कृत्रिम बुद्धिमत्ता
AI नERVOUS स्पीकर्स को वीडियोकॉन्फ़्रेंस के दौरान ‘रूम को पढ़ने’ में मदद करता है

2013 में, एक आम भय के बारे में एक मतदान में यह निर्धारित किया गया कि सार्वजनिक बोलने की संभावना अधिकांश उत्तरदाताओं के लिए मृत्यु की संभावना से भी बदतर थी। इस सिंड्रोम को ग्लोसोफोबिया के रूप में जाना जाता है।
कोविड-चालित ‘व्यक्ति में’ बैठकों से ऑनलाइन ज़ूम सम्मेलनों का संक्रमण, जैसे ज़ूम और गूगल स्पेस जैसे प्लेटफ़ॉर्म पर, आश्चर्यजनक रूप से, स्थिति में सुधार नहीं किया है। जहां बैठक में कई प्रतिभागियों की संख्या होती है, हमारी प्राकृतिक खतरे का आकलन करने की क्षमता कम-रिज़ॉल्यूशन प्रतिभागियों की पंक्तियों और आइकनों और सूक्ष्म दृश्य संकेतों को पढ़ने में कठिनाई के कारण बाधित होती है। स्काइप, उदाहरण के लिए, गैर-मौखिक संकेतों को प्रसारित करने के लिए एक खराब प्लेटफ़ॉर्म पाया गया है।
सार्वजनिक बोलने के प्रदर्शन पर अनुमानित रुचि और प्रतिक्रिया के प्रभाव अब अच्छी तरह से प्रलेखित हैं, और अधिकांश लोगों के लिए स्वाभाविक रूप से स्पष्ट हैं। अपारदर्शी दर्शक प्रतिक्रिया वक्ताओं को संकोच करने और फ़िलर भाषण में वापस आने का कारण बन सकती है, यह जानने के लिए कि उनके तर्क किसी भी तरह से सहमति, निरादर या उदासीनता के साथ मिल रहे हैं या नहीं, अक्सर वक्ता और उनके श्रोताओं दोनों के लिए एक असहज अनुभव पैदा करते हैं।
कोविड प्रतिबंधों और सावधानियों से प्रेरित ऑनलाइन वीडियोकॉन्फ़्रेंस की अप्रत्याशित प्रवृत्ति के दबाव में, समस्या तर्कसंगत रूप से खराब हो रही है, और कंप्यूटर विजन और प्रभाव अनुसंधान समुदायों में पिछले कुछ वर्षों में कई सुधारात्मक दर्शक प्रतिक्रिया योजनाओं का सुझाव दिया गया है।
हार्डवेयर-फ़ोकस्ड समाधान
इनमें से अधिकांश, हालांकि, अतिरिक्त उपकरण या जटिल सॉफ़्टवेयर को शामिल करते हैं जो गोपनीयता या लॉजिस्टिक मुद्दों को बढ़ा सकते हैं – अपेक्षाकृत उच्च-लागत वाले या अन्य संसाधन-सीमित दृष्टिकोण जो महामारी से पहले हैं। 2001 में, एमआईटी ने गैल्वैक्टिवेटर का प्रस्ताव दिया, एक हाथ से पहनने वाला उपकरण जो दर्शक प्रतिभागी की भावनात्मक स्थिति का अनुमान लगाता है, एक दिन लंबे सम्मेलन के दौरान परीक्षण किया गया था।
