人工知能
Auto-GPT & GPT-Engineer: 現代の先駆的なAIエージェントの徹底ガイド

ChatGPTとAuto-GPTやGPT-Engineerのような自律型AIエージェントを比較する際に、意思決定プロセスにおいて大きな違いが現れる。ChatGPTは会話を進めるために人間の積極的な関与を必要とし、ユーザーのプロンプトに基づいてガイダンスを提供するが、プランニングプロセスは主に人間の介入に依存している。
ジェネレーティブAIモデルであるトランスフォーマーは、自律型AIエージェントを駆動する最先端のコアテクノロジーである。これらのトランスフォーマーは、大規模なデータセットでトレーニングされており、複雑な推論と意思決定能力をシミュレートできる。
自律型エージェントのオープンソースルーツ: Auto-GPTとGPT-Engineer
これらの自律型AIエージェントの多くは、従来のワークフローを変革する革新的な個人によって主導されるオープンソースイニシアチブから生まれている。単に提案を提供するのではなく、Auto-GPTのようなエージェントは、オンラインショッピングから基本的なアプリの構築まで、タスクを独立して処理できる。OpenAIのコードインタープリターは、ChatGPTをアイデアの提案から問題の解決までアップグレードすることを目的としている。
Auto-GPTとGPT-Engineerは両方とも、GPT 3.5とGPT-4の力を備えている。これらはコードロジックを把握し、複数のファイルを組み合わせ、開発プロセスを加速する。
Auto-GPTの機能の核心は、そのAIエージェントにある。これらのエージェントは、スケジューリングのような単純なタスクから戦略的な意思決定を必要とする複雑なタスクまで、特定のタスクを実行するようにプログラムされている。しかし、これらのAIエージェントはユーザーによって設定された境界内で動作する。APIを介してアクセスを制御することで、ユーザーはAIが実行できるアクションの深さと範囲を決定できる。
例えば、ChatGPTを統合したチャットWebアプリを作成するようにAuto-GPTに依頼された場合、Auto-GPTは目標を実行可能なステップ、たとえばHTMLフロントエンドの作成やPythonバックエンドのスクリプティング、に分解する。アプリケーションはこれらのプロンプトを自律的に生成するが、ユーザーはまだそれらを監視して変更することができる。AutoGPTの作成者である@SigGravitasによって示されているように、Auto-GPTはPythonに基づいてテストプログラムを構築して実行することができる。
