कृत्रिम बुद्धिमत्ता
Auto-GPT & GPT-Engineer: आज के अग्रणी AI एजेंटों के लिए एक विस्तृत गाइड

जब हम ChatGPT की तुलना Auto-GPT और GPT-Engineer जैसे स्वायत्त AI एजेंटों से करते हैं, तो निर्णय लेने की प्रक्रिया में एक महत्वपूर्ण अंतर सामने आता है। जबकि ChatGPT को बातचीत को चलाने के लिए मानव हस्तक्षेप की आवश्यकता होती है, उपयोगकर्ता प्रोम्प्ट के आधार पर मार्गदर्शन प्रदान करता है, योजना प्रक्रिया मुख्य रूप से मानव हस्तक्षेप पर निर्भर करती है।
जनरेटिव AI मॉडल जैसे ट्रांसफॉर्मर्स इन स्वायत्त AI एजेंटों के पीछे राज्य-ऑफ-द-आर्ट कोर तकनीक हैं। इन ट्रांसफॉर्मर्स को बड़े डेटासेट पर प्रशिक्षित किया जाता है, जिससे उन्हें जटिल तर्क और निर्णय लेने की क्षमता का अनुकरण करने की अनुमति मिलती है।
स्वायत्त एजेंटों की ओपन-सोर्स जड़ें: Auto-GPT और GPT-Engineer
इनमें से कई स्वायत्त AI एजेंट नवाचारी व्यक्तियों द्वारा नेतृत्व वाली ओपन-सोर्स पहलों से उत्पन्न होते हैं जो पारंपरिक कार्य प्रवाह को बदल रहे हैं। सुझाव देने के बजाय, Auto-GPT जैसे एजेंट स्वतंत्र रूप से कार्यों को संभाल सकते हैं, ऑनलाइन शॉपिंग से लेकर बुनियादी ऐप्स बनाने तक। OpenAI का कोड इंटरप्रेटर ChatGPT को विचारों का सुझाव देने से लेकर उन विचारों के साथ समस्याओं का समाधान करने तक अपग्रेड करने का लक्ष्य रखता है।
दोनों Auto-GPT और GPT-Engineer GPT 3.5 और GPT-4 की शक्ति से सुसज्जित हैं। यह कोड तर्क को समझता है, कई फ़ाइलों को जोड़ता है, और विकास प्रक्रिया को तेज़ करता है।
Auto-GPT की कार्यक्षमता का सार इसके AI एजेंटों में निहित है। इन एजेंटों को विशिष्ट कार्यों को निष्पादित करने के लिए प्रोग्राम किया जाता है, जिनमें से कुछ निर्णय लेने की रणनीतिक आवश्यकता वाले जटिल कार्य होते हैं। हालांकि, ये AI एजेंट उपयोगकर्ता द्वारा निर्धारित सीमाओं के भीतर कार्य करते हैं। एपीआई के माध्यम से अपनी पहुंच को नियंत्रित करके, उपयोगकर्ता यह निर्धारित कर सकते हैं कि AI किस हद तक कार्य कर सकता है।