[कैप्शन id=”अटैचमेंट_181039″ align=”alignnone” width=”432″]
श्रोताओं को जोड़ने के लिए कई प्रयास किए गए हैं, जिनमें हृदय गति की निगरानी, जटिल शरीर-वorn उपकरण का उपयोग करने के लिए इलेक्ट्रोएन्सेफ्लोग्राफी का लाभ उठाने, ‘चीयर मीटर’, कंप्यूटर-दृष्टि-आधारित भावना पहचान डेस्क-आधारित कार्यकर्ताओं के लिए, और वक्ता के भाषण के दौरान दर्शकों द्वारा भेजे गए भावनाओं का उपयोग शामिल है।
[कैप्शन id=”अटैचमेंट_181035″ align=”alignnone” width=”747″]
निजी क्षेत्र ने दर्शक विश्लेषण के लाभदायक क्षेत्र के रूप में गेज़ अनुमान और ट्रैकिंग में विशेष रुचि ली है – प्रणाली जहां प्रत्येक दर्शक (जो अपनी बारी में बोलने वाला हो सकता है), ओकुलर ट्रैकिंग के अधीन है, जो जुड़ाव और अनुमोदन के सूचक के रूप में है।
इन सभी तरीकों में उच्च घर्षण है। उनमें से अधिकांश अतिरिक्त उपकरण या जटिल सॉफ़्टवेयर की आवश्यकता होती है जो गोपनीयता या लॉजिस्टिक मुद्दों को बढ़ा सकते हैं – अपेक्षाकृत उच्च-लागत वाले या अन्य संसाधन-सीमित दृष्टिकोण जो महामारी से पहले हैं।
इसलिए, सामान्य टूल्स के अलावा कुछ भी नहीं के आधार पर न्यूनतम सिस्टम का विकास पिछले 18 महीनों में दिलचस्पी का विषय बन गया है।
दर्शक अनुमोदन की रिपोर्टिंग विवेकपूर्ण
इस उद्देश्य के लिए, टोक्यो विश्वविद्यालय और कार्नेगी मेलन विश्वविद्यालय के बीच एक नए अनुसंधान सहयोग में एक नवीन प्रणाली प्रदान की जाती है जो मानक वीडियोकॉन्फ़्रेंस टूल्स (जैसे ज़ूम) पर सवारी कर सकती है, केवल एक वेब-कैम-सक्षम वेबसाइट का उपयोग करके जिस पर हल्के गेज़ और मुद्रा अनुमान सॉफ़्टवेयर चल रहा हो। इस तरह से भी स्थानीय ब्राउज़र प्लगइन्स की आवश्यकता से बचा जा सकता है।
उपयोगकर्ता के सिर की हरकत और अनुमानित नज़र का ध्यान डेटा में अनुवादित किया जाता है जो वक्ता को वापस दृश्य बनाता है, जिससे सामग्री के जुड़ाव की डिग्री का ‘लाइव’ लिटमस परीक्षण होता है – और कम से कम एक अस्पष्ट संकेतक जहां वक्ता दर्शकों की रुचि खो सकता है।
