L'angolo di Anderson
HunyuanCustom lancia i deepfake video a immagine singola, con audio e sincronizzazione labiale
Questo articolo discute una nuova versione di un modello mondiale multimodale di Hunyuan Video chiamato "HunyuanCustom". L'ampiezza della copertura del nuovo documento, unita a diversi problemi in molti dei video di esempio forniti su pagina del progetto*, ci costringe a una copertura più generale del solito e a una riproduzione limitata dell'enorme quantità di materiale video che accompagna questo comunicato (poiché molti dei video richiedono un notevole lavoro di editing e di elaborazione per migliorare la leggibilità del layout).
Si prega di notare inoltre che nel documento il sistema generativo Kling basato su API viene chiamato "Keling". Per maggiore chiarezza, nel testo farò riferimento a "Kling".
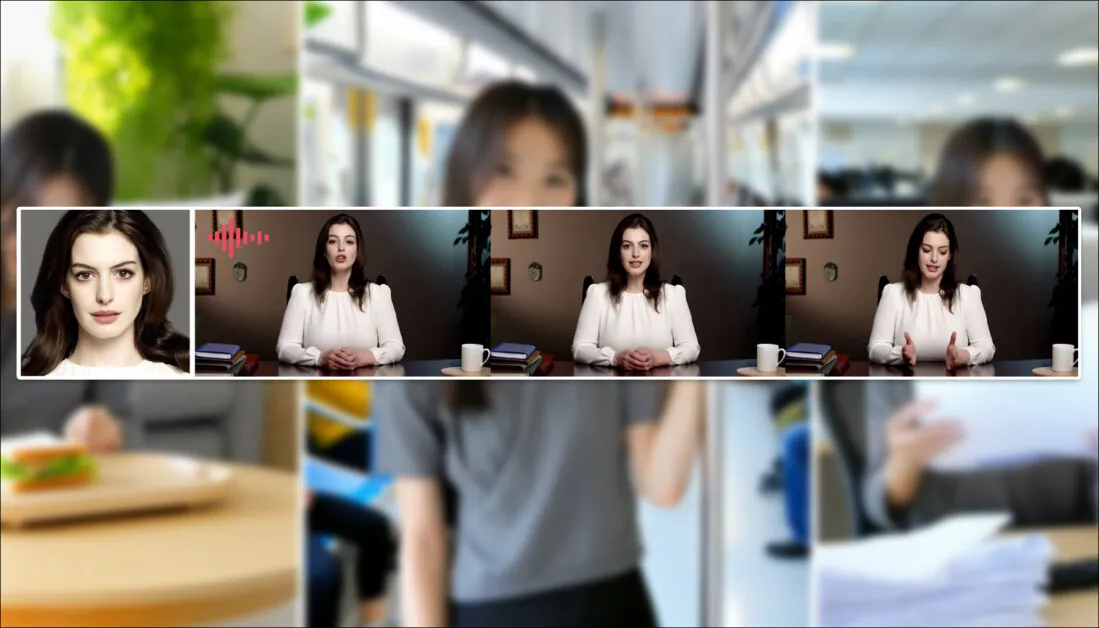
Tencent sta per rilasciare una nuova versione del suo Modello video Hunyuan, dal titolo HunyuanCustom. La nuova versione è apparentemente in grado di fare Modelli Hunyuan LoRA ridondante, consentendo all'utente di creare personalizzazioni video in stile "deepfake" tramite un singolo immagine:
Clicca per giocare. Prompt: "Un uomo ascolta musica e cucina spaghetti di lumache in cucina". Il nuovo metodo è paragonabile sia ai metodi close-source che a quelli open-source, incluso Kling, che è un importante concorrente in questo ambito. Fonte: https://hunyuancustom.github.io/ (attenzione: sito che richiede molta CPU/memoria!)
Nella colonna più a sinistra del video qui sopra, vediamo l'immagine sorgente singola fornita a HunyuanCustom, seguita dall'interpretazione del prompt da parte del nuovo sistema nella seconda colonna, accanto ad essa. Le colonne rimanenti mostrano i risultati di vari sistemi proprietari e FOSS: kling; Vedo; Pika; Hailuo; e il Esangue-based SkyReels-A2.