उदाहरण के लिए, यदि ChatGPT के साथ एकीकृत एक चैट वेब ऐप बनाने का कार्य सौंपा जाता है, तो Auto-GPT स्वतंत्र रूप से इस लक्ष्य को कार्रवाई योग्य चरणों में तोड़ देता है, जैसे कि एक HTML फ्रंट-एंड या पायथन बैक-एंड स्क्रिप्ट बनाना। जबकि ऐप स्वतंत्र रूप से इन प्रोम्प्ट्स का उत्पादन करता है, उपयोगकर्ता अभी भी उन्हें मॉनिटर और संशोधित कर सकते हैं। जैसा कि AutoGPT के निर्माता @SigGravitas द्वारा दिखाया गया है, यह पायथन पर आधारित एक परीक्षण कार्यक्रम बनाने और निष्पादित करने में सक्षम है।
https://twitter.com/SigGravitas/status/1642181498278408193
जबकि नीचे दिया गया आरेख एक स्वायत्त AI एजेंट की एक अधिक सामान्य वास्तुकला का वर्णन करता है, यह प्रक्रिया के पीछे की प्रक्रिया में मूल्यवान अंतर्दृष्टि प्रदान करता है।

स्वायत्त AI एजेंट वास्तुकला
प्रक्रिया OpenAI API कुंजी को सत्यापित करके और विभिन्न पैरामीटर को आरंभ करके शुरू होती है, जिसमें अल्पकालिक स्मृति और डेटाबेस सामग्री शामिल है। एक बार कुंजी डेटा को एजेंट में पास किया जाता है, तो मॉडल GPT3.5/GPT4 के साथ बातचीत करता है ताकि प्रतिक्रिया प्राप्त की जा सके। इस प्रतिक्रिया को तब JSON प्रारूप में परिवर्तित किया जाता है, जिसे एजेंट विभिन्न कार्यों को निष्पादित करने के लिए व्याख्या करता है, जैसे कि ऑनलाइन खोज करना, फ़ाइलें पढ़ना या लिखना, या यहां तक कि कोड चलाना। Auto-GPT एक पूर्व-प्रशिक्षित मॉडल का उपयोग करता है ताकि इन प्रतिक्रियाओं को एक डेटाबेस में संग्रहीत किया जा सके, और भविष्य के इंटरैक्शन इस संग्रहीत जानकारी का उपयोग संदर्भ के लिए करते हैं। लूप तब तक जारी रहता है जब तक कि कार्य पूरा नहीं हो जाता।
Auto-GPT और GPT-Engineer के लिए सेटअप गाइड
आगामी उपकरण जैसे GPT-Engineer और Auto-GPT की स्थापना आपकी विकास प्रक्रिया को सुव्यवस्थित कर सकती है। नीचे दोनों उपकरण स्थापित और कॉन्फ़िगर करने में आपकी मदद करने के लिए एक संरचित गाइड दिया गया है।
Auto-GPT
Auto-GPT सेट अप करना जटिल लग सकता है, लेकिन सही चरणों के साथ, यह सीधा हो जाता है। यह गाइड Auto-GPT सेट अप करने की प्रक्रिया को कवर करता है और इसके विविध परिदृश्यों में अंतर्दृष्टि प्रदान करता है।