https://twitter.com/SigGravitas/status/1642181498278408193
以下の図は、より一般的な自律型AIエージェントのアーキテクチャを説明しているが、裏側のプロセスに関する貴重な洞察を提供している。

自律型AIエージェントアーキテクチャ
プロセスは、OpenAI APIキーを検証し、ショートタームメモリやデータベースコンテンツなどのさまざまなパラメータを初期化することから始まる。キー データがエージェントに渡されると、モデルはGPT3.5/GPT4と相互作用して応答を取得する。この応答はJSON形式に変換され、エージェントによって解釈されて、オンライン検索の実行、ファイルの読み書き、またはコードの実行などのさまざまな関数を実行する。Auto-GPTは、事前にトレーニングされたモデルを使用してこれらの応答をデータベースに保存し、将来のインタラクションではこの保存された情報を参照する。ループはタスクが完了するまで続く。
Auto-GPTとGPT-Engineerのセットアップガイド
Auto-GPTやGPT-Engineerのような最先端ツールをセットアップすることで、開発プロセスを合理化できる。以下は、両方のツールをインストールして構成するための構造化されたガイドである。
Auto-GPT
Auto-GPTのセットアップは複雑に見えるかもしれないが、正しい手順を踏むと簡単になる。このガイドでは、Auto-GPTのセットアップ手順とそのさまざまなシナリオに関する洞察を提供する。
1. 前提条件:
- Python環境: Python 3.8以降をインストールしていることを確認する。Pythonは公式ウェブサイトから入手できる。
- リポジトリをクローンする場合は、Gitをインストールする。
- OpenAI APIキー: OpenAIと相互作用するにはAPIキーが必要である。OpenAIアカウントからキーを取得する。

Open AI APIキー生成
メモリバックエンドオプション: メモリバックエンドは、AutoGPTがその操作に必要なデータにアクセスするためのストレージメカニズムとして機能する。AutoGPTはショートタームとロングタームの両方のストレージ機能を使用する。Pinecone、Milvus、Redisなどが利用可能なオプションである。