Nel video qui sotto, vediamo i rendering di tre scenari essenziali per questa versione: rispettivamente, persona + oggetto; emulazione di un singolo carattere, E prova virtuale (persona + vestiti):
Clicca per giocareTre esempi tratti dal materiale presente sul sito di supporto per Hunyuan Video.
Possiamo notare alcune cose da questi esempi, per lo più legate al sistema che si basa su un immagine sorgente singola, invece di più immagini dello stesso soggetto.
Nella prima clip, l'uomo è sostanzialmente ancora rivolto verso la telecamera. Abbassa la testa e la ruota lateralmente con un'angolazione non superiore a 20-25 gradi, ma con un'inclinazione superiore, il sistema dovrebbe iniziare a intuire come appare di profilo. È difficile, probabilmente impossibile, valutarlo con precisione partendo da una sola immagine frontale.
Nel secondo esempio, vediamo che la bambina è sorridente nel video renderizzato così come appare nell'unica immagine statica. Anche in questo caso, con quest'unica immagine come riferimento, l'HunyuanCustom avrebbe dovuto fare un'ipotesi relativamente poco informata su come apparisse il suo "volto a riposo". Inoltre, il suo volto non si discosta dalla posizione rivolta verso la telecamera più di quanto non accadesse nell'esempio precedente ("uomo che mangia patatine").
Nell'ultimo esempio, vediamo che poiché il materiale di origine (la donna e gli abiti che le viene chiesto di indossare) non sono immagini complete, il rendering ha ritagliato lo scenario per adattarlo, il che è in realtà una buona soluzione a un problema di dati!
Il punto è che sebbene il nuovo sistema possa gestire più immagini (come persona + patatine, o persona + vestiti), apparentemente non consente angolazioni multiple o viste alternative di un singolo personaggio, in modo da poter accogliere espressioni diverse o angolazioni insolite. In questa misura, il sistema potrebbe quindi avere difficoltà a sostituire il crescente ecosistema di modelli LoRA che hanno spuntato attorno a HunyuanVideo sin dalla sua uscita lo scorso dicembre, poiché possono aiutare HunyuanVideo a produrre personaggi coerenti da qualsiasi angolazione e con qualsiasi espressione facciale rappresentata nel set di dati di addestramento (in genere 20-60 immagini).
Cablato per il suono
Per l'audio, HunyuanCustom sfrutta il Sincronizzazione latente sistema (notoriamente difficile da configurare per gli hobbisti e da cui ottenere buoni risultati) per ottenere movimenti delle labbra che siano abbinati all'audio e al testo forniti dall'utente:
Con audio. Clicca per riprodurre. Vari esempi di sincronizzazione labiale tratti dal sito supplementare HunyuanCustom, modificati insieme.
Al momento in cui scrivo, non ci sono esempi in lingua inglese, ma sembrano piuttosto buoni, soprattutto se il metodo per crearli è facilmente installabile e accessibile.
Modifica di video esistenti
Il nuovo sistema offre risultati apparentemente impressionanti per l'editing video-video (V2V, o Vid2Vid), in cui un segmento di un video esistente (reale) viene mascherato e sostituito in modo intelligente con un soggetto fornito in un'unica immagine di riferimento. Di seguito un esempio tratto dal sito dei materiali supplementari:
Clicca per giocare. Viene preso di mira solo l'oggetto centrale, ma anche ciò che resta attorno ad esso viene modificato in un passaggio vid2vid di HunyuanCustom.
Come possiamo vedere, e come è standard in uno scenario vid2vid, il video intero viene in qualche misura alterato dal processo, sebbene la maggior parte delle alterazioni si verifichino nella regione interessata, ovvero il peluche. Presumibilmente potrebbero essere sviluppate delle condutture per creare tali trasformazioni sotto un spazzatura opaca Un approccio che lascia la maggior parte del contenuto video identico all'originale. Questo è ciò che Adobe Firefly fa in modo intelligente, e lo fa piuttosto bene, ma è un processo poco studiato nel panorama generativo FOSS.
Detto questo, la maggior parte degli esempi alternativi forniti svolgono un lavoro migliore nel mirare a queste integrazioni, come possiamo vedere nella compilazione assemblata di seguito:
Clicca per giocare. Diversi esempi di contenuti inseriti utilizzando vid2vid in HunyuanCustom, che dimostrano un notevole rispetto per il materiale non mirato.
