人工知能
SofGAN: 顔生成のためのGANで、より大きな制御を提供する
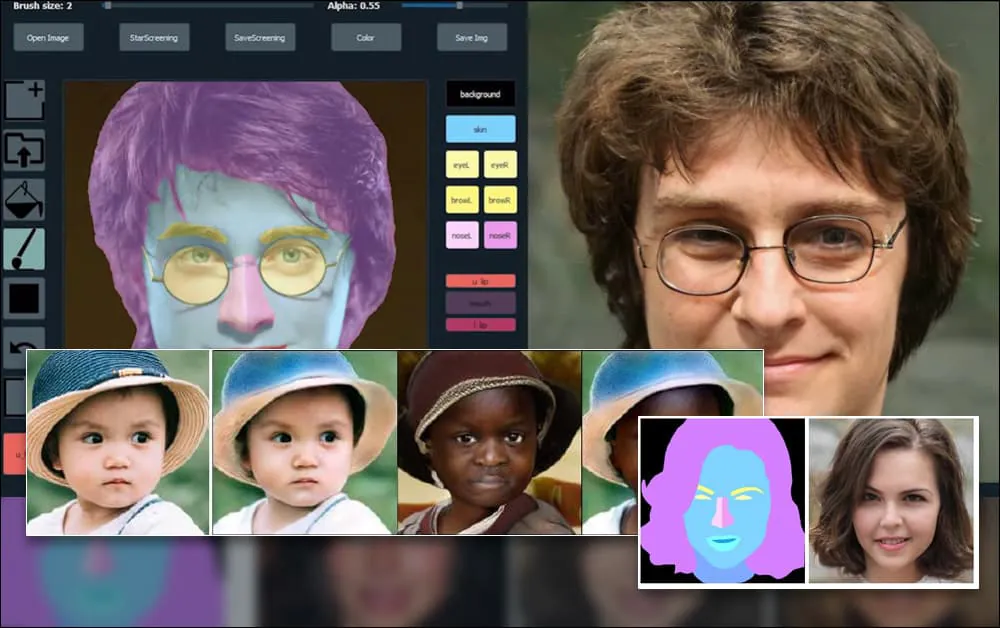
上海と米国の研究者は、個々の要素 such as hair, eyes, glasses, textures and color に対する以前になかったレベルの制御を提供する、GANベースのポートレート生成システムを開発しました。
このシステムの汎用性を示すために、クリエイターはPhotoshopスタイルのインターフェイスを提供しており、ユーザーは直接、セマンティックセグメンテーション要素を描くことができ、実際の画像として解釈され、既存の写真の上に直接描くこともできます。
以下の例では、俳優Daniel Radcliffeの写真がトレーシングテンプレートとして使用されています(目的は彼に似たものを生成することではなく、一般的に写実的な画像を生成することです)。ユーザーがさまざまな要素、例えば眼鏡などを入力すると、それらは識別され、出力画像に解釈されます:
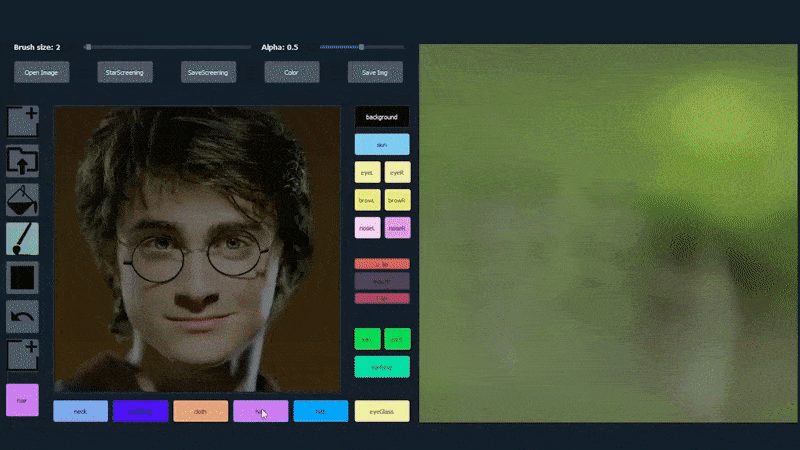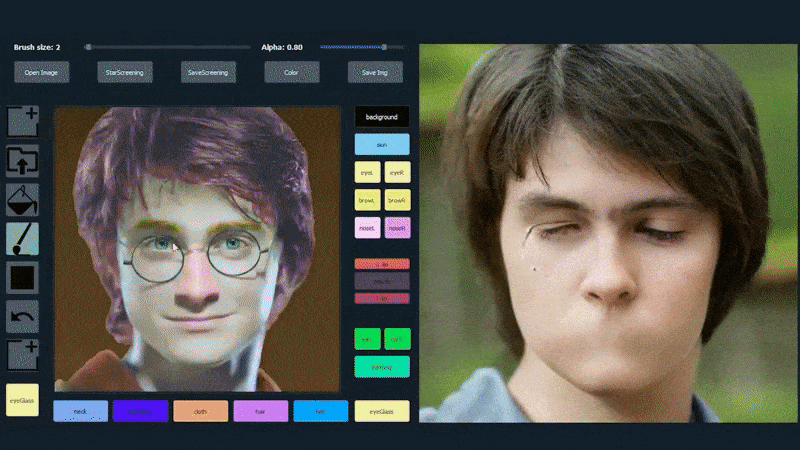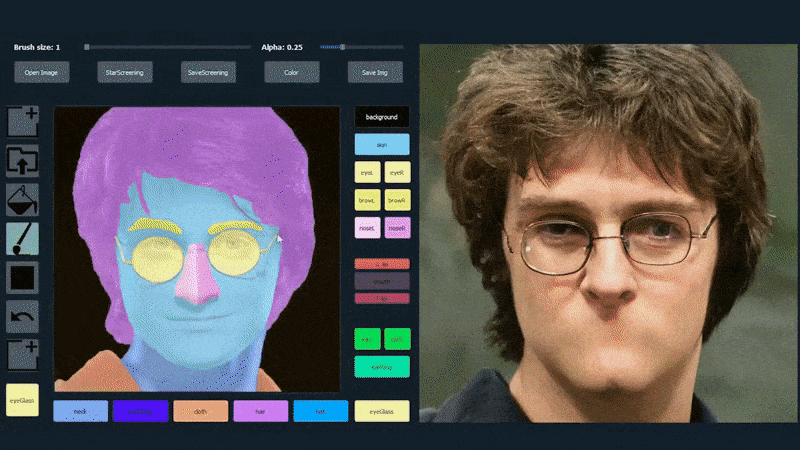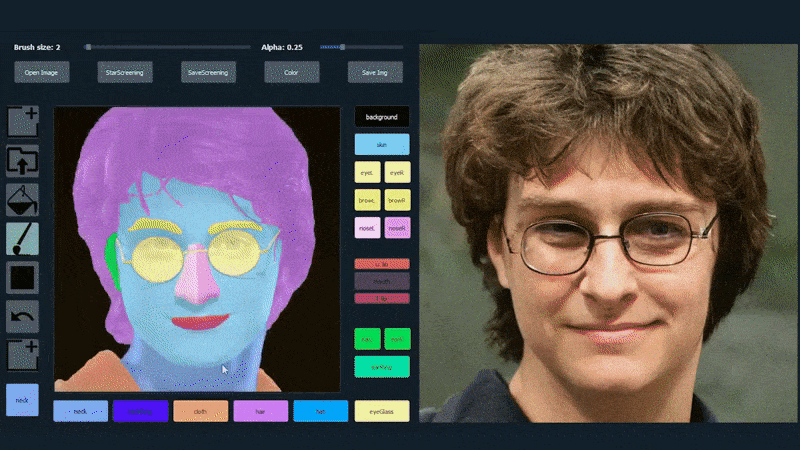
一つの画像をトレーシング素材として使用したSofGAN生成のポートレート Source: https://www.youtube.com/watch?v=xig8ZA3DVZ8
論文は、SofGAN: A Portrait Image Generator with Dynamic Stylingと題され、Anpei ChenとRuiyang Liuのほか、上海科技大学とカリフォルニア大学サンディエゴ校の研究者2名が参加しています。
特徴の分離
この研究の主な貢献は、ユーザーフレンドリーなUXを提供することではなく、学習された顔の特徴、例えばポーズやテクスチャーを「分離」することです。これにより、SofGANはカメラの視点から間接的な角度の顔を生成することもできます。