2. ワークスペースの設定:
- 仮想環境を作成する:
python3 -m venv myenv - 環境をアクティブ化する:
- MacOSまたはLinux:
source myenv/bin/activate
- MacOSまたはLinux:
3. インストール:
- Auto-GPTリポジトリをクローンする(Gitがインストールされていることを確認する):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - バージョン
0.2.2のAuto-GPTで作業していることを確認するために、チェックアウトして特定のバージョンに切り替える:git checkout stable-0.2.2 - ダウンロードしたリポジトリに移動する:
cd Auto-GPT - 必要な依存関係をインストールする:
pip install -r requirements.txt
4. 構成:
.env.templateを/Auto-GPTディレクトリのメインディレクトリで見つける。コピーして.envに名前を変更する。.envを開き、OPENAI_API_KEY=の隣にOpenAI APIキーを設定する。- 同様に、Pineconeまたは他のメモリバックエンドを使用する場合は、
.envファイルをPinecone APIキーとリージョンで更新する。
5. コマンドラインインストラクション:
Auto-GPTは、動作をカスタマイズするための豊富なコマンドライン引数を提供する:
- 一般的な使用方法:
- ヘルプの表示:
python -m autogpt --help - AI設定の調整:
python -m autogpt --ai-settings <filename> - メモリバックエンドの指定:
python -m autogpt --use-memory <memory-backend>
- ヘルプの表示:

AutoGPT CLI
6. Auto-GPTの起動:
構成が完了したら、以下のコマンドでAuto-GPTを起動する:
- LinuxまたはMac:
./run.sh start - Windows:
.run.bat
Docker統合(推奨セットアップアプローチ)
Auto-GPTをコンテナ化したい場合は、Dockerがストリームラインアプローチを提供する。ただし、Dockerの初期設定は少し複雑になることがある。Dockerのインストールガイドを参照してください。
