人工知能
MoE 革命: 先進的なルーティングと専門化が LLM を変革する方法
数年で、巨大な言語モデル (LLM) は数百万から数百億のパラメータに拡大し、私たちが巨大な AI システムを設計し、拡大する能力の驚くべき進歩を示しています。これらの巨大なシステムは、流暢なテキストの作成、コードの生成、複雑な問題の推論、人間のような会話など、驚くべき能力を実現しています。しかし、この急速な拡大は、重大なコストを伴います。巨大なモデルのトレーニングと実行には、計算能力、エネルギー、資本の大量が必要です。「大きい方がいい」という戦略が一度は進歩を促進しましたが、その限界が明らかになってきました。これらの制約に対応して、Mixture of Experts (MoE) という AI アーキテクチャが、巨大な言語モデルを拡大するためのより賢く、効率的な方法を提供するために進化しています。巨大な常にアクティブなネットワークに依存するのではなく、MoE はモデルを、特定の種類のデータやタスクに特化したサブネットワークまたは「エキスパート」のコレクションに分割します。インテリジェントなルーティングを通じて、モデルは各入力に対して最も関連性の高いエキスパートのみをアクティブ化し、計算オーバーヘッドを削減しながらパフォーマンスを維持または向上させます。この拡大性と効率性の組み合わせは、MoE を AI の最も重要な新興パラダイムの 1 つにします。この記事では、先進的なルーティングと専門化がどのように変革を推進し、インテリジェント システムの将来に何を意味するかを探ります。
コア アーキテクチャの理解
Mixture of Experts (MoE) の概念は新しいものではありません。1990 年代のアンサンブル ラーニング法に遡ります。何が変わったのかというと、実現可能にする技術です。最近のハードウェアとルーティング アルゴリズムの進歩によって、現代の Transformer ベースの言語モデルにこの概念を導入することが実用的になりました。
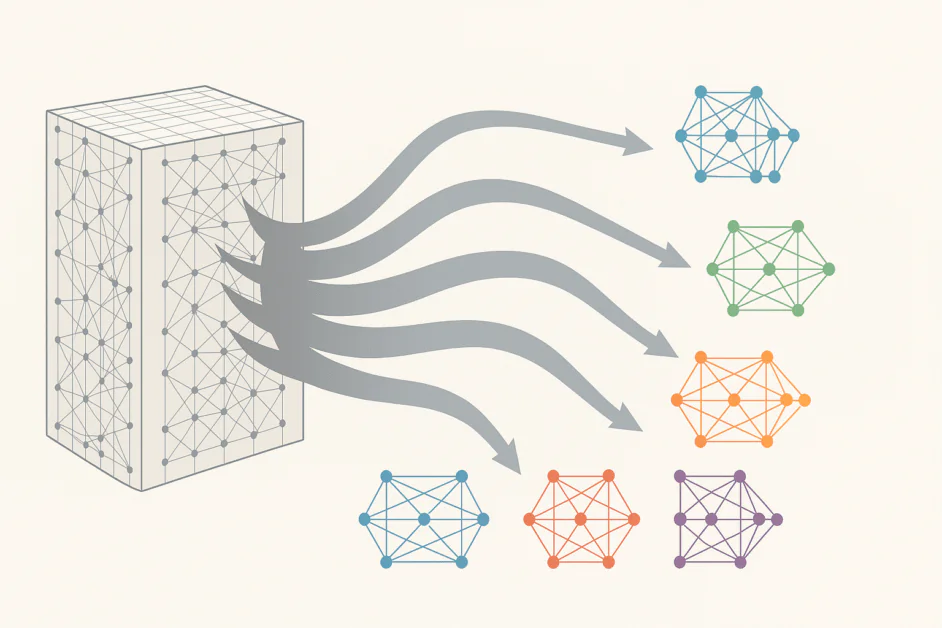
その本質では、MoE は大きなニューラル ネットワークを、特定の種類のデータやタスクに特化した小さなサブネットワークのコレクションとして再定義します。各パラメータをすべての入力に対してアクティブ化するのではなく、MoE は、どのエキスパートが特定のトークンまたはシーケンスに対して最も関連性があるかを決定するルーティング メカニズムを導入します。結果として、モデルは任意の時点でパラメータの小さな部分のみを使用し、計算要求を劇的に削減しながらパフォーマンスを維持または向上させます。
実践では、このアーキテクチャの変化により、研究者は、計算リソースの比例的な増加を必要とせずに、モデルを数兆のパラメータに拡大することができます。従来の密なフィードフォワード層を、より賢く、ダイナミックなシステムに置き換えます。各 MoE 層には、複数のエキスパート (通常は小さなフィードフォワード ネットワーク) と、各入力の処理にどのエキスパートを使用するかを決定するルーターまたはゲート ネットワークが含まれます。ルーターはプロジェクト マネージャーのように動作し、関連する質問を各エキスパートに送信します。時間の経過とともに、システムは、さまざまな種類の問題に対してどのエキスパートが最もよく機能するかを学習し、トレーニング中にルーティング戦略を改良します。
この設計は、拡大性と効率性の驚くべき組み合わせを提供します。たとえば、MoE モデルの 1 つである DeepSeek V3 は、685 億のパラメータを使用していますが、推論中にこれらのパラメータの小さな部分のみをアクティブ化します。大量モデルと同等のパフォーマンスを実現しながら、計算とエネルギーの要件を大幅に削減します。
ルーティング メカニズムの進化
ルーターは MoE の核心であり、各入力に対してどのエキスパートを使用するかを決定します。初期のモデルは、学習された重みに基づいてトップ 2 または 3 のエキスパートを選択するという単純な戦略を使用しました。現代のシステムははるかに洗練されています。
今日のダイナミック ルーティング メカニズムは、入力の複雑さに応じてアクティブ化されるエキスパートの数を調整します。単純な質問には 1 つのエキスパートのみが必要かもしれませんが、難しい推論タスクには複数のエキスパートをアクティブ化する必要があります。DeepSeek-V2 では、分散ハードウェア全体の通信コストを制御するデバイス制限ルーティングを実装しました。DeepSeek-V3 では、パフォーマンスの低下なしにエキスパートの特化をさらに高めることができる、補助損失のない戦略を導入しました。
