းမျှ (စတုရန်း) အမှားကို ယူဆောင်သည်။ ခန့်မှန်းထားသော ပစ်မှတ်တန်ဖိုးနှင့် စစ်မှန်သော ပစ်မှတ်တန်ဖိုးကြား ကွာခြားချက်ကို ဖမ်းယူပေးသည့် ကုန်ကျစရိတ်ကို တွက်ချက်ရန် ကုန်ကျစရိတ်လုပ်ဆောင်ချက်ကို အသုံးပြုပါသည်။ အံဝင်ခွင်ကျမျဉ်းသည် ဒေတာအချက်များနှင့် ဝေးနေပါက၊ ကုန်ကျစရိတ် ပိုများလာမည်ဖြစ်ပြီး၊ ကိန်းရှင်များကြားမှ စစ်မှန်သော ဆက်ဆံရေးကို ဖမ်းယူရန် စာကြောင်းသည် ပိုမိုနီးကပ်လာသည်နှင့်အမျှ ကုန်ကျစရိတ်သည် ပိုမိုသေးငယ်လာမည်ဖြစ်သည်။ ထို့နောက် မော်ဒယ်၏ အလေးချိန်များသည် အမှားအယွင်းအနည်းဆုံးပမာဏကို ထုတ်ပေးသည့် အလေးချိန်ဖွဲ့စည်းမှုပုံစံကို မတွေ့မချင်း ချိန်ညှိသည်။