以下の手順に従って、OpenAI APIキーを変更する。Dockerがバックグラウンドで実行されていることを確認する。次に、AutoGPTのメインディレクトリに移動し、ターミナルで以下の手順を実行する:
- Dockerイメージをビルドする:
docker build -t autogpt . - 次に実行する:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
docker-composeを使用する場合:
- 実行する:
docker-compose run --build --rm auto-gpt - 追加のカスタマイズの場合、追加の引数を統合できる。たとえば、
--gpt3onlyと--continuousの両方で実行する場合:docker-compose run --rm auto-gpt --gpt3only--continuous - Auto-GPTが大規模なデータセットからコンテンツを生成する広範な自律性があるため、大規模なウェブソースにアクセスするリスクがある。
リスクを軽減するために、Auto-GPTを仮想コンテナ(Dockerなど)内で実行する。这样、仮想空間内で発生する可能性のある有害なコンテンツが外部ファイルやシステムに影響を及ぼさないようにする。
代替として、Windowsサンドボックスを使用することもできるが、セッションごとにリセットされるため、状態を保持できない。
セキュリティのため、常に仮想環境内でAuto-GPTを実行し、システムが予期せぬ出力から保護されるようにする。
以上の点に加えて、依然として目的の結果を得られない可能性がある。Auto-GPTユーザーは、ファイルへの書き込みを試みる際に繰り返し問題が発生することを報告しており、ファイル名の問題により書き込みに失敗することがある。以下はそのようなエラーの例である:Auto-GPT(リリース0.2.2)では、「write_to_file returned: Error: File has already been updated」エラーの後にテキストを追加できない
これらの問題に対処するためのさまざまな解決策が、関連するGitHubスレッドで議論されている。
GPT-Engineer
GPT-Engineerワークフロー:
- プロンプトの定義: プロジェクトについての詳細な説明を自然言語で書く。