Un nuovo inizio?
Questa iniziativa è uno sviluppo dell' Progetto video Hunyuan, non un netto allontanamento da quel flusso di sviluppo. I miglioramenti del progetto vengono introdotti come inserimenti architettonici discreti piuttosto che come radicali cambiamenti strutturali, con l'obiettivo di consentire al modello di mantenere la fedeltà dell'identità tra i frame senza fare affidamento su specifico per argomento ritocchi, come con gli approcci LoRA o di inversione testuale.
Per essere chiari, HunyuanCustom non è un progetto nato da zero, ma è piuttosto una messa a punto del modello di base di HunyuanVideo del dicembre 2024.
Coloro che hanno sviluppato LoRA di HunyuanVideo potrebbero chiedersi se funzioneranno ancora con questa nuova edizione o se dovranno reinventare la ruota LoRA ancora una volta se desiderano maggiori capacità di personalizzazione rispetto a quelle integrate in questa nuova versione.
In generale, un rilascio fortemente ottimizzato di un modello iperscalare altera il pesi del modello al punto che le LoRA realizzate per il modello precedente non funzioneranno correttamente, o non funzioneranno affatto, con il modello appena rifinito.
A volte, tuttavia, la popolarità di una messa a punto può sfidare le sue origini: un esempio di una messa a punto che diventa efficace forcella, con un ecosistema dedicato e follower propri, è il Diffusione dei pony messa a punto di Diffusione stabile XL (SDXL). Pony ha attualmente più di 592,000 download su in continua evoluzione Dominio CivitAI, con una vasta gamma di LoRA che hanno utilizzato Pony (e non SDXL) come modello di base e che richiedono Pony al momento dell'inferenza.
Rilasciando
La frequenza delle onde ultrasoniche è misurata in kilohertz (kHz). Diverse frequenze puntano la grassa in modi leggermente diversi. Le frequenze più basse raggiungono la grassa più profonda, mentre le frequenze più alte lavorano più vicino alla superficie. pagina del progetto per l' nuovo documento (che si intitola HunyuanCustom: un'architettura multimodale per la generazione di video personalizzati) contiene collegamenti a un Sito GitHub che, mentre scrivo, è appena diventato operativo e sembra contenere tutto il codice e i pesi necessari per l'implementazione locale, insieme a una timeline proposta (dove l'unica cosa importante che deve ancora arrivare è l'integrazione con ComfyUI).
Al momento della stesura del presente documento, il progetto Presenza del viso abbracciante è ancora un 404. C'è, tuttavia, un Versione basata su API dove apparentemente è possibile provare il sistema, a patto di fornire un codice di scansione WeChat.
Raramente ho visto un utilizzo così elaborato ed esteso di una così ampia varietà di progetti in un unico assembly, come è evidente in HunyuanCustom – e presumibilmente alcune delle licenze imporrebbero in ogni caso una versione completa.
Sulla pagina GitHub sono stati annunciati due modelli: una versione da 720px1280px che richiede 8 GB di memoria GPU Peak e una versione da 512px896px che richiede 60 GB di memoria GPU Peak.
Gli stati del repository 'La memoria GPU minima richiesta è di 24 GB per 720px1280px129f, ma è molto lenta... Consigliamo di utilizzare una GPU con 80 GB di memoria per una migliore qualità di generazione' – e ribadisce che finora il sistema è stato testato solo su Linux.
Il precedente modello Hunyuan Video è stato, sin dal rilascio ufficiale, quantizzato fino a dimensioni che ne consentono l'esecuzione con meno di 24 GB di VRAM, e sembra ragionevole supporre che il nuovo modello verrà adattato in forme più adatte ai consumatori dalla comunità, e che verrà rapidamente adattato anche per l'uso sui sistemi Windows.
A causa dei limiti di tempo e dell'enorme quantità di informazioni che accompagnano questa pubblicazione, possiamo solo dare un'occhiata più ampia, piuttosto che approfondita. Ciononostante, diamo un'occhiata più da vicino a HunyuanCustom.
Uno sguardo al giornale
La pipeline di dati per HunyuanCustom, apparentemente conforme a GDPR framework, incorpora sia set di dati video sintetizzati che open source, inclusi OpenHumanVid, con otto categorie principali rappresentate: gli esseri umani, animali, piante, paesaggi, veicoli, oggetti, architetturae anime.