1. पूर्वापेक्षाएँ:
- पायथन वातावरण: सुनिश्चित करें कि आपके पास पायथन 3.8 या बाद का संस्करण स्थापित है। आप पायथन को इसकी आधिकारिक वेबसाइट से प्राप्त कर सकते हैं।
- यदि आप रिपॉजिटरी क्लोन करने की योजना बना रहे हैं, तो गिट स्थापित करें।
- OpenAI API कुंजी: OpenAI के साथ बातचीत करने के लिए, एक API कुंजी आवश्यक है। अपने OpenAI खाते से कुंजी प्राप्त करें

ओपन एआई एपीआई कुंजी जनरेशन
मेमोरी बैकेंड विकल्प: एक मेमोरी बैकेंड AutoGPT के लिए एक स्टोरेज तंत्र के रूप में कार्य करता है ताकि यह अपने संचालन के लिए आवश्यक डेटा तक पहुंच सके। AutoGPT दोनों अल्पकालिक और दीर्घकालिक भंडारण क्षमताओं का उपयोग करता है। पाइनकोन, मिलवस, रेडिस, और अन्य कुछ विकल्प हैं जो उपलब्ध हैं।
2. अपना कार्यक्षेत्र सेट अप करें:
- एक आभासी वातावरण बनाएं:
python3 -m venv myenv - वातावरण को सक्रिय करें:
- मैकओएस या लिनक्स:
source myenv/bin/activate
- मैकओएस या लिनक्स:
3. स्थापना:
- Auto-GPT रिपॉजिटरी को क्लोन करें (सुनिश्चित करें कि आपके पास गिट स्थापित है):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - सुनिश्चित करने के लिए कि आप Auto-GPT के संस्करण 0.2.2 के साथ काम कर रहे हैं, आप
git checkout stable-0.2.2पर जाना चाहते हैं - डाउनलोड की गई रिपॉजिटरी में नेविगेट करें:
cd Auto-GPT - आवश्यक निर्भरताएं स्थापित करें:
pip install -r requirements.txt
4. कॉन्फ़िगरेशन:
- मुख्य
/Auto-GPTनिर्देशिका में.env.templateढूंढें। इसे डुप्लिकेट करें और इसे.envनाम दें .envखोलें और अपनी OpenAI API कुंजी कोOPENAI_API_KEY=के बगल में सेट करें- इसी तरह, यदि आप पाइनकोन या अन्य मेमोरी बैकेंड का उपयोग करना चाहते हैं, तो
.envफ़ाइल को अपनी पाइनकोन API कुंजी और क्षेत्र के साथ अपडेट करें
5. कमांड लाइन निर्देश:
Auto-GPT एक समृद्ध सेट ऑफ कमांड-लाइन तर्क प्रदान करता है जो इसके व्यवहार को अनुकूलित करने के लिए:
- सामान्य उपयोग:
- सहायता प्रदर्शित करें:
python -m autogpt --help - AI सेटिंग्स को समायोजित करें:
python -m autogpt --ai-settings <filename> - एक मेमोरी बैकेंड निर्दिष्ट करें:
python -m autogpt --use-memory <memory-backend>
- सहायता प्रदर्शित करें:

AutoGPT in CLI
6. Auto-GPT लॉन्च करना:
एक बार कॉन्फ़िगरेशन पूरा हो जाने के बाद, निम्नलिखित का उपयोग करके Auto-GPT आरंभ करें:
- लिनक्स या मैक:
./run.sh start - विंडोज:
.run.bat
डॉकर एकीकरण (सिफारिशित सेटअप दृष्टिकोण)
उन लोगों के लिए जो Auto-GPT को कंटेनराइज़ करना चाहते हैं, डॉकर एक सुव्यवस्थित दृष्टिकोण प्रदान करता है। हालांकि, ध्यान रखें कि डॉकर की प्रारंभिक स्थापना थोड़ी जटिल हो सकती है। डॉकर की स्थापना गाइड का संदर्भ लें सहायता के लिए।
अब निम्नलिखित चरणों का पालन करके OpenAI API कुंजी को संशोधित करें और सुनिश्चित करें कि डॉकर पृष्ठभूमि में चल रहा है। अब AutoGPT की मुख्य निर्देशिका में जाएं और अपने टर्मिनल पर निम्नलिखित चरणों का पालन करें
- डॉकर छवि बनाएं:
docker build -t autogpt . - अब चलाएं:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
डॉकर-कॉम्पोज़ के साथ:
- चलाएं:
docker-compose run --build --rm auto-gpt - अतिरिक्त अनुकूलन के लिए, आप अतिरिक्त तर्क एकीकृत कर सकते हैं। उदाहरण के लिए, –gpt3only और –continuous दोनों के साथ चलाने के लिए:
docker-compose run --rm auto-gpt --gpt3only--continuous - दिया गया है कि Auto-GPT में बड़े डेटासेट से सामग्री उत्पन्न करने में व्यापक स्वतंत्रता है, इसमें दुर्भाग्यपूर्ण वेब स्रोतों तक पहुंचने का जोखिम हो सकता है
जोखिमों को कम करने के लिए, Auto-GPT को एक आभासी कंटेनर में चलाएं, जैसे कि डॉकर। इससे यह सुनिश्चित होता है कि कोई भी संभावित रूप से हानिकारक सामग्री आभासी स्थान में ही सीमित रहती है, आपकी बाहरी फ़ाइलों और सिस्टम को अछूता रखती है। वैकल्पिक रूप से, विंडोज सैंडबॉक्स एक विकल्प है, हालांकि यह प्रत्येक सत्र के बाद रीसेट हो जाता है और अपनी स्थिति को बनाए नहीं रखता है।
सुरक्षा के लिए, हमेशा Auto-GPT को एक आभासी वातावरण में चलाएं, यह सुनिश्चित करते हुए कि आपकी प्रणाली अप्रत्याशित आउटपुट से सुरक्षित रहती है।