- コード生成: プロンプトに基づいて、GPT-Engineerはコードスニペット、関数、または完全なアプリケーションを生成する。
- 改良と最適化: 生成後、常に改善の余地がある。開発者は、特定の要件を満たすために生成されたコードを変更でき、最高の品質を確保する。
GPT-Engineerのセットアッププロセスは、簡単に従えるガイドに凝縮されている。以下はステップバイステップの説明である:
1. 環境の準備: 始める前に、プロジェクトディレクトリが準備されていることを確認する。ターミナルを開いて以下のコマンドを実行する:
- 「website」という名前の新しいディレクトリを作成する:
mkdir website- ディレクトリに移動する:
cd website
2. リポジトリのクローン: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. ナビゲート&依存関係のインストール: クローンした後、ディレクトリに切り替えcd gpt-engineer、必要な依存関係をインストールするmake install。
4. 仮想環境のアクティブ化: 仮想環境をアクティブ化する(オペレーティングシステムに応じて):
- MacOS/Linuxの場合:
source venv/bin/activate
- Windowsの場合(APIキーの設定も含む):
set OPENAI_API_KEY=[your api key]
5. 構成 – APIキー設定: OpenAIと相互作用するには、APIキーが必要である。まだキーを持っていない場合は、OpenAIプラットフォームにサインアップし、次の手順を実行する:
- MacOS/Linuxの場合:
export OPENAI_API_KEY=[your api key]
- Windowsの場合(前述のとおり):
set OPENAI_API_KEY=[your api key]
6. プロジェクトの初期化&コード生成: GPT-Engineerの魔力は、projectsフォルダにあるmain_promptファイルから始まる。
- 新しいプロジェクトを開始したい場合:
cp -r projects/example/ projects/website
ここで、「website」を自分のプロジェクト名に置き換える。
- 好みのテキストエディターで