Dal documento di rilascio, una panoramica dei diversi pacchetti che contribuiscono alla pipeline di costruzione dei dati HunyuanCustom. Fonte: https://arxiv.org/pdf/2505.04512
Il filtraggio iniziale inizia con PySceneDetect, che suddivide i video in clip singole. TestoBPN-Plus-Plus viene poi utilizzato per rimuovere i video che contengono testo eccessivo sullo schermo, sottotitoli, filigrane o loghi.
Per risolvere le incongruenze di risoluzione e durata, le clip sono standardizzate a cinque secondi di lunghezza e ridimensionate a 512 o 720 pixel sul lato corto. Il filtro estetico viene gestito tramite Koala-36M, con una soglia personalizzata di 0.06 applicata al set di dati personalizzato curato dai ricercatori del nuovo articolo.
Il processo di estrazione del soggetto combina il Qwen7B Modello linguistico di grandi dimensioni (LLM), il YOLO11X framework di riconoscimento degli oggetti e il popolare InsightFace architettura, per identificare e convalidare le identità umane.
Per i soggetti non umani, QwenVL SAM 2 a terra vengono utilizzati per estrarre i riquadri di delimitazione pertinenti, che vengono scartati se troppo piccoli.

Esempi di segmentazione semantica con Grounded SAM 2, utilizzati nel progetto Hunyuan Control. Fonte: https://github.com/IDEA-Research/Grounded-SAM-2
L'estrazione multi-soggetto utilizza Firenze2 per l'annotazione del riquadro di delimitazione e Grounded SAM 2 per la segmentazione, seguita dal clustering e dalla segmentazione temporale dei frame di addestramento.
Le clip elaborate vengono ulteriormente migliorate tramite annotazioni, utilizzando un sistema proprietario di etichettatura strutturata sviluppato dal team Hunyuan e che fornisce metadati stratificati, come descrizioni e segnali di movimento della telecamera.
Aumento della maschera strategie, inclusa la conversione in bounding box, sono state applicate durante l'addestramento per ridurre overfitting e garantire che il modello si adatti a diverse forme di oggetti.
I dati audio venivano sincronizzati utilizzando il suddetto LatentSync e le clip venivano scartate se i punteggi di sincronizzazione scendevano al di sotto di una soglia minima.
Il quadro di valutazione della qualità delle immagini in cieco IperIQA è stato utilizzato per escludere i video con punteggio inferiore a 40 (sulla scala personalizzata di HyperIQA). Le tracce audio valide sono state quindi elaborate con Sussurro per estrarre funzionalità per attività successive.
Gli autori incorporano il LLaVA modello di assistente linguistico durante la fase di annotazione, sottolineando la posizione centrale di questo framework in HunyuanCustom. LLaVA viene utilizzato per generare didascalie per le immagini e facilitare l'allineamento dei contenuti visivi con i prompt di testo, supportando la costruzione di un segnale di addestramento coerente tra le diverse modalità:

Il framework HunyuanCustom supporta la generazione di video coerenti con l'identità, basati su input di testo, immagine, audio e video.
Sfruttando le capacità di allineamento tra linguaggio e visione di LLaVA, la pipeline ottiene un ulteriore livello di coerenza semantica tra gli elementi visivi e le relative descrizioni testuali, particolarmente utile in scenari con più soggetti o scene complesse.
Video personalizzato
Per consentire la generazione di video basata su un'immagine di riferimento e un prompt, sono stati creati due moduli incentrati su LLaVA, adattando prima la struttura di input di HunyuanVideo in modo che potesse accettare un'immagine insieme al testo.
Ciò ha comportato la formattazione del prompt in modo da incorporare direttamente l'immagine o da taggarla con una breve descrizione dell'identità. È stato utilizzato un token separatore per evitare che l'incorporamento dell'immagine sovrastasse il contenuto del prompt.
Poiché il codificatore visivo di LLaVA tende a comprimere o scartare dettagli spaziali a grana fine durante l'allineamento delle caratteristiche dell'immagine e del testo (in particolare quando si traduce una singola immagine di riferimento in un incorporamento semantico generale), un modulo di miglioramento dell'identità è stato incorporato. Poiché quasi tutti i modelli di diffusione latente video hanno qualche difficoltà a mantenere un'identità senza un LoRA, anche in una clip di cinque secondi, le prestazioni di questo modulo nei test della comunità potrebbero rivelarsi significative.
