
AI 101
Apa itu Overfitting?
Apa itu Overfitting?
Saat Anda melatih jaringan saraf, Anda harus menghindari overfitting. overfitting adalah masalah dalam pembelajaran mesin dan statistik ketika model mempelajari pola kumpulan data pelatihan dengan sangat baik, sehingga menjelaskan kumpulan data pelatihan dengan sempurna, namun gagal menggeneralisasi kekuatan prediktifnya ke kumpulan data lainnya.
Dengan kata lain, dalam kasus model overfitting sering menunjukkan akurasi yang sangat tinggi pada dataset pelatihan tetapi akurasi rendah pada data yang dikumpulkan dan dijalankan melalui model di masa depan. Itu definisi singkat tentang overfitting, tapi mari kita bahas konsep overfitting lebih detail. Mari kita lihat bagaimana overfitting terjadi dan bagaimana hal itu dapat dihindari.
Memahami “Fit” dan Underfitting
Akan sangat membantu jika kita melihat konsep underfitting dan “cocok” umumnya ketika membahas overfitting. Saat kami melatih model, kami mencoba mengembangkan kerangka kerja yang mampu memprediksi sifat, atau kelas, item dalam kumpulan data, berdasarkan fitur yang mendeskripsikan item tersebut. Sebuah model harus mampu menjelaskan suatu pola dalam kumpulan data dan memprediksi kelas titik data masa depan berdasarkan pola ini. Semakin baik model menjelaskan hubungan antara fitur-fitur set pelatihan, semakin “sesuai” model kita.
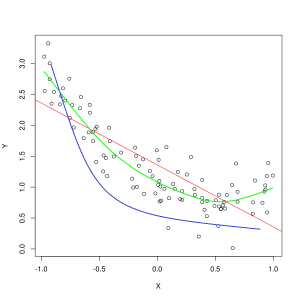
Garis biru merepresentasikan prediksi oleh model yang underfitting, sedangkan garis hijau merepresentasikan model yang lebih fit. Foto: Pep Roca melalui Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Model yang menjelaskan dengan buruk hubungan antara fitur data pelatihan dan dengan demikian gagal mengklasifikasikan contoh data masa depan secara akurat adalah kurang pas data pelatihan. Jika Anda membuat grafik hubungan yang diprediksi dari model underfitting dengan perpotongan sebenarnya dari fitur dan label, prediksi akan melenceng. Jika kita memiliki grafik dengan nilai sebenarnya dari rangkaian pelatihan yang diberi label, model yang sangat tidak sesuai akan kehilangan sebagian besar titik data secara drastis. Model dengan kecocokan yang lebih baik mungkin memotong jalur melalui pusat titik data, dengan titik data individual sedikit menyimpang dari nilai yang diprediksi.
Underfitting sering terjadi ketika data tidak mencukupi untuk membuat model yang akurat, atau ketika mencoba merancang model linier dengan data non-linier. Lebih banyak data pelatihan atau lebih banyak fitur sering membantu mengurangi underfitting.
Jadi mengapa kita tidak membuat model yang menjelaskan setiap poin dalam data pelatihan dengan sempurna? Tentunya akurasi yang sempurna diinginkan? Membuat model yang telah mempelajari pola data pelatihan dengan sangat baik adalah penyebab overfitting. Kumpulan data pelatihan dan kumpulan data lain di masa mendatang yang Anda jalankan melalui model tidak akan persis sama. Mereka kemungkinan besar akan sangat mirip dalam banyak hal, tetapi mereka juga akan berbeda dalam hal-hal utama. Oleh karena itu, mendesain model yang menjelaskan dataset pelatihan dengan sempurna berarti Anda berakhir dengan teori tentang hubungan antara fitur yang tidak digeneralisasikan dengan baik ke dataset lain.
Memahami Overfitting
Overfitting terjadi ketika model mempelajari detail dalam kumpulan data pelatihan dengan terlalu baik, sehingga menyebabkan model mengalami kesulitan saat prediksi dibuat pada data luar. Hal ini mungkin terjadi ketika model tidak hanya mempelajari fitur kumpulan data, tetapi juga mempelajari fluktuasi acak atau kebisingan dalam kumpulan data, mengutamakan kejadian acak/tidak penting ini.
Overfitting lebih mungkin terjadi saat model nonlinier digunakan, karena lebih fleksibel saat mempelajari fitur data. Algoritme pembelajaran mesin nonparametrik seringkali memiliki berbagai parameter dan teknik yang dapat diterapkan untuk membatasi sensitivitas model terhadap data dan dengan demikian mengurangi overfitting. Sebagai contoh, model pohon keputusan sangat sensitif terhadap overfitting, tetapi teknik yang disebut pruning dapat digunakan untuk menghapus secara acak beberapa detail yang telah dipelajari model.
Jika Anda membuat grafik prediksi model pada sumbu X dan Y, Anda akan memiliki garis prediksi yang zig-zag bolak-balik, yang mencerminkan fakta bahwa model telah berusaha terlalu keras untuk memasukkan semua titik dalam kumpulan data ke dalam penjelasannya.
Mengontrol Overfitting
Saat kami melatih model, idealnya kami ingin model tersebut tidak membuat kesalahan. Ketika kinerja model menyatu untuk membuat prediksi yang benar pada semua titik data dalam dataset pelatihan, kecocokannya menjadi lebih baik. Model dengan kecocokan yang baik mampu menjelaskan hampir semua dataset pelatihan tanpa overfitting.
Sebagai model melatih kinerjanya meningkat dari waktu ke waktu. Tingkat kesalahan model akan berkurang seiring berjalannya waktu pelatihan, tetapi hanya berkurang sampai titik tertentu. Titik di mana performa model pada set pengujian mulai meningkat lagi biasanya adalah titik di mana overfitting terjadi. Untuk mendapatkan model yang paling cocok, kami ingin menghentikan pelatihan model pada titik kerugian terendah pada set pelatihan, sebelum kesalahan mulai meningkat lagi. Titik henti optimal dapat dipastikan dengan membuat grafik kinerja model sepanjang waktu pelatihan dan menghentikan pelatihan saat kerugian paling rendah. Namun, satu risiko dengan metode pengendalian overfitting ini adalah bahwa menentukan titik akhir untuk pelatihan berdasarkan kinerja pengujian berarti bahwa data pengujian agak dimasukkan dalam prosedur pelatihan, dan kehilangan statusnya sebagai data murni "tak tersentuh".
Ada beberapa cara berbeda yang dapat dilakukan seseorang untuk melawan overfitting. Salah satu metode untuk mengurangi overfitting adalah dengan menggunakan taktik resampling, yang beroperasi dengan memperkirakan keakuratan model. Anda juga dapat menggunakan pengesahan dataset selain set pengujian dan plot akurasi pelatihan terhadap set validasi, bukan set data uji. Ini membuat kumpulan data pengujian Anda tidak terlihat. Metode resampling yang populer adalah validasi silang K-folds. Teknik ini memungkinkan Anda untuk membagi data menjadi subset tempat model dilatih, lalu performa model pada subset dianalisis untuk memperkirakan bagaimana performa model pada data luar.
Memanfaatkan validasi silang adalah salah satu cara terbaik untuk memperkirakan akurasi model pada data yang tidak terlihat, dan bila digabungkan dengan validasi dataset, overfitting seringkali dapat dijaga seminimal mungkin.










