IA 101
Cosa sono RNN e LSTM nel Deep Learning?
Molte delle più impressionanti innovazioni nel campo dell’elaborazione del linguaggio naturale e dei chatbot dell’AI sono guidate da Reti Neurali Ricorrenti (RNN) e reti Long Short-Term Memory (LSTM). RNN e LSTM sono architetture di reti neurali speciali in grado di elaborare dati sequenziali, dove l’ordine cronologico è importante. Gli LSTM sono essenzialmente versioni migliorate delle RNN, in grado di interpretare sequenze di dati più lunghe. Vediamo come sono strutturate le RNN e le LSTM e come consentono la creazione di sistemi di elaborazione del linguaggio naturale sofisticati.
Cosa sono le Reti Neurali Feed-Forward?
Prima di parlare di come funzionano le reti Long Short-Term Memory (LSTM) e le reti neurali convoluzionali (CNN), dovremmo discutere il formato di una rete neurale in generale.
Una rete neurale è progettata per esaminare i dati e apprendere modelli rilevanti, in modo che questi modelli possano essere applicati ad altri dati e nuovi dati possano essere classificati. Le reti neurali sono divise in tre sezioni: un livello di input, un livello nascosto (o più livelli nascosti) e un livello di output.
Il livello di input è ciò che inserisce i dati nella rete neurale, mentre i livelli nascosti sono ciò che apprendono i modelli nei dati. I livelli nascosti nel set di dati sono collegati ai livelli di input e output da “pesi” e “bias”, che sono solo ipotesi su come i punti di dati sono collegati tra loro. Questi pesi vengono regolati durante l’addestramento. Mentre la rete si addestra, le stime del modello sui dati di addestramento (i valori di output) vengono confrontate con le etichette di addestramento effettive. Durante l’addestramento, la rete dovrebbe (sperabilmente) diventare più precisa nel prevedere le relazioni tra i punti di dati, in modo che possa classificare correttamente nuovi punti di dati. Le reti neurali profonde sono reti che hanno più livelli nel mezzo/più livelli nascosti. Più livelli nascosti e più neuroni/nodi ha il modello, migliori sono i modelli nel riconoscere modelli nei dati.
Le reti neurali feed-forward regolari, come quelle che ho descritto sopra, sono spesso chiamate “reti neurali dense”. Queste reti neurali dense vengono combinate con diverse architetture di rete che si specializzano nell’interpretazione di diversi tipi di dati.
Cosa sono le RNN (Reti Neurali Ricorrenti)?

Le Reti Neurali Ricorrenti (RNN) prendono il principio generale delle reti neurali feed-forward e le abilitano a gestire dati sequenziali dando al modello una memoria interna. La parte “Ricorrente” del nome RNN deriva dal fatto che l’input e l’output si ripetono. Una volta che l’output della rete viene prodotto, l’output viene copiato e restituito alla rete come input. Quando si prende una decisione, non solo l’input e l’output attuali vengono analizzati, ma anche l’input precedente viene considerato. In altre parole, se l’input iniziale per la rete è X e l’output è H, sia H che X1 (il prossimo input nella sequenza di dati) vengono inseriti nella rete per il prossimo round di apprendimento. In questo modo, il contesto dei dati (gli input precedenti) viene preservato mentre la rete si addestra.
Il risultato di questa architettura è che le RNN sono in grado di gestire dati sequenziali. Tuttavia, le RNN soffrono di alcuni problemi. Le RNN soffrono dei problemi di gradiente scomparso e gradiente esplosivo.
La lunghezza delle sequenze che una RNN può interpretare è piuttosto limitata, specialmente in confronto agli LSTM.
Cosa sono le LSTM (Long Short-Term Memory Networks)?
Le reti Long Short-Term Memory possono essere considerate estensioni delle RNN, applicando nuovamente il concetto di preservazione del contesto degli input. Tuttavia, le LSTM sono state modificate in diversi modi importanti che consentono loro di interpretare i dati passati con metodi superiori. Le modifiche apportate alle LSTM riguardano il problema del gradiente scomparso e consentono alle LSTM di considerare sequenze di input molto più lunghe.