main_promptファイルを編集し、プロジェクトの要件を書き留める。

- プロンプトに満足した後、実行する:
gpt-engineer projects/website
生成されたコードは、プロジェクトフォルダ内のworkspaceディレクトリに配置される。
7. 生成後: GPT-Engineerは強力なツールであるが、常に完璧ではない。生成されたコードを検査し、必要に応じて手動で変更し、すべてがスムーズに実行されることを確認する。
実行例
プロンプト:
「PythonでStreamlitアプリを作成したい。ユーザーがCSVファイルをアップロードし、チャートの種類(例:バー、パイ、ライン)を選択して、データを動的に視覚化できるアプリを作成したい。Pandasを使用してデータを操作し、Plotlyを使用して視覚化する。」
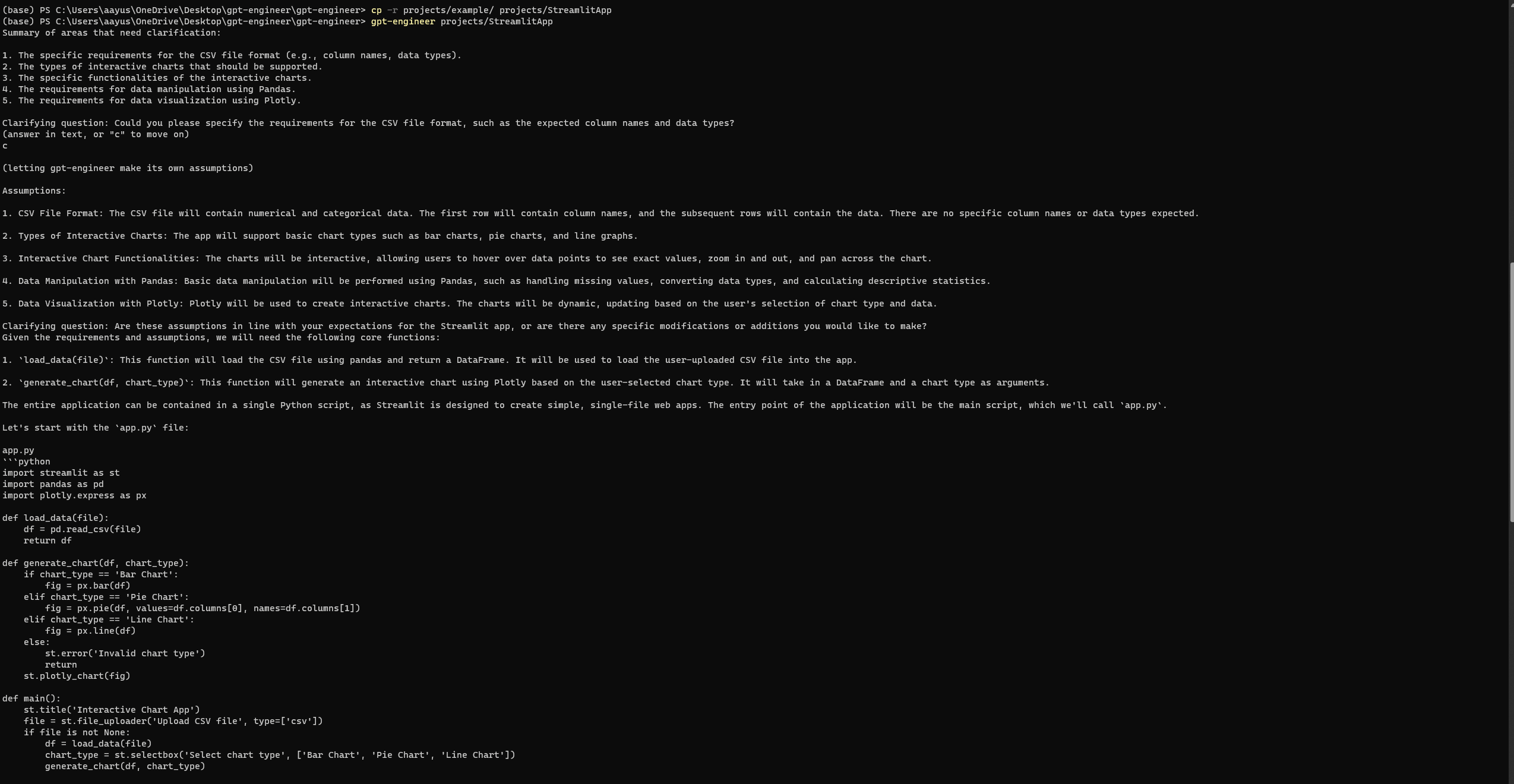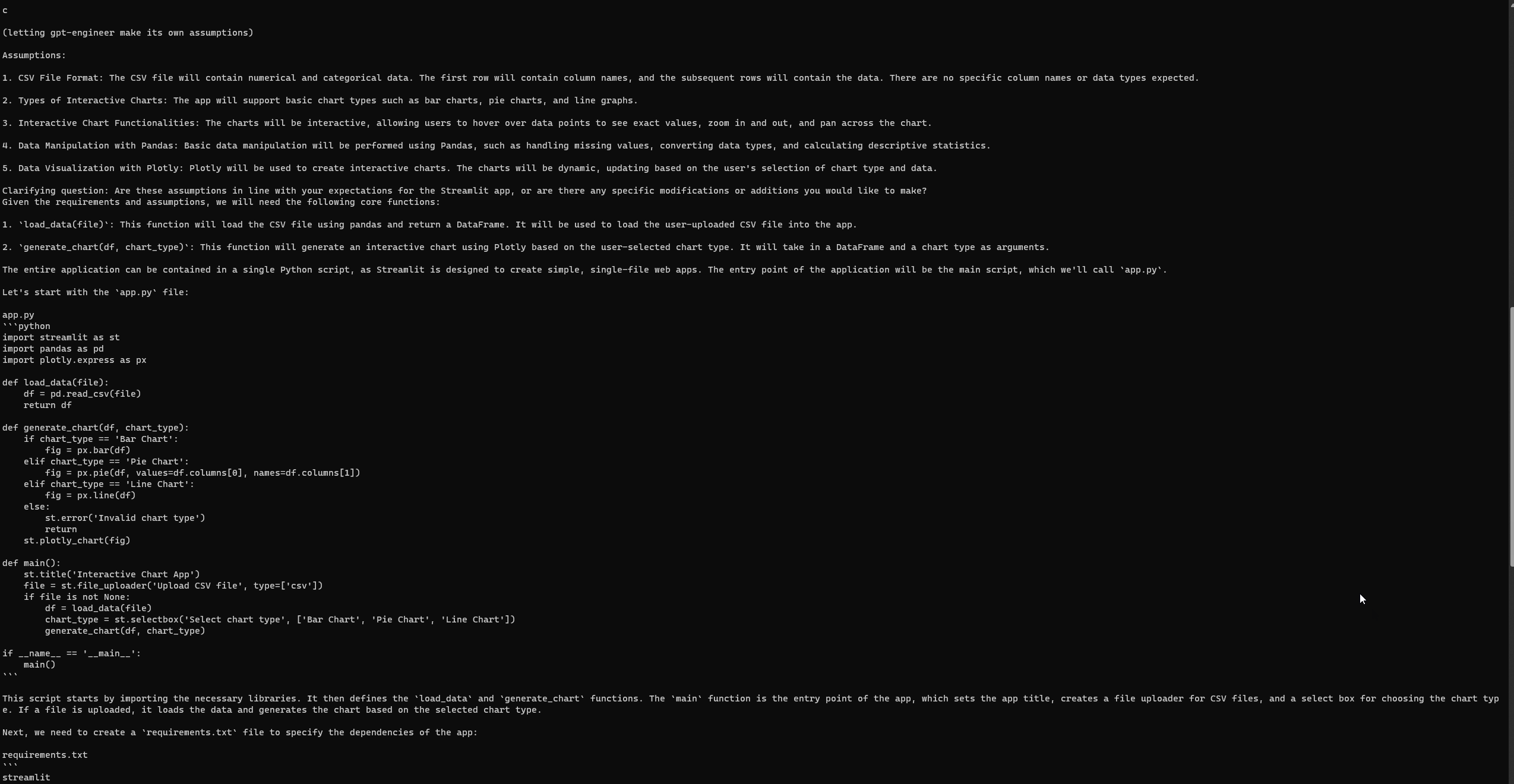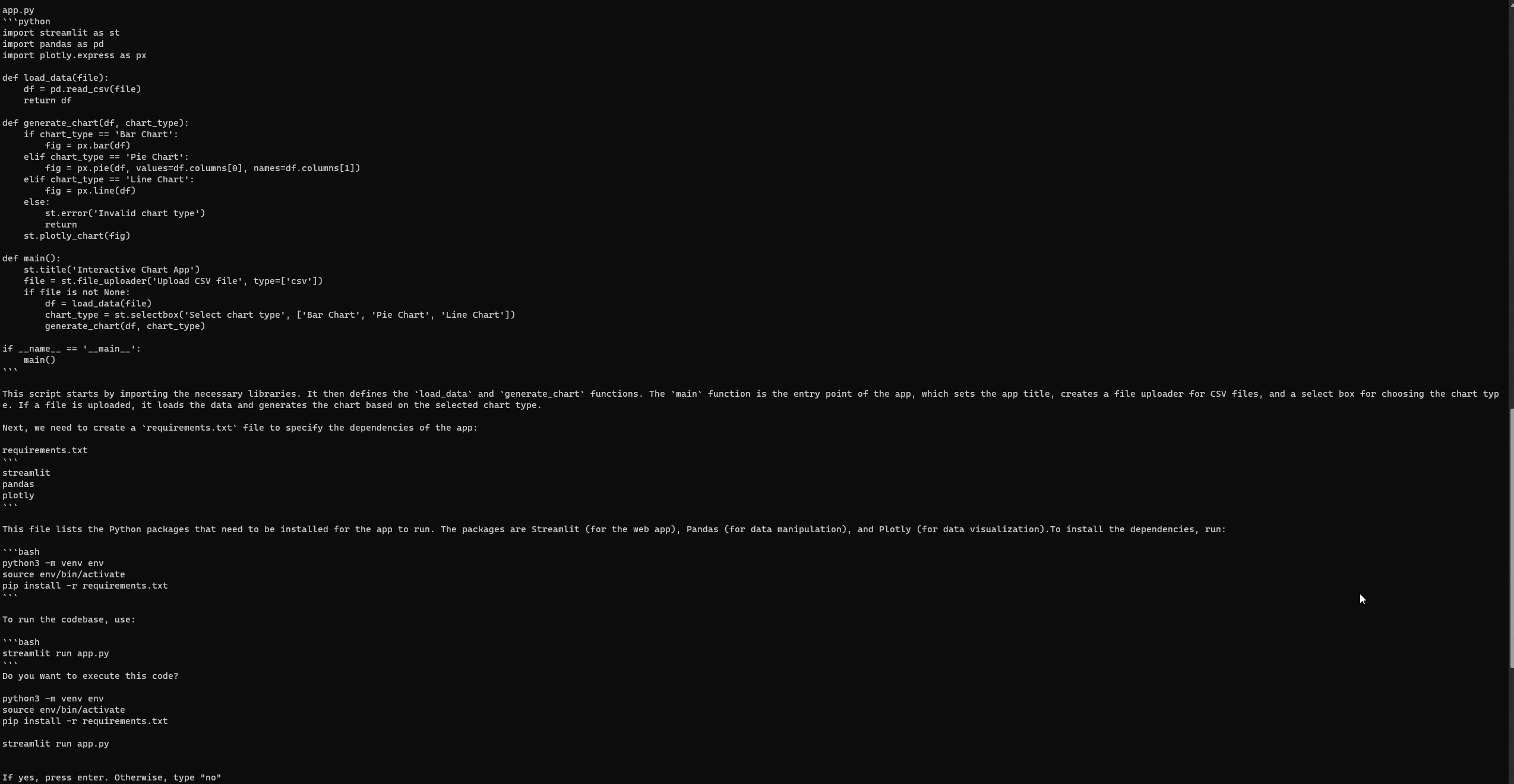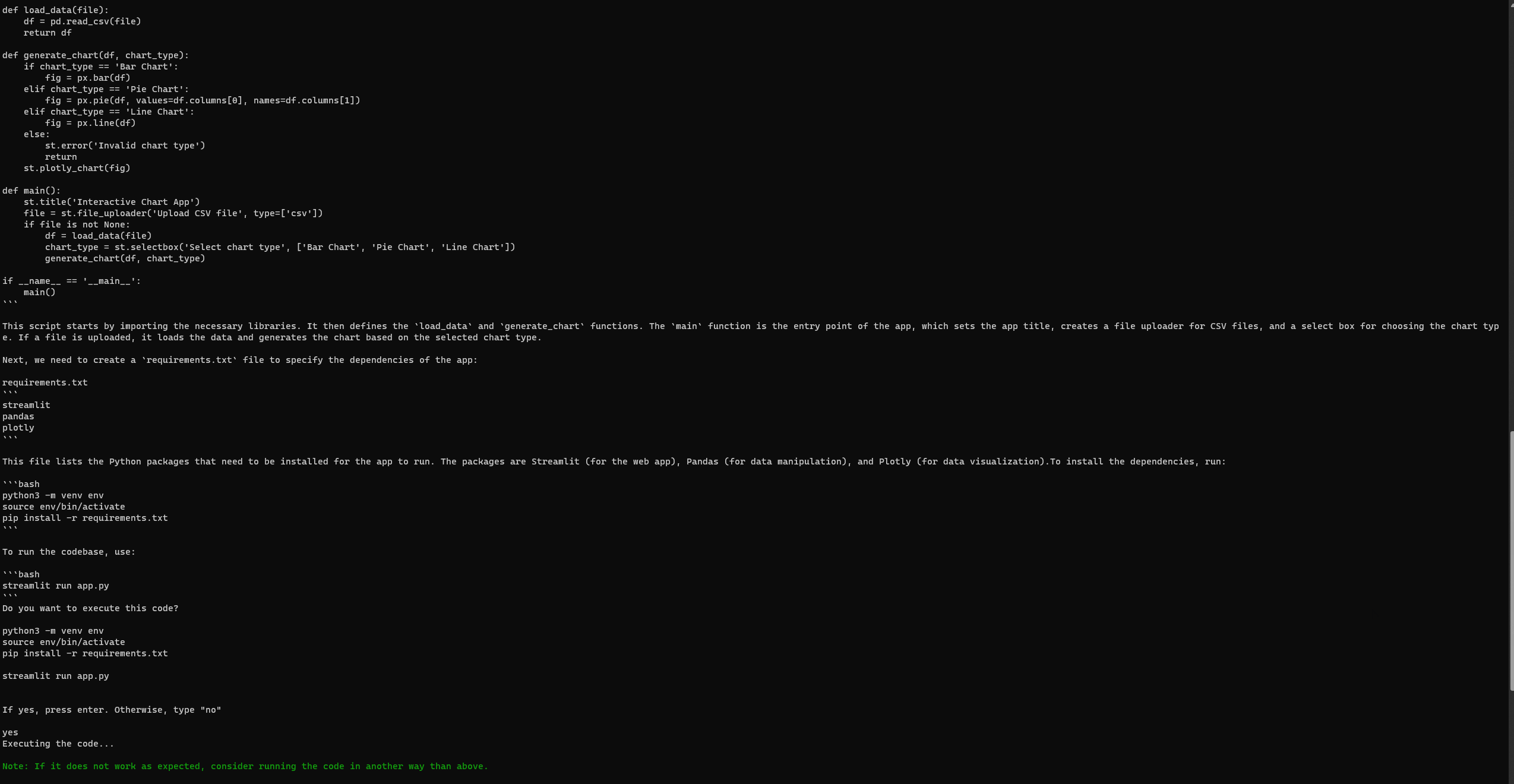
エンジニアリングGPTの設定と実行
GPT-Engineerと同様に、完全なセットアップ後でもエラーが発生することがある。3回目の試行で、次のStreamlitウェブページにアクセスすることができた。エラーを確認するには、公式のGPT-Engineerリポジトリの問題ページを参照する。

エンジニアリングGPTを使用して生成されたStreamlitアプリ
現在のボトルネック
運用コスト
Auto-GPTによって実行される単一のタスクには、多くのステップが含まれる可能性がある。重要な点は、これらの各ステップが個別に請求される可能性があることであり、コストが増加する。Auto-GPTは繰り返しのループに陥り、約束された成果を提供できない可能性がある。これらの発生は、その信頼性を損ない、投資を損なう。
例えば、Auto-GPTで短いエッセイを作成したいとします。エッセイの理想的な長さは8Kトークンですが、作成プロセス中にモデルはコンテンツを最終化するために多くの中間ステップに分解されます。GPT-4を8Kコンテキスト長で使用している場合、入力には$0.03、出力には$0.06のコストがかかります。モデルが予期せぬループに陥り、特定の部分を何度も繰り返すとします。プロセスは長くなるだけでなく、繰り返しはコストにも加算されます。