दिया गया है कि इसके बावजूद, आपको अभी भी अपने वांछित परिणाम प्राप्त करने में असमर्थ हो सकते हैं। Auto-GPT उपयोगकर्ताओं ने पुनरावृत्ति मुद्दों की सूचना दी जब वे एक फ़ाइल में लिखने का प्रयास करते हैं, अक्सर फ़ाइल नाम में समस्या के कारण असफल प्रयासों का सामना करते हैं। यह एक ऐसी त्रुटि है: Auto-GPT (रिलीज 0.2.2) फ़ाइल में लिखने के बाद पाठ को जोड़ने में विफल रहा: त्रुटि "write_to_file returned: त्रुटि: फ़ाइल पहले से ही अपडेट की जा चुकी है
इसे संबोधित करने के लिए विभिन्न समाधान संबंधित गिटहब थ्रेड पर चर्चा किए गए हैं।
GPT-Engineer
GPT-Engineer वर्कफ़्लो:
- प्रोम्प्ट परिभाषा: अपनी परियोजना का एक विस्तृत विवरण प्राकृतिक भाषा में तैयार करें।
- कोड जेनरेशन: आपके प्रोम्प्ट के आधार पर, GPT-Engineer कोड स्निपेट, फ़ंक्शन, या यहां तक कि पूरी ऐप्लिकेशन बनाने का काम करता है।
- रिफाइनमेंट और ऑप्टिमाइजेशन: जेनरेशन के बाद, हमेशा सुधार की गुंजाइश होती है। डेवलपर्स जेनरेट किए गए कोड को संशोधित कर सकते हैं ताकि यह विशिष्ट आवश्यकताओं को पूरा करे और गुणवत्ता को सुनिश्चित करे।
GPT-Engineer सेट अप करने की प्रक्रिया को एक आसान अनुसरण गाइड में संक्षेपित किया गया है। यह एक चरण-दर-चरण विवरण है:
1. पर्यावरण तैयार करना: शुरू करने से पहले, सुनिश्चित करें कि आपके पास अपनी परियोजना निर्देशिका तैयार है। एक टर्मिनल खोलें और नीचे दिए गए कमांड चलाएं
- एक नई निर्देशिका बनाएं जिसका नाम ‘वेबसाइट’ है:
mkdir website- निर्देशिका में जाएं:
cd website
2. रिपॉजिटरी क्लोन करें: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. नेविगेट और निर्भरताएं स्थापित करें: एक बार क्लोन हो जाने के बाद, निर्देशिका में स्विच करें cd gpt-engineer और सभी आवश्यक निर्भरताएं स्थापित करें make install
4. आभासी वातावरण सक्रिय करें: अपने ऑपरेटिंग सिस्टम के आधार पर, बनाई गई आभासी वातावरण को सक्रिय करें।
- मैकओएस/लिनक्स के लिए:
source venv/bin/activate
- विंडोज के लिए, यह थोड़ा अलग है क्योंकि एपीआई कुंजी सेटअप के कारण:
set OPENAI_API_KEY=[your api key]
5. कॉन्फ़िगरेशन – एपीआई कुंजी सेटअप: OpenAI के साथ बातचीत करने के लिए, आपको एक एपीआई कुंजी की आवश्यकता होगी। यदि आपके पास पहले से नहीं है, तो OpenAI प्लेटफ़ॉर्म पर साइन अप करें, फिर:
- मैकओएस/लिनक्स के लिए:
export OPENAI_API_KEY=[your api key]
- विंडोज के लिए (जैसा कि पहले उल्लेख किया गया है):
set OPENAI_API_KEY=[your api key]
6. परियोजना प्रारंभिकरण और कोड जेनरेशन: GPT-Engineer की जादू main_prompt फ़ाइल के साथ शुरू होती है जो projects फ़ोल्डर में पाई जाती है।
- यदि आप एक नई परियोजना शुरू करना चाहते हैं:
cp -r projects/example/ projects/website
यहां, ‘वेबसाइट’ को अपने चुने हुए परियोजना नाम से बदलें।
- एक टेक्स्ट एडिटर का उपयोग करके
main_promptफ़ाइल को संपादित करें, अपनी परियोजना की आवश्यकताओं को लिखें।

- एक बार जब आप प्रोम्प्ट से संतुष्ट हों, तो चलाएं:
gpt-engineer projects/website
आपका जेनरेट किया गया कोड workspace निर्देशिका में स्थित होगा, जो परियोजना फ़ोल्डर के भीतर है।
7. पोस्ट-जेनरेशन: जबकि GPT-Engineer शक्तिशाली है, यह हमेशा सही नहीं हो सकता है। जेनरेट किए गए कोड की जांच करें, यदि आवश्यक हो तो मैनुअल बदलाव करें, और सुनिश्चित करें कि सब कुछ सुचारु रूप से चल रहा है।
उदाहरण रन
प्रोम्प्ट:
“मैं एक बुनियादी स्ट्रीमलिट ऐप विकसित करना चाहता हूं जो पायथन में उपयोगकर्ता डेटा को इंटरैक्टिव चार्ट के माध्यम से दृश्य化 करता है। ऐप को उपयोगकर्ताओं को एक सीएसवी फ़ाइल अपलोड करने, चार्ट का प्रकार चुनने (जैसे बार, पाई, लाइन), और गतिशील रूप से डेटा दृश्य化 करने की अनुमति देनी चाहिए। यह पांडास जैसे लाइब्रेरी का उपयोग डेटा मैनिपुलेशन के लिए और प्लॉटली का उपयोग दृश्यीकरण के लिए कर सकता है।”
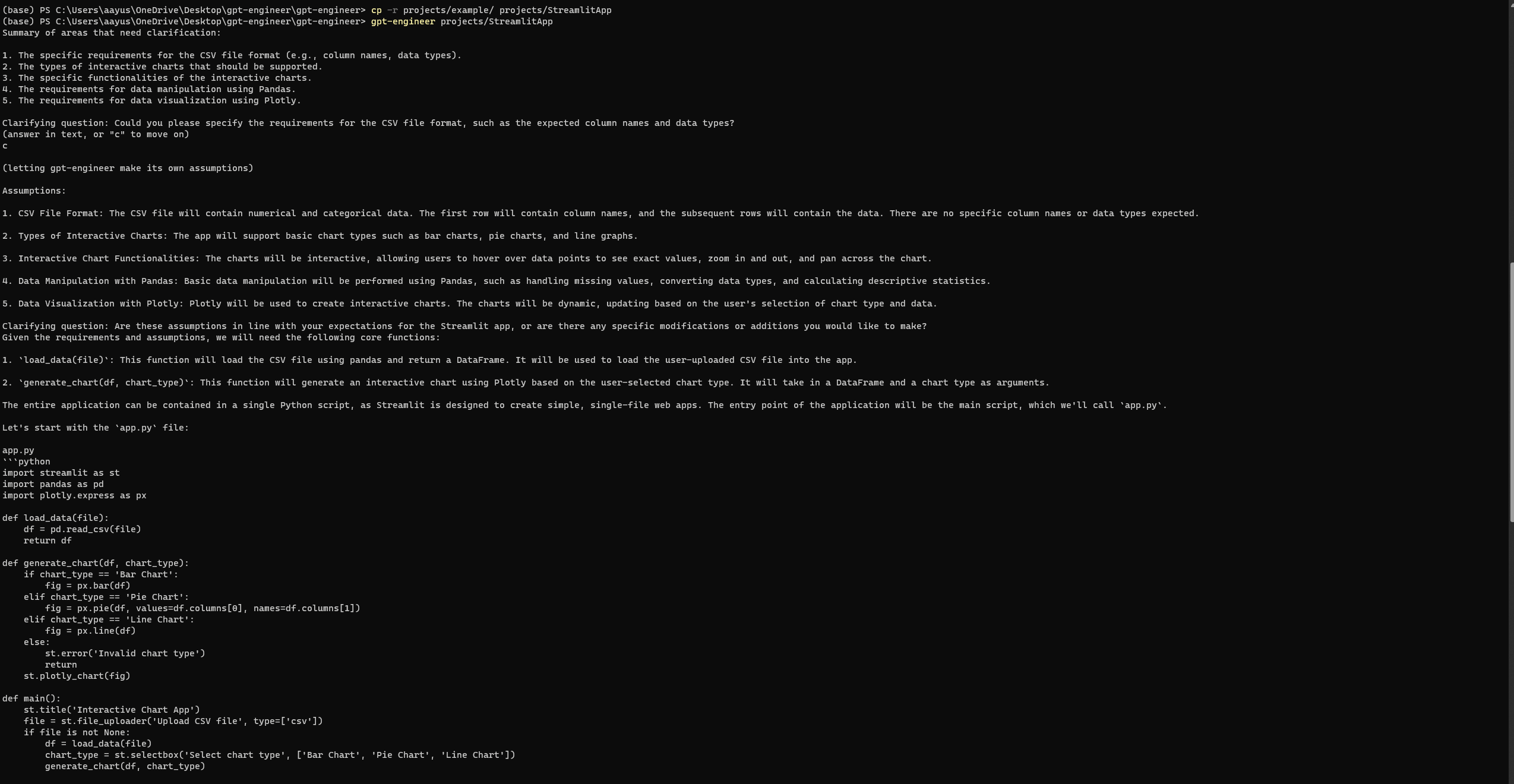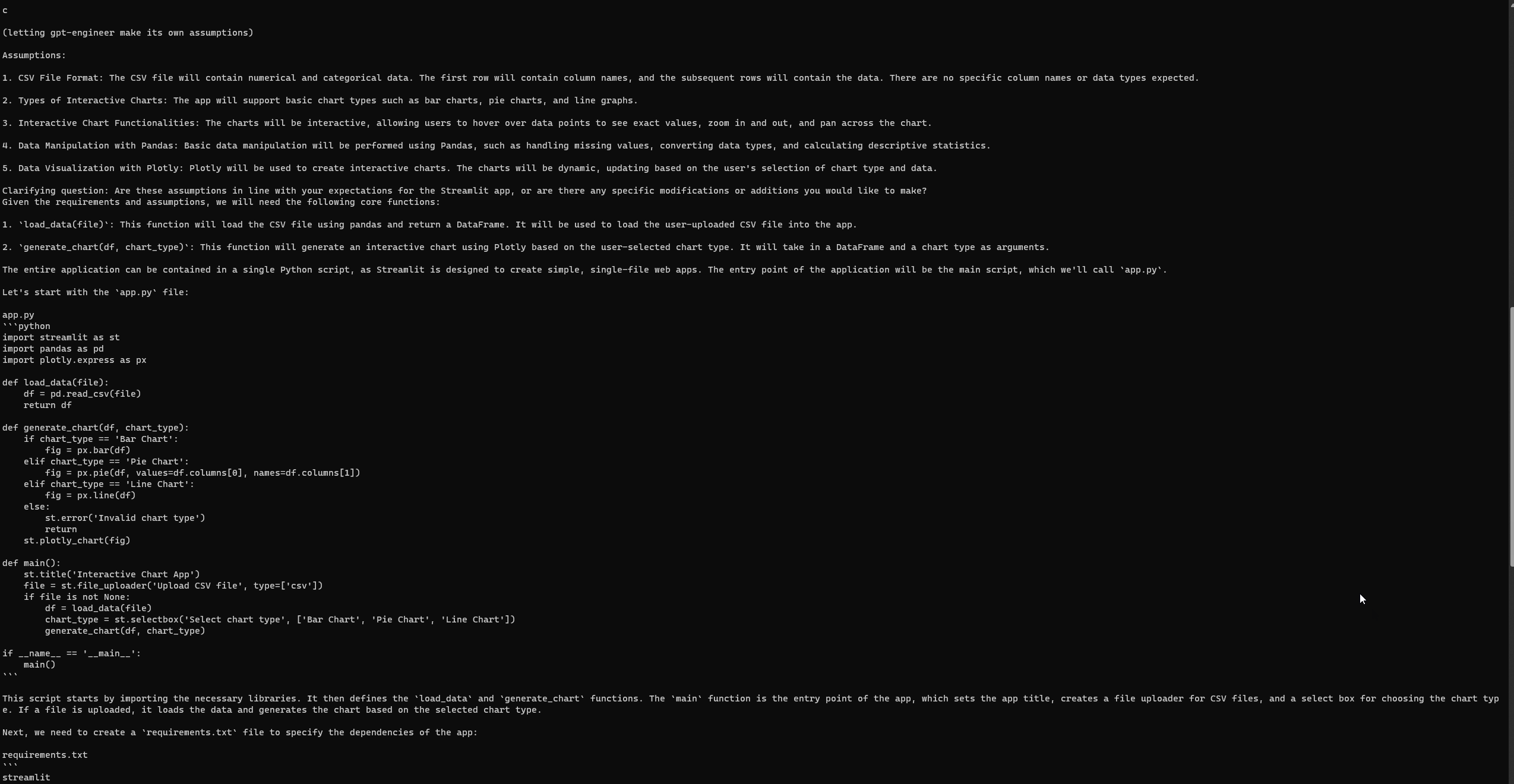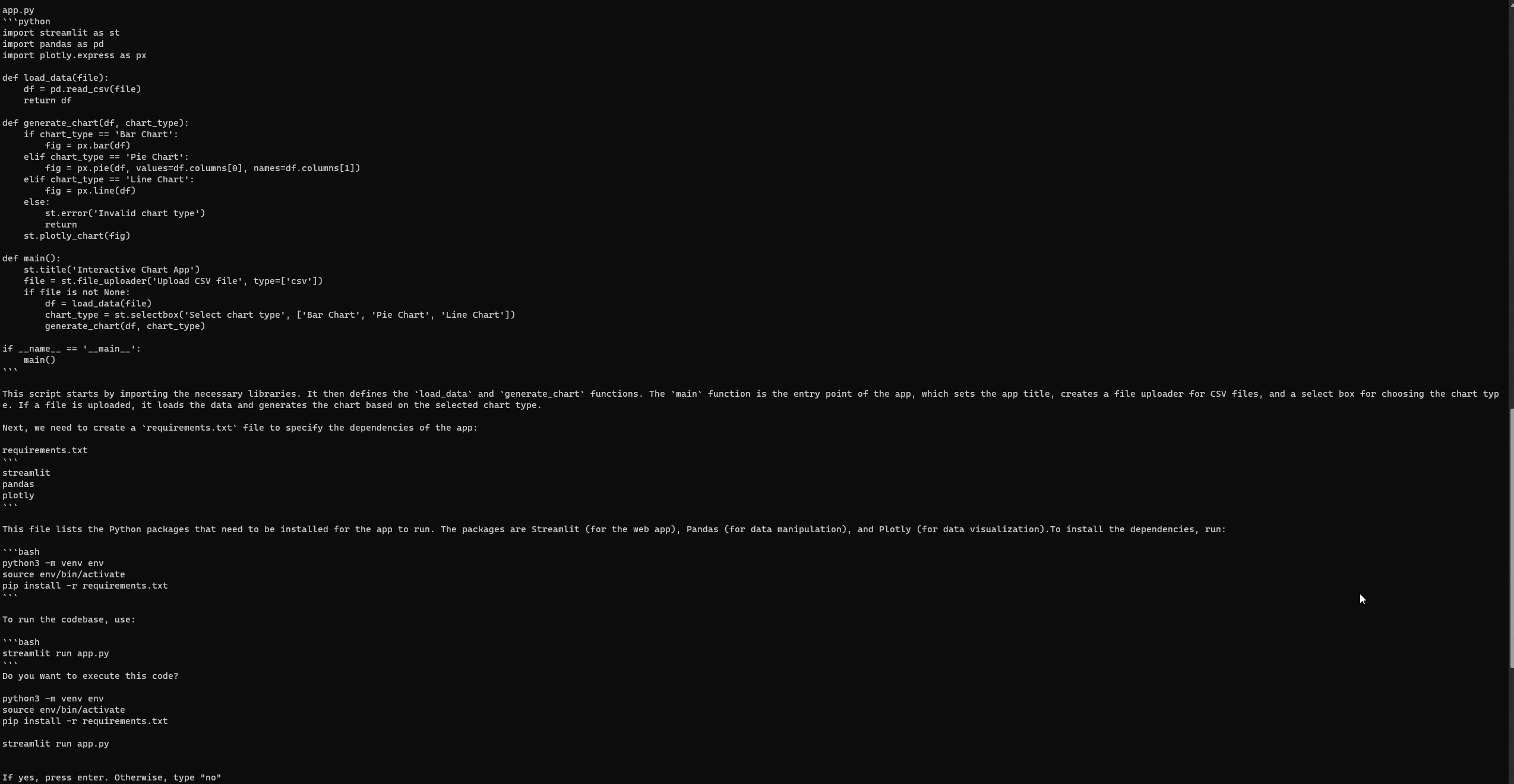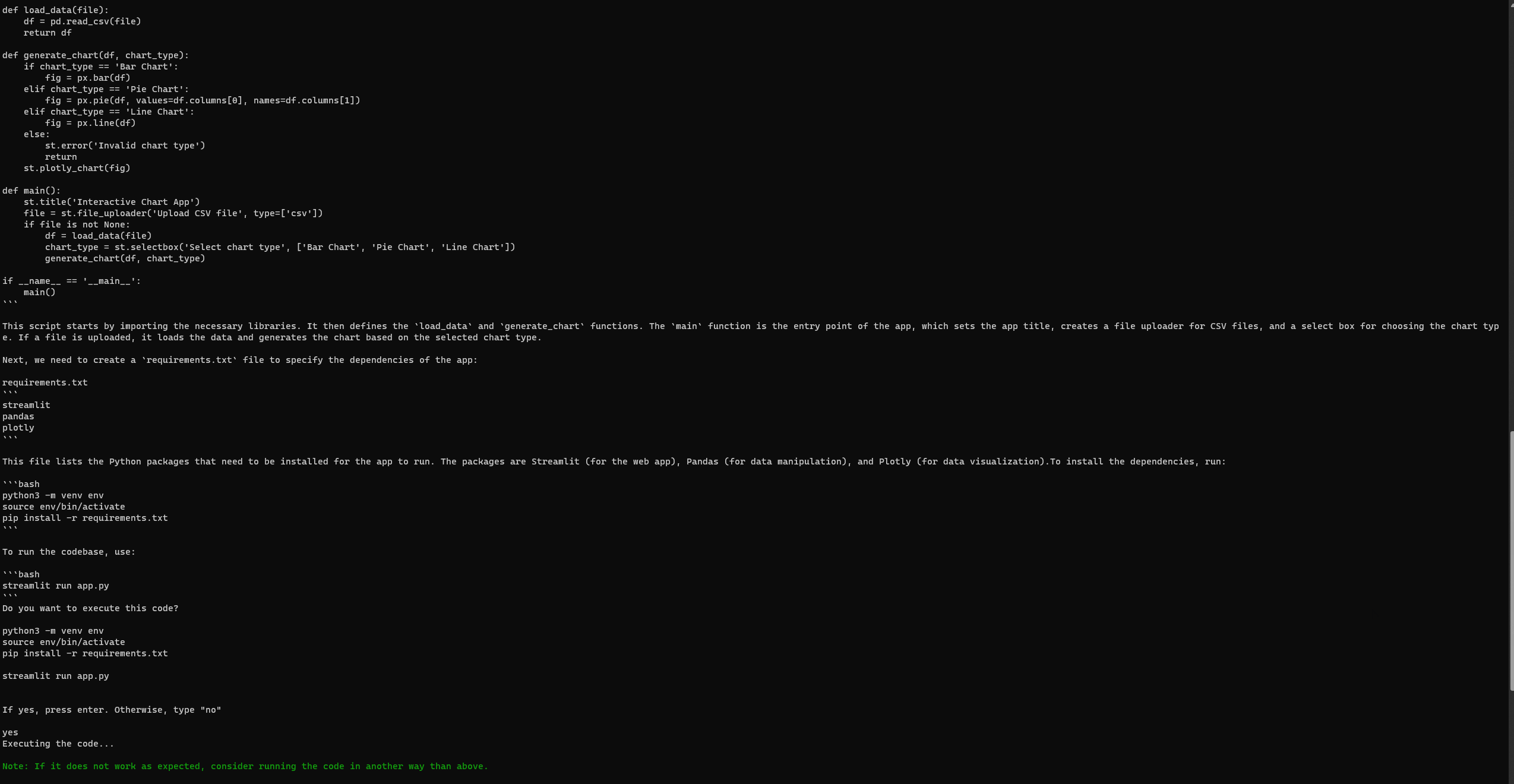
इंजीनियरिंग-GPT सेट अप और चलाना