In ogni caso, l'immagine di riferimento viene quindi ridimensionata e codificata utilizzando il 3D-VAE causale dal modello HunyuanVideo originale e il suo latente inserito nel video latente lungo l'asse temporale, con un offset spaziale applicato per evitare che l'immagine venga riprodotta direttamente nell'output, pur continuando a guidare la generazione.
Il modello è stato addestrato utilizzando Corrispondenza del flusso, con campioni di rumore estratti da un logit-normal distribuzione – e la rete è stata addestrata a recuperare il video corretto da queste latenze rumorose. LLaVA e il generatore video sono stati entrambi ottimizzati insieme in modo che l'immagine e il prompt potessero guidare l'output in modo più fluido e mantenere coerente l'identità del soggetto.
Per i prompt multi-soggetto, ogni coppia immagine-testo è stata incorporata separatamente e assegnata una posizione temporale distinta, consentendo di distinguere le identità e supportando la generazione di scene che coinvolgono multiplo soggetti interagenti.
Suono e visione
HunyuanCustom condiziona la generazione di audio/voce utilizzando sia l'audio immesso dall'utente sia un prompt di testo, consentendo ai personaggi di parlare all'interno di scene che riflettono l'ambientazione descritta.
A supporto di ciò, un modulo AudioNet Identity-disentangled introduce funzionalità audio senza interrompere i segnali di identità incorporati nell'immagine di riferimento e nel prompt. Queste funzionalità vengono allineate alla timeline del video compresso, suddivise in segmenti a livello di fotogramma e iniettate utilizzando un'interfaccia spaziale. attenzione incrociata meccanismo che mantiene isolato ogni fotogramma, preservando la coerenza del soggetto ed evitando interferenze temporali.
Un secondo modulo di iniezione temporale fornisce un controllo più preciso su tempi e movimenti, lavorando in tandem con AudioNet, mappando le caratteristiche audio su regioni specifiche della sequenza latente e utilizzando un Perceptron multistrato (MLP) per convertirli in token-saggio offset di movimento. Ciò consente ai gesti e ai movimenti facciali di seguire il ritmo e l'enfasi dell'input vocale con maggiore precisione.
HunyuanCustom consente di modificare direttamente i soggetti presenti nei video esistenti, sostituendo o inserendo persone o oggetti in una scena senza dover ricostruire l'intera clip da zero. Questo lo rende utile per attività che richiedono la modifica mirata dell'aspetto o del movimento.
Clicca per giocare. Un ulteriore esempio dal sito supplementare.
Per facilitare la sostituzione efficiente dei soggetti nei video esistenti, il nuovo sistema evita l'approccio ad alta intensità di risorse dei metodi recenti come quello attualmente popolare VACE, o quelli che uniscono intere sequenze video, privilegiando invece la compressione di un video di riferimento utilizzando il 3D-VAE causale pre-addestrato, allineandolo alle latenti video interne della pipeline di generazione e quindi sommando i due. Questo mantiene il processo relativamente leggero, pur consentendo al contenuto video esterno di guidare l'output.
Una piccola rete neurale gestisce l'allineamento tra il video di input pulito e le latenti rumorose utilizzate nella generazione. Il sistema testa due metodi per iniettare queste informazioni: unire i due set di feature prima di comprimerli nuovamente; e aggiungere le feature fotogramma per fotogramma. Gli autori hanno scoperto che il secondo metodo funziona meglio ed evita la perdita di qualità mantenendo invariato il carico computazionale.
Dati e test
Nei test, le metriche utilizzate sono state: il modulo di coerenza dell'identità in ArcoFaccia, che estrae gli embedding facciali sia dall'immagine di riferimento che da ciascun fotogramma del video generato, e quindi calcola la similarità media del coseno tra di essi; somiglianza di soggetto, tramite l'invio di segmenti YOLO11x a dinosauro 2 per confronto; CLIP-Ballineamento testo-video, che misura la somiglianza tra il prompt e il video generato; CLIP-B ancora, per calcolare la somiglianza tra ciascun fotogramma e i fotogrammi adiacenti e il primo fotogramma, nonché la coerenza temporale; e grado dinamico, come definito da VBench.