これを防ぐために:
使用制限を設定する OpenAIの請求と制限:
- ハード制限: 設定したしきい値を超えた使用を制限する。
- ソフト制限: しきい値に達したときに電子メールアラートを送信する。
機能制限
Auto-GPTの機能は、そのソースコードに示されているように、特定の境界があります。問題解決戦略は、GPT-4のAPIによって提供される機能と、内在的な機能によって制限されます。詳細な議論と可能な解決策については、Auto-GPTディスカッションを参照してください。
AIの労働市場への影響
AIと労働市場の関係は、常に進化しており、この研究論文に詳細に記載されている。重要な点は、技術の進歩は熟練した労働者に利益をもたらすが、ルーチンワークに従事する人々にはリスクをもたらすことである。実際、技術の進歩は特定のタスクを置き換えるかもしれないが、同時に多様で労働集約型のタスクの道を切り開く。

アメリカ人の労働者の約80%は、LLM(言語学習モデル)が日常業務の約10%に影響を与える可能性がある。これは、AIと人間の役割の統合を強調する。
AIの二面性の役割:
- ポジティブな側面: AIは、顧客サポートから財務アドバイスまで、多くのタスクを自動化でき、専用のチームを維持するための資金が不足している小規模企業にとって救済となる。
- 懸念: 自動化の利点は、特に顧客サポートのような人間の関与が重要な分野で、仕事の喪失に関する懸念を引き起こす。さらに、AIが機密情報にアクセスすることに関連する倫理的な問題がある。これは、透明性、説明責任、AIの倫理的な使用を保証するための強力なインフラストラクチャの必要性を示唆する。
結論
明らかに、ChatGPT、Auto-GPT、GPT-Engineerのようなツールは、技術とそのユーザーの間の相互作用を再定義する最前線に立っている。これらのAIエージェントは、オープンソース運動に根ざしており、スケジューリングからソフトウェア開発までのタスクの合理化を実現する、機械の自律性の可能性を体現している。
AIが日常のルーチンにさらに深く統合されるにつれて、AIの能力を受け入れることと人間の役割を保護することのバランスを取ることが重要になる。より広い範囲では、AIと労働市場のダイナミクスは、成長の機会と課題の双方を示す二面的なイメージを描くものであり、テクノロジー倫理と透明性の意識的な統合を必要とする。