GPT-Engineer की तरह, Auto-GPT कभी-कभी त्रुटियों का सामना कर सकता है, यहां तक कि पूरी स्थापना के बाद भी। हालांकि, अपने तीसरे प्रयास पर, मैं सफलतापूर्वक निम्नलिखित स्ट्रीमलिट वेबपेज तक पहुंच गया। किसी भी त्रुटि की समीक्षा करने के लिए आधिकारिक GPT-Engineer रिपॉजिटरी के समस्या पृष्ठ पर जाएं।

इंजीनियरिंग-GPT का उपयोग करके जेनरेट किया गया स्ट्रीमलिट ऐप
AI एजेंटों की वर्तमान बोतलेंक
परिचालन व्यय
Auto-GPT द्वारा निष्पादित एक एकल कार्य में कई चरण शामिल हो सकते हैं। महत्वपूर्ण रूप से, इनमें से प्रत्येक चरण को व्यक्तिगत रूप से बिल किया जा सकता है, जिससे लागत बढ़ जाती है। Auto-GPT पुनरावृत्ति लूप में फंस सकता है, जो अपने वादे के परिणामों को वितरित करने में विफल रहता है। ऐसी घटनाएं इसकी विश्वसनीयता को खतरे में डालती हैं और इसके निवेश को कमजोर करती हैं।
कल्पना कीजिए कि आप Auto-GPT के साथ एक छोटा निबंध बनाना चाहते हैं। निबंध की आदर्श लंबाई 8K टोकन है, लेकिन निर्माण प्रक्रिया के दौरान, मॉडल कई मध्यवर्ती चरणों में गहराई से जाता है ताकि सामग्री को अंतिम रूप दिया जा सके। यदि आप GPT-4 का उपयोग 8k संदर्भ लंबाई के साथ कर रहे हैं, तो इनपुट के लिए आपको $0.03 का शुल्क देना होगा। और आउटपुट के लिए, लागत $0.06 होगी। अब, मान लें कि मॉडल एक अनपेक्षित लूप में चलता है, कुछ हिस्सों को बार-बार दोहराता है। न केवल प्रक्रिया लंबी हो जाती है, बल्कि प्रत्येक पुनरावृत्ति लागत में भी जुड़ जाती है।
इसे सुरक्षित करने के लिए:
सीमाएं निर्धारित करें OpenAI बिलिंग और सीमा पर:
- हार्ड सीमा: आपके द्वारा निर्धारित सीमा से परे उपयोग को प्रतिबंधित करता है।
- सॉफ्ट सीमा: सीमा पार होने पर आपको एक ईमेल अलर्ट भेजता है।
कार्यक्षमता सीमाएं
Auto-GPT की क्षमताएं, जैसा कि इसके स्रोत कोड में चित्रित किया गया है, कुछ सीमाओं के साथ आती हैं। इसकी समस्या-समाधान रणनीतियां इसके अंतर्निहित कार्यों और GPT-4 के API द्वारा प्रदान की गई पहुंच द्वारा शासित होती हैं। गहन चर्चा और संभावित कार्यों के लिए, Auto-GPT चर्चा पर जाने पर विचार करें।
AI का श्रम बाजार पर प्रभाव
