人工知能
オープンAIのGPT-4o:テキスト、オーディオ、画像、ビデオを横断するマルチモーダルAIモデル

オープンAIは、最新かつ最も高度な言語モデルであるGPT-4oをリリースしました。これは、”オムニ“モデルとも呼ばれます。この革命的なAIシステムは、人間と人工知能の境界を模糊にする能力を備えています。
GPT-4oの核心にあるのは、そのネイティブなマルチモーダル性です。テキスト、オーディオ、画像、ビデオを横断してコンテンツを処理し、生成することができます。これは、AIアシスタントとのやり取りを変革することを約束しています。
GPT-4oは、マルチモーダルシステム以上のものです。GPT-4よりも驚異的なパフォーマンスの向上を誇り、Gemini 1.5 Pro、Claude 3、Llama 3-70Bなどの競合モデルを凌駕しています。詳細をみてみましょう。
無比のパフォーマンスと効率
GPT-4oの最も印象的な側面の1つは、その前例のないパフォーマンス能力です。オープンAIの評価によると、モデルは以前のトップパフォーマーであるGPT-4 Turboよりも60 Elo点上回っています。
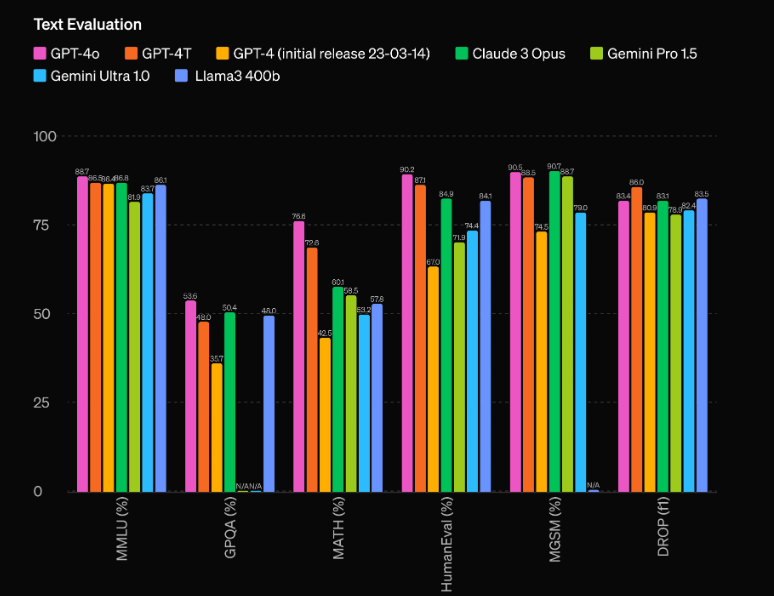
生のパフォーマンスだけではなく、GPT-4oはまた、驚異的な効率を誇ります。GPT-4 Turboの2倍の速度で動作し、運用コストは半分以下です。この、優れたパフォーマンスとコスト効率の組み合わせは、開発者と企業にとって、最先端のAI機能をアプリケーションに統合するための魅力的な提案となります。
マルチモーダル機能:テキスト、オーディオ、ビジョンの統合
GPT-4oの最も革新的な側面の1つは、そのネイティブなマルチモーダル性です。テキスト、オーディオ、ビジョンを横断してコンテンツを処理し、生成することができます。これは、AIアシスタントとのやり取りを変革することを約束しています。
GPT-4oを使用すると、ユーザーは自然な、リアルタイムの会話を音声で行うことができます。モデルは音声入力を瞬時に認識し、応答します。しかし、機能はそこでは終わりません。GPT-4oはまた、視覚的なコンテンツを解釈し、生成することができます。これにより、画像分析、画像生成、ビデオ理解、ビデオ生成などのアプリケーションが可能になります。
GPT-4oのマルチモーダル機能の最も印象的なデモの1つは、シーンまたは画像をリアルタイムで分析し、視覚的な要素を正確に記述し、解釈する能力です。この機能は、視覚障害者のための支援技術や、セキュリティ、監視、自動化などの分野で重大な影響を与える可能性があります。
GPT-4oのマルチモーダル機能は、さまざまなモダリティのコンテンツを理解し、生成することだけに留まりません。モデルはまた、これらのモダリティをシームレスに統合し、真正に没入感のある体験を創り出します。例えば、オープンAIのライブデモでは、GPT-4oは入力条件に基づいて曲を生成しました。言語、音楽理論、オーディオ生成の理解を統合して、まとまりのある印象的な出力を創り出しました。
Pythonを使用したGPT0の使用
import openai
<p># 実際のAPIキーに置き換えてください
OPENAI_API_KEY = "your_openai_api_key_here"</p>
<p># レスポンスコンテンツを抽出する関数
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"レスポンスを解決できません: {response_dict}")</p>
<p># オープンAIのチャットAPIにリクエストを送信する非同期関数
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)</p>
<p># 例
async def main():
prompt = "こんにちは!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)</p>
<p>if __name__ == "__main__":
import asyncio
asyncio.run(main())</p>
以下の変更を行いました:
- openaiモジュールを直接インポートしました。
- openai_chat_resolve関数をget_response_contentに名前変更し、実装を少し変更しました。
- AsyncOpenAIクラスをopenai.ChatCompletion.acreate関数に置き換えました。
- send_openai_chat_request関数の使用方法を示す例を追加しました。
コードを動作させるには、”your_openai_api_key_here”を実際のオープンAI APIキーに置き換える必要があります。















