IA 101
Che cos’è l’Overfitting?
Che cos’è l’Overfitting?
Quando si addestra una rete neurale, è necessario evitare l’overfitting. L’overfitting è un problema all’interno dell’apprendimento automatico e della statistica in cui un modello apprende i modelli di un set di dati di addestramento troppo bene, spiegando perfettamente il set di dati di addestramento ma fallendo nel generalizzare il suo potere predittivo ad altri set di dati.
Per dirlo in un altro modo, nel caso di un modello con overfitting, spesso si verifica un’accuratezza estremamente alta sul set di dati di addestramento, ma un’accuratezza bassa sui dati raccolti e eseguiti nel modello in futuro. Questa è una definizione rapida di overfitting, ma esaminiamo il concetto di overfitting in maggior dettaglio. Vediamo come si verifica l’overfitting e come può essere evitato.
Comprendere “Fit” e Underfitting
È utile esaminare il concetto di underfitting e “fit” in generale quando si discute di overfitting. Quando addestriamo un modello, stiamo cercando di sviluppare un framework in grado di prevedere la natura o la classe degli elementi all’interno di un set di dati, in base alle caratteristiche che descrivono tali elementi. Un modello dovrebbe essere in grado di spiegare un modello all’interno di un set di dati e prevedere le classi dei punti di dati futuri in base a questo modello. Quanto meglio il modello spiega la relazione tra le caratteristiche del set di addestramento, tanto più “adatto” è il nostro modello.

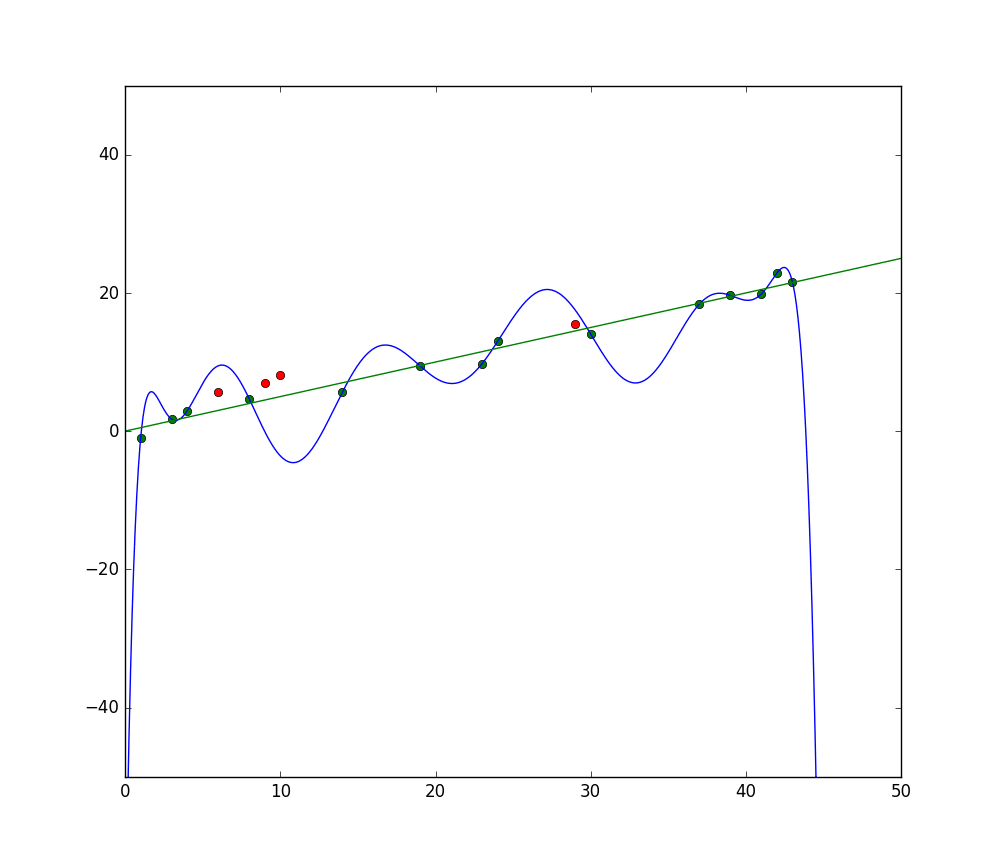
La linea blu rappresenta le previsioni di un modello che sta sotto-adattando, mentre la linea verde rappresenta un modello con un adattamento migliore. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ACnia.svg)
Un modello che spiega male la relazione tra le caratteristiche dei dati di addestramento e quindi non riesce a classificare correttamente i dati futuri è un modello con underfitting. Se si graficasse la relazione prevista di un modello con underfitting contro i valori effettivi, le previsioni si discosterebbero dal segno. Se avessimo un grafico con i valori effettivi di un set di addestramento etichettati, un modello con underfitting grave mancherebbe molti dei punti di dati. Un modello con un adattamento migliore potrebbe seguire un percorso attraverso i punti di dati, con i singoli punti di dati che si discostano solo leggermente dai valori previsti.
