AI 101
Apa itu Regresi Linier?
Apa itu Regresi Linier?
Regresi linier adalah algoritma yang digunakan untuk memprediksi, atau memvisualisasikan, sebuah hubungan antara dua fitur/variabel yang berbeda. Dalam tugas regresi linier, ada dua jenis variabel yang diperiksa: variabel dependen dan variabel independen. Variabel independen adalah variabel yang berdiri sendiri, tidak dipengaruhi oleh variabel lain. Ketika variabel independen disesuaikan, tingkat variabel dependen akan berfluktuasi. Variabel dependen adalah variabel yang sedang dipelajari, dan itulah yang model regresi selesaikan/coba prediksi. Dalam tugas regresi linier, setiap pengamatan/instance terdiri dari nilai variabel dependen dan nilai variabel independen.
Itu adalah penjelasan singkat tentang regresi linier, tetapi mari kita pastikan kita memahami regresi linier dengan lebih baik dengan melihat contoh dan memeriksa rumus yang digunakannya.
Memahami Regresi Linier
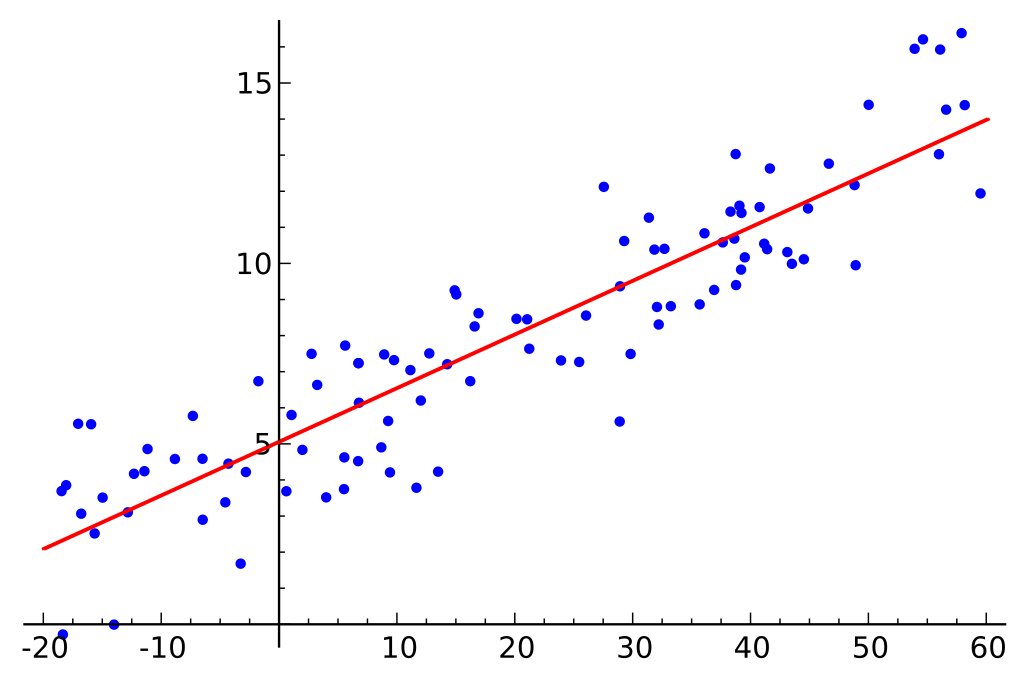
Anggaplah kita memiliki dataset yang mencakup ukuran hard drive dan biaya hard drive tersebut.
Mari kita asumsikan bahwa dataset yang kita miliki terdiri dari dua fitur yang berbeda: jumlah memori dan biaya. Semakin banyak memori yang kita beli untuk komputer, semakin tinggi biaya pembelian. Jika kita memplot titik data individu pada grafik scatter, kita mungkin mendapatkan grafik yang terlihat seperti ini:

Rasio memori-ke-biaya yang tepat mungkin bervariasi antara produsen dan model hard drive, tetapi secara umum, tren data adalah salah satu yang dimulai dari pojok kiri bawah (di mana hard drive lebih murah dan memiliki kapasitas yang lebih kecil) dan bergerak ke pojok kanan atas (di mana hard drive lebih mahal dan memiliki kapasitas yang lebih tinggi).
Jika kita memiliki jumlah memori pada sumbu X dan biaya pada sumbu Y, garis yang menangkap hubungan antara variabel X dan Y akan dimulai dari pojok kiri bawah dan berjalan ke pojok kanan atas.