[कैप्शन id=”अटैचमेंट_181036″ align=”alignnone” width=”780″]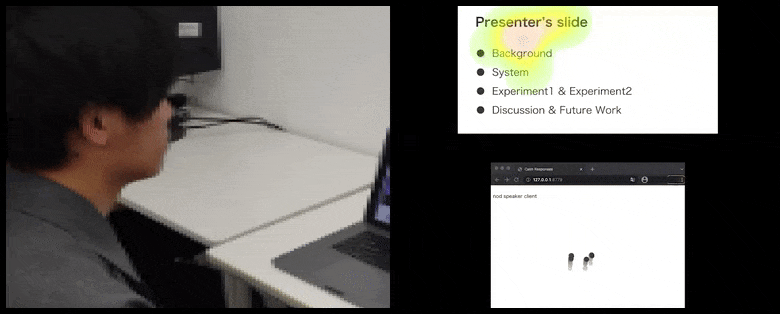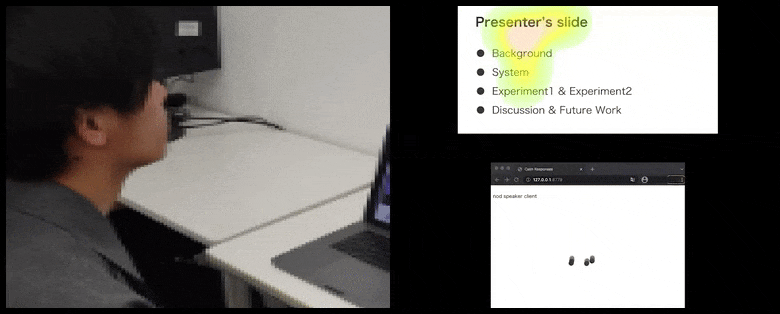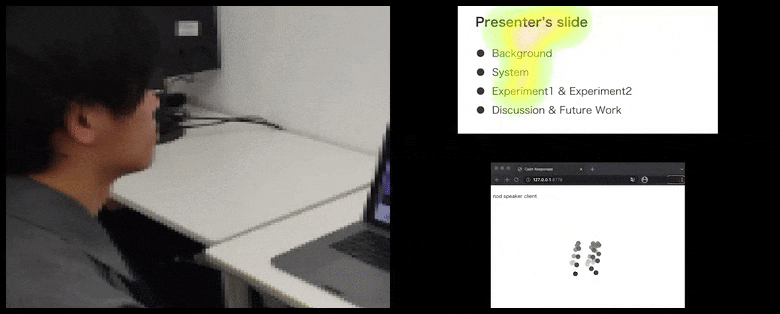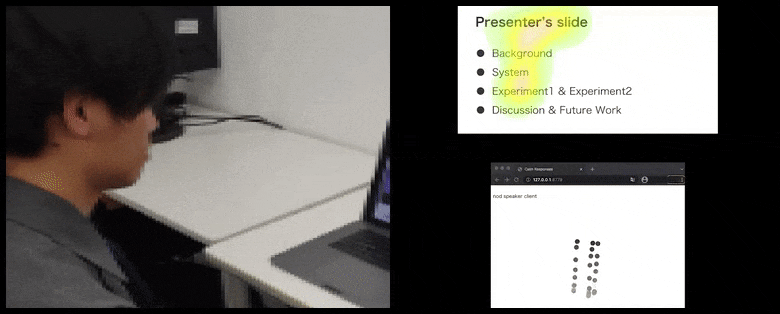 कैल्मरेस्पॉन्सेस के साथ, उपयोगकर्ता ध्यान और सिर की हरकत को दर्शक प्रतिक्रिया के पूल में जोड़ा जाता है और एक दृश्य प्रतिनिधित्व में अनुवादित किया जाता है जो वक्ता को लाभान्वित कर सकता है। लेख के अंत में अधिक विवरण और उदाहरणों के लिए एम्बेडेड वीडियो देखें। स्रोत: https://www.youtube.com/watch?v=J_PhB4FCzk0[/caption]
कैल्मरेस्पॉन्सेस के साथ, उपयोगकर्ता ध्यान और सिर की हरकत को दर्शक प्रतिक्रिया के पूल में जोड़ा जाता है और एक दृश्य प्रतिनिधित्व में अनुवादित किया जाता है जो वक्ता को लाभान्वित कर सकता है। लेख के अंत में अधिक विवरण और उदाहरणों के लिए एम्बेडेड वीडियो देखें। स्रोत: https://www.youtube.com/watch?v=J_PhB4FCzk0[/caption]
अकादमिक स्थितियों में, जैसे कि ऑनलाइन व्याख्यान, छात्र पूरी तरह से वक्ता द्वारा अदृश्य हो सकते हैं, क्योंकि उन्होंने अपने वेबकैम चालू नहीं किए हैं क्योंकि वे अपनी पृष्ठभूमि या वर्तमान स्वरूप के बारे में स्वयं-सचेत हैं। कैल्मरेस्पॉन्सेस इस अन्यथा कांटेदार बाधा को वक्ता प्रतिक्रिया के लिए संबोधित कर सकता है कि यह कैसे जानता है कि वक्ता सामग्री को देख रहा है, और यदि वे सिर हिला रहे हैं, तो दर्शक को अपना कैमरा सक्षम करने की आवश्यकता नहीं है।
लेख पेपर शीर्षक कैल्मरेस्पॉन्सेस: रिमोट कम्युनिकेशन में सामूहिक दर्शक प्रतिक्रिया को प्रदर्शित करना है, और यह टोक्यो विश्वविद्यालय के दो शोधकर्ताओं और कार्नेगी मेलन विश्वविद्यालय के एक शोधकर्ता के बीच एक संयुक्त कार्य है।
लेखक एक लाइव वेब-आधारित डेमो प्रदान करते हैं, और स्रोत कोड को गिटहब पर जारी करते हैं।
कैल्मरेस्पॉन्सेस फ़्रेमवर्क
कैल्मरेस्पॉन्सेस की रुचि सिर की हरकत के बजाय सिर की हरकत में है, जो शोध (कुछ डार्विन के युग से) पर आधारित है जो यह दर्शाता है कि 80% से अधिक सभी श्रोताओं की सिर की हरकतें सिर हिलाने से बनी होती हैं (यहां तक कि जब वे असहमति व्यक्त कर रहे हों)। उसी समय, आंखों की गति को बार-बार अध्ययनों में जुड़ाव या रुचि का एक विश्वसनीय सूचक दिखाया गया है।