AI और श्रम बाजारों के बीच गतिशीलता निरंतर विकसित हो रही है और व्यापक रूप से इस शोध पत्र में दस्तावेज किया गया है। एक प्रमुख निष्कर्ष यह है कि जबकि तकनीकी प्रगति अक्सर कुशल श्रमिकों को लाभान्वित करती है, यह दिनचर्या कार्यों में शामिल उन लोगों के लिए जोखिम पैदा करती है। वास्तव में, तकनीकी प्रगति कुछ कार्यों को विस्थापित कर सकती है, लेकिन साथ ही साथ विविध, श्रम-गहन कार्यों के लिए मार्ग प्रशस्त कर सकती है।

अनुमानित 80% अमेरिकी श्रमिकों को लगता है कि एलएलएम (भाषा सीखने वाले मॉडल) उनके दैनिक कार्यों में से लगभग 10% को प्रभावित करेंगे। यह आंकड़ा AI और मानव भूमिकाओं के विलय को रेखांकित करता है।
AI की दोहरी भूमिका कार्यबल में:
- सकारात्मक पहलू: AI ग्राहक सेवा से लेकर वित्तीय सलाह तक के कई कार्यों को स्वचालित कर सकता है, जो छोटे उद्यमों को राहत देता है जिनके पास समर्पित टीमों के लिए धन नहीं है।
- चिंताएं: स्वचालन का लाभ नौकरी के नुकसान के बारे में चिंताओं को उठाता है, विशेष रूप से उन क्षेत्रों में जहां मानव भागीदारी महत्वपूर्ण है, जैसे कि ग्राहक समर्थन। इसके साथ ही गोपनीय डेटा तक AI की पहुंच से जुड़े नैतिक जाल का भी मुद्दा है। यह पारदर्शिता, जवाबदेही और AI के नैतिक उपयोग को सुनिश्चित करने के लिए एक मजबूत बुनियादी ढांचे की मांग करता है।
निष्कर्ष
स्पष्ट रूप से, ChatGPT, Auto-GPT, और GPT-Engineer जैसे उपकरण प्रौद्योगिकी और इसके उपयोगकर्ताओं के बीच की बातचीत को फिर से परिभाषित करने के लिए तैयार हैं। ओपन-सोर्स आंदोलनों की जड़ों के साथ, ये AI एजेंट मशीन स्वतंत्रता की संभावनाओं को प्रदर्शित करते हैं, कार्यों को अनुसूची से लेकर सॉफ्टवेयर विकास तक सुव्यवस्थित करते हैं।
जैसा कि हम एक ऐसे भविष्य में आगे बढ़ रहे हैं जहां AI हमारे दैनिक दिनचर्या में गहराई से एकीकृत हो जाता है, AI की क्षमताओं को अपनाने और मानव भूमिकाओं को सुरक्षित रखने के बीच संतुलन बनाना महत्वपूर्ण हो जाता है। व्यापक स्पेक्ट्रम पर, AI-श्रम बाजार गतिविधि एक दोहरी छवि प्रस्तुत करती है – विकास के अवसर और चुनौतियां, जो तकनीकी नैतिकता और पारदर्शिता के जानबूझकर एकीकरण की मांग करती है।