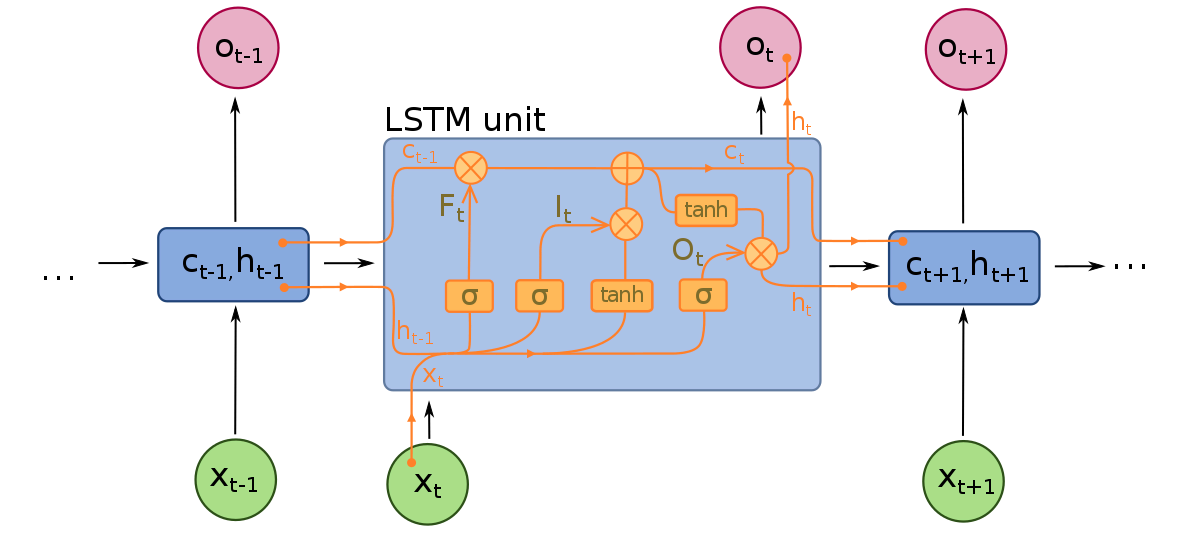
I modelli LSTM sono composti da tre componenti diversi, o porte. Ci sono una porta di input, una porta di output e una porta di dimenticanza. Allo stesso modo delle RNN, le LSTM prendono in considerazione gli input del timestep precedente quando modificano la memoria del modello e i pesi di input. La porta di input prende decisioni su quali valori sono importanti e dovrebbero essere lasciati passare nel modello. Una funzione sigmoidale viene utilizzata nella porta di input, che prende decisioni su quali valori passare attraverso la rete ricorrente. Zero fa cadere il valore, mentre 1 lo conserva. Una funzione TanH viene utilizzata qui, che decide quanto importante per il modello sono i valori di input, che vanno da -1 a 1.
Dopo che gli input attuali e lo stato di memoria sono stati presi in considerazione, la porta di output decide quali valori spingere nel prossimo timestep. Nella porta di output, i valori vengono analizzati e assegnati un’importanza che va da -1 a 1. Ciò regola i dati prima che vengano portati al prossimo calcolo del timestep. Infine, il compito della porta di dimenticanza è quello di eliminare le informazioni che il modello ritiene non necessarie per prendere una decisione sulla natura dei valori di input. La porta di dimenticanza utilizza una funzione sigmoidale sui valori, producendo numeri tra 0 (dimentica) e 1 (conserva).
Una rete neurale LSTM è composta da livelli LSTM speciali che possono interpretare dati sequenziali di parole e da livelli densamente connessi come quelli descritti sopra. Una volta che i dati passano attraverso i livelli LSTM, procedono nei livelli densamente connessi.








