IA 101
Cosa sono le CNN (Convolutional Neural Network)?
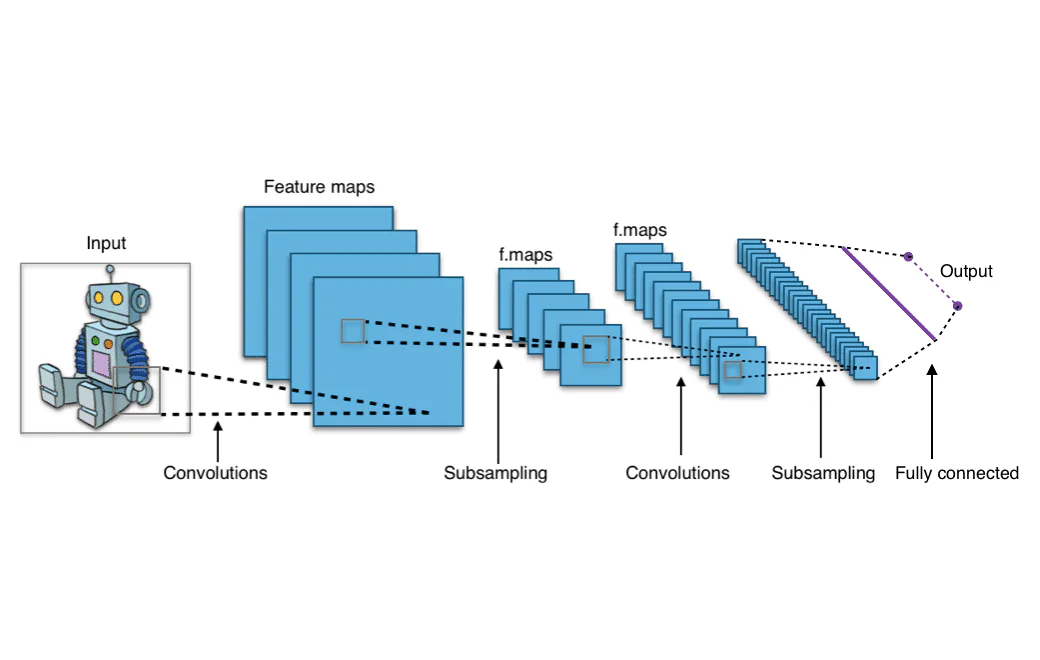
Forse ti sei chiesto come Facebook o Instagram sia in grado di riconoscere automaticamente i volti in un’immagine, o come Google ti permetta di cercare foto simili sul web semplicemente caricando una foto tua. Queste funzionalità sono esempi di visione artificiale, e sono alimentate da convolutional neural network (CNN). Eppure, cosa sono esattamente le convolutional neural network? Facciamo un’analisi approfondita dell’architettura di una CNN e capiamo come funzionano.
Cosa sono le reti neurali?
Prima di iniziare a parlare di convolutional neural network, prendiamo un momento per definire le reti neurali regolari. C’è un altro articolo sul tema delle reti neurali disponibile, quindi non ci addentreremo troppo nel dettaglio qui. Tuttavia, per definirle brevemente, sono modelli computazionali ispirati al cervello umano. Una rete neurale funziona prendendo in input i dati e manipolandoli regolando i “pesi”, che sono ipotesi su come le caratteristiche di input sono correlate tra loro e alla classe dell’oggetto. Mentre la rete è addestrata, i valori dei pesi vengono regolati e speriamo che convergano su pesi che catturano accuratamente le relazioni tra le caratteristiche.
Questo è il modo in cui funziona una rete neurale feed-forward, e le CNN sono composte da due metà: una rete neurale feed-forward e un gruppo di layer convoluzionali.
Cosa sono le Convolution Neural Network (CNN)?
Cosa sono le “convoluzioni” che avvengono in una convolutional neural network? Una convoluzione è un’operazione matematica che crea un insieme di pesi, creando essenzialmente una rappresentazione di parti dell’immagine. Questo insieme di pesi è denominato kernel o filtro. Il filtro creato è più piccolo dell’intera immagine di input, coprendo solo una sezione dell’immagine. I valori nel filtro vengono moltiplicati con i valori nell’immagine. Il filtro viene quindi spostato per formare una rappresentazione di una nuova parte dell’immagine, e il processo viene ripetuto fino a quando l’intera immagine non è stata coperta.