Come indicato in precedenza, i concorrenti closed source di riferimento erano Hailuo, Vidu 2.0, Kling (1.6) e Pika. I framework FOSS concorrenti erano VACE e SkyReels-A2.

Valutazione delle prestazioni del modello che confronta HunyuanCustom con i principali metodi di personalizzazione video in termini di coerenza dell'ID (Face-Sim), similarità del soggetto (DINO-Sim), allineamento testo-video (CLIP-BT), coerenza temporale (Temp-Consis) e intensità del movimento (DD). I risultati ottimali e sub-ottimali sono mostrati rispettivamente in grassetto e sottolineato.
Di questi risultati, gli autori affermano:
"Il nostro [HunyuanCustom] raggiunge la migliore coerenza di ID e di soggetto. Ottiene anche risultati comparabili in termini di prompt following e coerenza temporale. [Hailuo] ha il miglior punteggio di clip perché riesce a seguire bene le istruzioni testuali con la sola coerenza di ID, sacrificando la coerenza dei soggetti non umani (il peggiore DINO-Sim). In termini di livello dinamico, [Vidu] e [VACE] hanno prestazioni scadenti, il che potrebbe essere dovuto alle dimensioni ridotte del modello."
Sebbene il sito del progetto sia saturo di video comparativi (il cui layout sembra essere stato progettato per l'estetica del sito web piuttosto che per facilitare il confronto), al momento non presenta un equivalente video dei risultati statici raggruppati nel PDF, per quanto riguarda i test qualitativi iniziali. Pur includendolo qui, incoraggio il lettore a esaminare attentamente i video sul sito del progetto, poiché offrono una migliore impressione dei risultati:

Dall'articolo, un confronto sulla personalizzazione video incentrata sugli oggetti. Sebbene l'utente debba (come sempre) fare riferimento al PDF originale per una migliore risoluzione, i video sul sito del progetto potrebbero essere una risorsa più illuminante in questo caso.
Gli autori commentano qui:
'Si può osservare che [Vidu], [Skyreels A2] e il nostro metodo raggiungono risultati relativamente buoni nell'allineamento rapido e nella coerenza del soggetto, ma la nostra qualità video è migliore di Vidu e Skyreels, grazie alle buone prestazioni di generazione video del nostro modello base, ovvero [Hunyuanvideo-13B].
"Tra i prodotti commerciali, sebbene [Kling] abbia una buona qualità video, il primo fotogramma del video presenta un problema di copia-incolla e talvolta il soggetto si muove troppo velocemente e [sfoca], il che rende l'esperienza visiva scadente."
Gli autori commentano inoltre che Pika ha prestazioni scadenti in termini di coerenza temporale, introducendo artefatti nei sottotitoli (effetti di una scarsa cura dei dati, in cui è stato consentito agli elementi di testo nelle clip video di contaminare i concetti principali).
Hailuo mantiene l'identità facciale, affermano, ma non riesce a preservare la coerenza dell'intero corpo. Tra i metodi open source, VACE, sostengono i ricercatori, non è in grado di mantenere la coerenza dell'identità, mentre HunyuanCustom produce video con una solida conservazione dell'identità, mantenendo al contempo qualità e diversità.
Successivamente sono stati condotti test per personalizzazione video multisoggetto, contro gli stessi concorrenti. Come nell'esempio precedente, i risultati PDF appiattiti non sono equivalenti stampati dei video disponibili sul sito del progetto, ma sono unici tra i risultati presentati:

Confronti con personalizzazioni video multi-soggetto. Consultare il PDF per maggiori dettagli e risoluzione.
Il documento afferma:
"[Pika] può generare i soggetti specificati, ma mostra instabilità nei fotogrammi video, con casi in cui un uomo scompare in uno scenario e una donna non riesce ad aprire una porta come richiesto. [Vidu] e [VACE] catturano parzialmente l'identità umana, ma perdono dettagli significativi degli oggetti non umani, il che indica una limitazione nella rappresentazione di soggetti non umani.
'[SkyReels A2] presenta una grave instabilità del frame, con evidenti cambiamenti nei chip e numerosi artefatti nello scenario giusto.