Fungsi dari model regresi adalah untuk menentukan fungsi linier antara variabel X dan Y yang paling baik menjelaskan hubungan antara kedua variabel. Dalam regresi linier, diasumsikan bahwa Y dapat dihitung dari kombinasi variabel input. Hubungan antara variabel input (X) dan variabel target (Y) dapat digambarkan dengan menggambar garis melalui titik-titik pada grafik. Garis tersebut mewakili fungsi yang paling baik menjelaskan hubungan antara X dan Y (misalnya, setiap kali X meningkat 3, Y meningkat 2). Tujuannya adalah untuk menemukan “garis regresi” yang optimal, atau fungsi yang paling baik sesuai dengan data.
Garis biasanya direpresentasikan oleh persamaan: Y = m*X + b. X mengacu pada variabel dependen sedangkan Y adalah variabel independen. Sementara itu, m adalah kemiringan garis, yang didefinisikan oleh “kenaikan” atas “jalan”. Praktisi pembelajaran mesin merepresentasikan persamaan garis kemiringan yang terkenal sedikit berbeda, menggunakan persamaan ini:
y(x) = w0 + w1 * x
Dalam persamaan di atas, y adalah variabel target sedangkan “w” adalah parameter model dan input adalah “x”. Jadi persamaan tersebut dibaca sebagai: “Fungsi yang memberikan Y, tergantung pada X, sama dengan parameter model dikalikan dengan fitur”. Parameter model disesuaikan selama pelatihan untuk mendapatkan garis regresi yang paling baik.
Regresi Linier Berganda

Photo: Cbaf via Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Proses yang dijelaskan di atas berlaku untuk regresi linier sederhana, atau regresi pada dataset yang hanya memiliki satu fitur/variabel independen. Namun, regresi juga dapat dilakukan dengan beberapa fitur. Dalam kasus “regresi linier berganda“, persamaan diperluas oleh jumlah variabel yang ditemukan dalam dataset. Dengan kata lain, sementara persamaan untuk regresi linier biasa adalah y(x) = w0 + w1 * x, persamaan untuk regresi linier berganda akan menjadi y(x) = w0 + w1x1 plus bobot dan input untuk berbagai fitur. Jika kita merepresentasikan jumlah total bobot dan fitur sebagai w(n)x(n), maka kita dapat merepresentasikan rumus seperti ini:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Setelah menetapkan rumus untuk regresi linier, model pembelajaran mesin akan menggunakan nilai yang berbeda untuk bobot, menggambar garis yang berbeda. Ingat bahwa tujuannya adalah untuk menemukan garis yang paling baik sesuai dengan data untuk menentukan kombinasi bobot mana (dan oleh karena itu garis mana) yang paling baik sesuai dengan data dan menjelaskan hubungan antara variabel.
Fungsi biaya digunakan untuk mengukur seberapa dekat nilai Y yang diasumsikan dengan nilai Y yang sebenarnya ketika diberikan nilai bobot tertentu. Fungsi biaya untuk regresi linier adalah mean squared error, yang hanya mengambil rata-rata (kuadrat) kesalahan antara nilai prediksi dan nilai sebenarnya untuk semua titik data dalam dataset. Fungsi biaya digunakan untuk menghitung biaya, yang menangkap perbedaan antara nilai target prediksi dan nilai target sebenarnya. Jika garis sesuai jauh dari titik data, biaya akan lebih tinggi, sementara biaya akan menjadi lebih kecil ketika garis semakin sesuai dengan menangkap hubungan sebenarnya antara variabel. Bobot model kemudian disesuaikan sampai konfigurasi bobot yang menghasilkan kesalahan terkecil ditemukan.