Generative Adversarial Networksベースの顔生成器の中で珍しい、SofGANはトレーニングデータに含まれる角度の範囲内で、任意の角度を変更できます。 Source: https://arxiv.org/pdf/2007.03780.pdf
テクスチャーがジオメトリーから分離されたため、顔の形状とテクスチャーを個別のエンティティとして操作することもできます。実際、 этоにより、顔の肌の色を変更することができます。 有害な行為ですが、医療用データセットのバランスをとるためには有用な応用例となります。

SofGANは、NVIDIAのGauGANやIntelのゲームベースのニューラルレンダリングシステムなどのセグメンテーション>画像システムと比較して、人工的な老化や属性一致スタイル調整を、より詳細なレベルでサポートしています。

SofGANは、老化をイテレーティブスタイルとして実装することができます。
SofGANの方法論のもう一つのブレークスルーは、トレーニングがペアードセグメンテーション/実画像を必要としないということです。代わりに、実世界の画像のみで直接トレーニングすることができます。
研究者は、SofGANの「分離」アーキテクチャは、伝統的な画像レンダリングシステムからインスピレーションを得たもので、画像の個々の要素を分解するものであると述べています。ビジュアルエフェクトのワークフローでは、コンポジットの要素は最も小さなコンポーネントまで分解され、各コンポーネントに専門家が割り当てられます。
セマンティック占有フィールド(SOF)
このことを達成するために、研究者は、伝統的な占有フィールドの拡張である、セマンティック占有フィールド(SOF)を開発しました。これは、顔のポートレートのコンポーネント要素を個別化します。SOFは、校正されたマルチビューのセマンティックセグメンテーションマップでトレーニングされましたが、グラウンドトゥルースの監視は行われませんでした。

単一のセグメンテーションマップ(左下)からの複数のイテレーション。
さらに、2Dセグメンテーションマップは、SOFの出力からレイマーチングによって取得され、GANジェネレーターによってテクスチャ化されます。「合成」セマンティックセグメンテーションマップは、視点の変更時に出力の連続性を確保するために、3層のエンコーダーを介して低次元空間に符号化されます。
トレーニングスキームは、各セマンティック領域に対して2つのランダムなスタイルを空間的に混合します:

SofGANのアーキテクチャ
研究者は、SofGANが、Frechet Inception Distance(FID)が現在の最先端アプローチよりも低く、Learned Perceptual Image Patch Similarity(LPIPS)メトリックが高いと主張しています。
以前のStyleGANアプローチは、特徴のエンタングルメントによって頻繁に妨げられてきました。ここで、画像を構成する要素は、互いに切り離せないものとなってしまい、望ましい要素とともに、望ましくない要素が現れることがあります(例えば、耳の形がトレーニング時に耳環の付いた画像で学習された場合、耳の形をレンダリングするときに耳環が現れることがあります)。

レイマーチングは、セマンティックセグメンテーションマップの体積を計算するために使用され、複数の視点を可能にします。
データセットとトレーニング
SofGANの開発には、3つのデータセットが使用されました:CelebAMask-HQ、30,000の高解像度画像が含まれるCelebA-HQデータセットのリポジトリ;NVIDIAのFlickr-Faces-HQ(FFHQ)、70,000の画像が含まれており、研究者が事前にトレーニングされた顔パーサーで画像にラベルを付けています;そして、セマンティック領域が手動でラベル付けされた122のポートレートスキャンからなる、独自のグループ。
SOFは、3つのトレーニング可能なサブモジュールから構成されています:ハイパーネット、レイマーチャー(上の画像参照)、クラシファイアー。プロジェクトのSemantic Instance Wised(SIW)StyleGANジェネレーターは、StyleGAN2と同様に構成されています。データ増強は、ランダムなスケーリングとクロッピングを介して適用され、トレーニングでは4ステップごとにパス正則化が行われます。トレーニングプロセッド全体は、4つのRTX 2080 Ti GPUとCUDA 10.1を使用して22日間で800,000イテレーションに達しました。
研究者は、一般化された、高レベルの結果がトレーニングの早い段階で現れ始めたと述べています。1500イテレーション、3日目のトレーニングで、結果はすでに現れ始めていました。トレーニングの残りの部分は、髪や目のような細かい詳細を取得するために、ゆっくりと進みました。
SofGANは、単一のセグメンテーションマップから、NVIDIAのSPADEやPix2PixHD、およびSEANなどのライバル手法よりも、より現実的な結果を達成します。

以下は、研究者が公開したビデオです。さらに、プロジェクトページでホストされているビデオも利用可能です。