'Al contrario, il nostro HunyuanCustom cattura efficacemente sia l'identità dei soggetti umani che quella dei soggetti non umani, genera video che aderiscono alle richieste fornite e mantiene un'elevata qualità visiva e stabilità.'
Un ulteriore esperimento è stato quello della "pubblicità umana virtuale", in cui ai framework è stato chiesto di integrare un prodotto con una persona:

Dal round di test qualitativi, ecco alcuni esempi di "product placement" neurale. Per maggiori dettagli e risoluzione, consultare il PDF.
Per questo round, gli autori affermano:
"I [risultati] dimostrano che HunyuanCustom mantiene efficacemente l'identità dell'essere umano, preservando al contempo i dettagli del prodotto di destinazione, incluso il testo su di esso.
'Inoltre, l'interazione tra l'uomo e il prodotto appare naturale e il video aderisce fedelmente allo spunto fornito, evidenziando il notevole potenziale di HunyuanCustom nella generazione di video pubblicitari.'
Un ambito in cui i risultati video sarebbero stati molto utili è stato il round qualitativo per la personalizzazione del soggetto basata sull'audio, in cui il personaggio pronuncia l'audio corrispondente da una scena e da una postura descritte nel testo.

Risultati parziali forniti per la sessione audio, sebbene in questo caso i risultati video sarebbero stati preferibili. Qui viene riprodotta solo la metà superiore della figura in PDF, poiché è di grandi dimensioni e difficile da inserire in questo articolo. Si prega di fare riferimento al PDF originale per maggiori dettagli e risoluzione.
Gli autori affermano:
I precedenti metodi di animazione umana basati sull'audio immettevano un'immagine umana e un audio, in cui la postura, l'abbigliamento e l'ambiente umano rimanevano coerenti con l'immagine fornita e non potevano generare video con altri gesti e ambienti, il che potrebbe [limitarne] l'applicazione.
'…[Il nostro] HunyuanCustom consente la personalizzazione umana basata sull'audio, in cui il personaggio pronuncia l'audio corrispondente in una scena e in una postura descritte tramite testo, consentendo un'animazione umana basata sull'audio più flessibile e controllabile.'
Ulteriori test (per tutti i dettagli vedere il PDF) hanno incluso un round che ha messo a confronto il nuovo sistema con VACE e Kling 1.6 per la sostituzione dei soggetti video:

Sostituzione del soggetto in modalità video-video. Per maggiori dettagli e risoluzione, fare riferimento al PDF originale.
Tra questi, gli ultimi test presentati nel nuovo articolo, i ricercatori affermano:
"VACE soffre di artefatti di contorno dovuti alla rigorosa aderenza alle maschere di input, che si traducono in forme innaturali dei soggetti e interruzioni della continuità del movimento. [Kling], al contrario, presenta un effetto copia-incolla, in cui i soggetti vengono sovrapposti direttamente al video, con conseguente scarsa integrazione con lo sfondo.
'Al contrario, HunyuanCustom evita efficacemente gli artefatti di confine, raggiunge un'integrazione perfetta con lo sfondo video e mantiene una forte conservazione dell'identità, dimostrando le sue prestazioni superiori nelle attività di editing video.'
Conclusione
Si tratta di una versione affascinante, non da ultimo perché affronta un problema di cui ultimamente si lamenta sempre più spesso la scontenta comunità degli hobbisti: la mancanza di sincronizzazione labiale, in modo che il maggiore realismo possibile in sistemi come Hunyuan Video e Wan 2.1 possa acquisire una nuova dimensione di autenticità.
Sebbene la disposizione di quasi tutti gli esempi video comparativi sul sito del progetto renda piuttosto difficile confrontare le capacità di HunyuanCustom con i concorrenti precedenti, è necessario notare che pochissimi progetti nel settore della sintesi video hanno il coraggio di misurarsi nei test con Kling, l'API commerciale di diffusione video che si posiziona sempre in cima o vicino alla vetta delle classifiche; Tencent sembra aver fatto progressi rispetto a questo colosso in modo piuttosto impressionante.
* Il problema è che alcuni video sono così ampi, corti e ad alta risoluzione che non vengono riprodotti nei lettori video standard come VLC o Windows Media Player, mostrando schermate nere.
Prima pubblicazione giovedì 8 maggio 2025