Un altro modo per pensare a questo è immaginare un muro di mattoni, con i mattoni che rappresentano i pixel dell’immagine di input. Una “finestra” viene fatta scorrere avanti e indietro lungo il muro, che è il filtro. I mattoni visibili attraverso la finestra sono i pixel che stanno avendo il loro valore moltiplicato per i valori all’interno del filtro. Per questo motivo, questo metodo di creazione di pesi con un filtro è spesso denominato tecnica “finestre scorrevoli”.
L’output dei filtri che vengono mossi intorno all’intera immagine di input è una matrice bidimensionale che rappresenta l’intera immagine. Questa matrice è chiamata “mappa di caratteristiche”.
Perché le convoluzioni sono essenziali
Qual è lo scopo della creazione di convoluzioni? Le convoluzioni sono necessarie perché una rete neurale deve essere in grado di interpretare i pixel in un’immagine come valori numerici. La funzione dei layer convoluzionali è quella di convertire l’immagine in valori numerici che la rete neurale possa interpretare e quindi estrarre modelli rilevanti. Il lavoro dei filtri nella rete convoluzionale è quello di creare una matrice bidimensionale di valori che può essere passata ai layer successivi della rete neurale, quelli che impareranno i modelli nell’immagine.
Filtri e canali
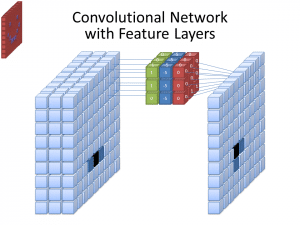
Photo: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
Le CNN non utilizzano un solo filtro per imparare modelli dall’immagine di input. Vengono utilizzati più filtri, poiché le diverse matrici create dai diversi filtri portano a una rappresentazione più complessa e ricca dell’immagine di input. I numeri comuni di filtri per le CNN sono 32, 64, 128 e 512. Più filtri ci sono, più opportunità ha la CNN di esaminare i dati di input e imparare da essi.
Una CNN analizza le differenze nei valori dei pixel per determinare i bordi degli oggetti. In un’immagine in scala di grigi, la CNN guarderebbe solo alle differenze tra nero e bianco, chiaro-scuro. Quando le immagini sono immagini a colori, non solo la CNN prende in considerazione il chiaro-scuro, ma deve anche prendere in considerazione i tre canali di colore diversi – rosso, verde e blu. In questo caso, i filtri possiedono 3 canali, proprio come l’immagine stessa. Il numero di canali che un filtro ha è denominato profondità, e il numero di canali nel filtro deve corrispondere al numero di canali nell’immagine.
Architettura della Convolutional Neural Network (CNN)
Facciamo un’analisi dell’architettura completa di una convolutional neural network. Un layer convoluzionale si trova all’inizio di ogni rete convoluzionale, poiché è necessario trasformare i dati dell’immagine in matrici numeriche. Tuttavia, i layer convoluzionali possono anche venire dopo altri layer convoluzionali, il che significa che questi layer possono essere impilati l’uno sull’altro. Avere più layer convoluzionali significa che gli output da un layer possono subire ulteriori convoluzioni e essere raggruppati in modelli rilevanti. In pratica, ciò significa che mentre i dati dell’immagine procedono attraverso i layer convoluzionali, la rete inizia a “riconoscere” caratteristiche più complesse dell’immagine.
I layer iniziali di una ConvNet sono responsabili dell’estrazione delle caratteristiche di basso livello, come i pixel che compongono linee semplici. I layer successivi della ConvNet uniranno queste linee in forme. Questo processo di passaggio dall’analisi di superficie all’analisi approfondita continua fino a quando la ConvNet non riconosce forme complesse come animali, volti umani e auto.
Dopo che i dati sono passati attraverso tutti i layer convoluzionali, procedono nella parte densamente connessa della CNN. I layer densamente connessi sono quelli che una rete neurale feed-forward tradizionale sembra, una serie di nodi disposti in layer che sono connessi l’uno all’altro. I dati procedono attraverso questi layer densamente connessi, che imparano i modelli estratti dai layer convoluzionali, e facendo ciò la rete diventa in grado di riconoscere oggetti.