先進的なルーターは、入力の特性、ネットワークの深さ、またはリアルタイムのパフォーマンス フィードバックに基づいて選択戦略を調整する、インテリジェントなリソース マネージャーとして機能します。いくつかの研究者は、長期的なタスクのパフォーマンスを最適化するために、強化学習を探究しています。ソフト ゲート テクニックを使用すると、エキスパートの選択がよりスムーズになり、確率的なディスパッチングは、割り当てを最適化するために統計的手法を使用します。
専門化がパフォーマンスを促進する
MoE の中心的な約束は、深い専門化が広い汎用性を上回るということです。各エキスパートは、すべてのことが中途半端になるのではなく、特定のドメインをマスターすることに集中します。トレーニング中に、ルーティング メカニズムは一貫して、特定の入力の種類を特定のエキスパートに向け、強力なフィードバック ループを作成します。いくつかのエキスパートはコーディングに優れていますが、他のエキスパートは医療用語や創造的な文章作成に優れています。
しかし、この目標を達成することは課題を伴います。伝統的な負荷分散アプローチは、エキスパートの使用を均一にすることで、実際には専門化を妨げる可能性があります。ただし、この分野は急速に進化しています。研究によると、細粒な MoE モデルは明確な専門化を示し、異なるエキスパートがそれぞれのドメインで優れています。研究も、ルーティング メカニズムがこのアーキテクチャの分業に積極的な役割を果たしていることを確認しています。
ドメイン キー エキスパートを使用する戦略は、注目に値するパフォーマンスの改善を示しています。たとえば、研究者は、AIME2024 ベンチマークで 3.33 パーセントの精度の向上を報告しました。専門化が機能する場合、結果は驚くべきものです。DeepSeek V3 は、ほとんどの自然言語ベンチマークで GPT-4o を上回り、すべてのコーディングと数学的推論タスクでリードしています。これは、オープンソース モデルにとって重要なマイルストーンです。
モデル機能への実用的な影響
MoE 革命は、コア モデル機能の実用的な改善をもたらしています。モデルは、より効率的に長いコンテキストを処理することができます。DeepSeek V3 と GPT-4o の両方は、単一の入力で 128K トークンを処理でき、MoE アーキテクチャは特に技術的なドメインでのパフォーマンスを最適化します。これは、コードベース全体を分析したり、長い法律文書を処理したりするアプリケーションにとって非常に重要です。
コスト効率の改善はさらに劇的にです。分析によると、DeepSeek-V3 は、GPT-4o と比較して約 29.8 倍コスト効率が高いと推定されています。この価格差は、先進的な AI をより幅広いユーザーとアプリケーションにアクセス可能にします。AI の民主化を大幅に加速します。
さらに、アーキテクチャはより持続可能な展開を可能にします。MoE モデルのトレーニングには依然として大量のリソースが必要ですが、推論コストの劇的な削減は、AI企業とその顧客にとって、より効率的で経済的に実行可能なモデルへの道を開きます。
課題と前進する道
MoE には、重要な利点がありますが、課題もあります。トレーニングは不安定になり、エキスパートが意図したように専門化しないことがあります。初期のモデルは、「ルーティングの崩壊」と呼ばれる問題に苦労しました。ここで、1 つのエキスパートが優勢になります。すべてのエキスパートが適切なトレーニング データを受け取ることを保証する必要がありますが、サブセットのみがアクティブです。ルーティング メカニズムのバランスをとることが重要です。
最も重大なボトルネックは、通信オーバーヘッドです。分散 GPU セットアップでは、通信コストが処理時間の最大 77% を占める可能性があります。多くのエキスパートは「過度にコラボレーション」しており、頻繁に一緒にアクティブ化され、ハードウェア アクセラレータ間で繰り返しデータ転送を強制します。これは、AI ハードウェアの設計を見直す必要性を生み出しています。
メモリの要求も大きな課題です。MoE は推論中に計算コストを削減しますが、すべてのエキスパートをメモリに読み込む必要があり、エッジ デバイスやリソースが限られている環境ではメモリを圧迫します。解釈可能性も重要な課題です。どのエキスパートが特定の出力に貢献したかを特定することは、アーキテクチャにさらに複雑性を加えます。研究者は、エキスパートのアクティブ化を追跡し、意思決定パスを視覚化する方法を探究し、MoE システムをより透明性が高く、監査が容易なものにしようとしています。
まとめ
Mixture of Experts パラダイムは、新しいアーキテクチャではありません。新しい哲学です。インテリジェントなルーティングとドメイン レベルの専門化を組み合わせることで、MoE は、拡大性と計算量のトレードオフを実現します。安定性、通信、解釈可能性の課題が残っていますが、そのバランスは、より賢く、適応性に優れ、精度の高い AI システムの未来を示唆しています。












