AI 101
強化学習とは何か?
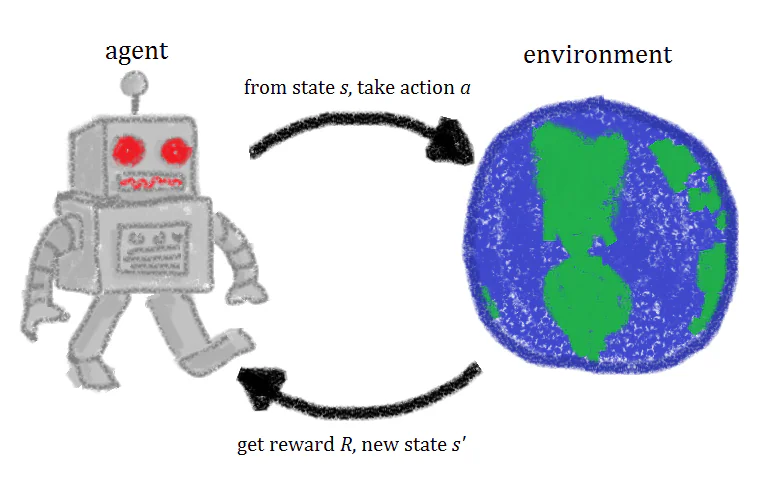
強化学習とは何か?
簡単に言えば、強化学習とは、行動とそれに伴う報酬の繰り返しを通じて人工知能エージェントを訓練する機械学習の手法です。強化学習エージェントは環境内で実験を行い、行動を起こし、正しい行動が取られたときに報酬を受け取ります。時間の経過とともに、エージェントは報酬を最大化する行動を取ることを学習します。これが強化学習の簡潔な定義ですが、強化学習の背後にある概念を詳しく見ることで、より良い直感的な理解を得ることができます。 「強化学習」という用語は、心理学における強化の概念から適応されたものです。そのため、まずは心理学における強化の概念を理解する時間を取りましょう。心理学的な意味では、「強化」という用語は、特定の反応/行動が起こる可能性を高めるものを指します。この強化の概念は、心理学者B.F.スキナーによって最初に提唱されたオペラント条件付け理論の中核的な考え方です。この文脈では、強化とは、与えられた行動の頻度を増加させるあらゆるものを指します。人間にとっての可能な強化を考えてみると、それは称賛、仕事での昇給、キャンディ、楽しい活動などが挙げられます。 伝統的な心理学的な意味では、強化には2つのタイプがあります。正の強化と負の強化です。正の強化は、行動を増加させるために何かを追加することです。例えば、犬が行儀よくしたときにご褒美を与えるようなものです。負の強化は、行動を引き出すために刺激を取り除くことです。例えば、臆病な猫を誘い出すために大きな音を消すようなものです。
正の強化と負の強化
正の強化は行動の頻度を増加させ、負の強化は行動の頻度を減少させます。一般的に、強化学習で使用される最も一般的な強化のタイプは正の強化です。なぜなら、それはモデルが与えられたタスクでパフォーマンスを最大化するのに役立つからです。それだけでなく、正の強化はモデルにより持続可能な変化をもたらし、その変化は一貫したパターンとなり、長期間持続することができます。 対照的に、負の強化も行動が起こりやすくしますが、それはモデルの最大パフォーマンスに到達するためではなく、最低限のパフォーマンス基準を維持するために使用されます。強化学習における負の強化は、モデルが望ましくない行動から遠ざけられることを保証するのに役立ちますが、モデルに望ましい行動を探索させることはできません。
強化学習エージェントの訓練
強化学習エージェントを訓練する際には、訓練に4つの異なる要素または状態が使用されます:初期状態(状態0)、新しい状態(状態1)、行動、そして報酬です。 例えば、AIの目標が画面を右に移動してレベルの最後まで到達することであるプラットフォームビデオゲームをプレイする強化学習エージェントを訓練していると想像してください。ゲームの初期状態は環境から抽出されます。つまり、ゲームの最初のフレームが分析され、モデルに与えられます。この情報に基づいて、モデルは行動を決定しなければなりません。 訓練の初期段階では、これらの行動はランダムですが、モデルが強化されるにつれて、特定の行動がより一般的になります。行動が取られた後、ゲームの環境が更新され、新しい状態(フレーム)が作成されます。エージェントが取った行動が望ましい結果(例えば、この場合、エージェントがまだ生きていて敵に攻撃されていない)を生み出した場合、エージェントに何らかの報酬が与えられ、将来同じことをする可能性が高くなります。 この基本的なシステムは常にループされ、何度も何度も繰り返され、そのたびにエージェントはもう少し学習し、報酬を最大化しようとします。
エピソード的タスクと連続的タスク
強化学習タスクは通常、2つの異なるカテゴリのいずれかに分類できます:エピソード的タスクと連続的タスクです。 エピソード的タスクは、学習/訓練ループを実行し、何らかの終了基準が満たされて訓練が終了するまでパフォーマンスを向上させ続けます。ゲームでは、それはレベルの終わりに到達することや、トゲなどの危険に落ちることかもしれません。対照的に、連続的タスクには終了基準がなく、基本的にはエンジニアが訓練を終了することを選択するまで永遠に訓練を続けます。
モンテカルロ法と時間的差分法
強化学習エージェントを学習(訓練)する主な方法には2つあります。モンテカルロ法では、報酬は訓練エピソードの終了時にのみエージェントに与えられます(スコアが更新されます)。言い換えれば、終了条件が満たされたときにのみ、モデルは自分がどれだけうまくやったかを学習します。モデルはこの情報を使って更新し、次の訓練ラウンドが開始されると、新しい情報に従って反応します。 時間的差分法は、モンテカルロ法とは異なり、価値推定(スコア推定)が訓練エピソードの過程で更新されます。モデルが次のタイムステップに進むと、値が更新されます。
探索と活用
強化学習エージェントの訓練は、2つの異なる指標、探索と活用のバランスを取る行為です。 探索とは、周囲の環境についてより多くの情報を収集する行為であり、活用とは、環境について既知の情報を使用して報酬ポイントを獲得することです。エージェントが探索だけを行い、環境を活用しない場合、望ましい行動は決して実行されません。一方、エージェントが活用だけを行い、探索をしない場合、エージェントは1つの行動を実行することを学習するだけで、報酬を獲得する他の可能な戦略を発見しません。したがって、強化学習エージェントを作成する際には、探索と活用のバランスを取ることが重要です。
強化学習のユースケース
強化学習は非常に多様な役割で使用でき、タスクの自動化を必要とするアプリケーションに最適です。 産業用ロボットによって実行されるタスクの自動化は、強化学習が有用である領域の一つです。強化学習は、長文を要約できるモデルを作成するといった、テキストマイニングのような問題にも使用できます。研究者たちはまた、医療分野で強化学習を使用する実験を行っており、治療方針の最適化などの仕事を強化学習エージェントに処理させています。強化学習は、学生向けの教育教材をカスタマイズするためにも使用できる可能性があります。
強化学習のまとめ
強化学習は、印象的で時には驚くべき結果をもたらすAIエージェントを構築する強力な方法です。強化学習を通じてエージェントを訓練することは、多くの訓練イテレーションと探索/活用の二分法の繊細なバランスを必要とするため、複雑で困難な場合があります。しかし、成功すれば、強化学習で作成されたエージェントは、さまざまな異なる環境下で複雑なタスクを実行することができます。