L’underfitting può verificarsi spesso quando non ci sono dati sufficienti per creare un modello accurato o quando si tenta di progettare un modello lineare con dati non lineari. Ulteriori dati di addestramento o ulteriori caratteristiche spesso aiutano a ridurre l’underfitting.
Perché non creare semplicemente un modello che spieghi ogni punto nel set di dati di addestramento alla perfezione? La creazione di un modello che ha appreso i modelli del set di dati di addestramento troppo bene è ciò che causa l’overfitting. Il set di dati di addestramento e altri set di dati che si eseguono nel modello in futuro non saranno esattamente gli stessi. Saranno probabilmente molto simili in molti aspetti, ma si differenzieranno anche in modi chiave. Pertanto, progettare un modello che spieghi il set di dati di addestramento alla perfezione significa finire con una teoria sulla relazione tra le caratteristiche che non si generalizza bene ad altri set di dati.
Comprendere l’Overfitting
L’overfitting si verifica quando un modello apprende i dettagli all’interno del set di dati di addestramento troppo bene, causando al modello di soffrire quando si effettuano previsioni su dati esterni. Ciò può verificarsi quando il modello non solo apprende le caratteristiche del set di dati, ma apprende anche fluttuazioni casuali o rumore all’interno del set di dati, assegnando importanza a queste occorrenze casuali o non importanti.
L’overfitting è più probabile che si verifichi quando si utilizzano modelli non lineari, poiché sono più flessibili nell’apprendimento delle caratteristiche dei dati. Gli algoritmi di apprendimento automatico non parametrici spesso hanno vari parametri e tecniche che possono essere applicati per limitare la sensibilità del modello ai dati e ridurre così l’overfitting. Ad esempio, i modelli di albero decisionale sono altamente sensibili all’overfitting, ma una tecnica chiamata potatura può essere utilizzata per rimuovere casualmente alcuni dei dettagli che il modello ha appreso.
Se si graficasse la previsione del modello su assi X e Y, si avrebbe una linea di previsione che zigzaga avanti e indietro, il che riflette il fatto che il modello ha cercato troppo di adattarsi a tutti i punti nel set di dati alla sua spiegazione.
Controllare l’Overfitting
Quando addestriamo un modello, idealmente vogliamo che il modello non commetta errori. Quando le prestazioni del modello convergono verso la previsione corretta di tutti i punti di dati nel set di addestramento, l’adattamento diventa migliore. Un modello con un buon adattamento è in grado di spiegare quasi tutto il set di dati di addestramento senza overfitting.
Man mano che il modello si addestra, le sue prestazioni migliorano nel tempo. Il tasso di errore del modello diminuisce man mano che passa il tempo di addestramento, ma diminuisce solo fino a un certo punto. Il punto in cui le prestazioni del modello sul set di test iniziano a salire di nuovo è generalmente il punto in cui si verifica l’overfitting. Per ottenere il miglior adattamento per un modello, vogliamo interrompere l’addestramento del modello nel punto di perdita più bassa sul set di addestramento, prima che l’errore inizi a aumentare di nuovo. Il punto di arresto ottimale può essere determinato graficando le prestazioni del modello durante il tempo di addestramento e interrompendo l’addestramento quando la perdita è più bassa. Tuttavia, un rischio con questo metodo di controllo dell’overfitting è che specificare il punto di fine dell’addestramento in base alle prestazioni del test significa che i dati di test diventano in qualche modo inclusi nella procedura di addestramento e perdono il loro status di “dati intatti”.
Esistono diversi modi per combattere l’overfitting. Un metodo per ridurre l’overfitting è utilizzare una tattica di campionamento, che funziona stimando l’accuratezza del modello. È anche possibile utilizzare un set di convalida in aggiunta al set di test e tracciare l’accuratezza di addestramento contro il set di convalida invece del set di test. Ciò mantiene il set di test non visto. Un metodo di campionamento popolare è la cross-validazione K-folds. Questa tecnica consente di dividere i dati in sottinsiemi sui quali il modello viene addestrato e quindi le prestazioni del modello sui sottinsiemi vengono analizzate per stimare come il modello si comporterà sui dati esterni.
Utilizzare la cross-validazione è uno dei migliori modi per stimare l’accuratezza di un modello sui dati non visti e, combinata con un set di convalida, l’overfitting può essere spesso mantenuto al minimo.