कैल्मरेस्पॉन्सेस एचटीएमएल, सीएसएस और जावास्क्रिप्ट के साथ लागू किया जाता है, और तीन उप-प्रणालियों से बना होता है: एक दर्शक क्लाइंट, एक वक्ता क्लाइंट, और एक सर्वर। दर्शक क्लाइंट वेबसॉकेट्स के माध्यम से उपयोगकर्ता के वेबकैम से आंखों की गति या सिर की हरकत के डेटा को क्लाउड एप्लिकेशन प्लेटफ़ॉर्म हरोकु पर पास करता है।
[कैप्शन id=”अटैचमेंट_181037″ align=”alignnone” width=”527″]
परियोजना के आंख-ट्रैकिंग खंड के लिए, शोधकर्ताओं ने वेबगेज़र का उपयोग किया, एक हल्के, जावास्क्रिप्ट-आधारित ब्राउज़र-आधारित आंख-ट्रैकिंग फ़्रेमवर्क जो कम विलंबता के साथ सीधे एक वेबसाइट से चल सकता है (ऊपर दिए गए लिंक के लिए शोधकर्ताओं के अपने वेब-आधारित कार्यान्वयन देखें)।
चूंकि गेज़ और मुद्रा अनुमान में उच्च सटीकता की आवश्यकता की तुलना में सरल कार्यान्वयन और खुरदरा, सामूहिक प्रतिक्रिया मान्यता की आवश्यकता अधिक है, इसलिए इनपुट मुद्रा डेटा को मान के अनुसार चिकना किया जाता है trướcे इसके लिए समग्र प्रतिक्रिया अनुमान के लिए विचार किया जाता है।
सिर की हरकत का मूल्यांकन जावास्क्रिप्ट लाइब्रेरी clmtrackr के माध्यम से किया जाता है, जो नियमित लैंडमार्क मीन-शिफ्ट के माध्यम से छवियों या वीडियो में पहचाने गए चेहरों पर चेहरे के मॉडल को फिट करता है। अर्थव्यवस्था और कम-विलंबता के उद्देश्य से, केवल नाक के लैंडमार्क को सक्रिय रूप से निगरानी की जाती है, क्योंकि यह सिर की हरकत को ट्रैक करने के लिए पर्याप्त है।
[कैप्शन id=”अटैचमेंट_181040″ align=”alignnone” width=”786″]![]()
हीट मैप
जबकि सिर की हरकत गतिशील गतिशील बिंदुओं द्वारा प्रस्तुत की जाती है (ऊपर दिए गए चित्र और लेख के अंत में वीडियो देखें), दृश्य ध्यान हीट मैप के रूप में रिपोर्ट किया जाता है जो वक्ता और दर्शकों को दिखाता है कि साझा प्रस्तुति स्क्रीन या वीडियोकॉन्फ़्रेंस वातावरण पर सामान्य ध्यान केंद्रित है।
[कैप्शन id=”अटैचमेंट_181041″ align=”alignnone” width=”472″]
परीक्षण
कैल्मरेस्पॉन्सेस के लिए दो परीक्षण वातावरण तैयार किए गए थे, जो एक शांत अभिलेखी अध्ययन के रूप में तीन अलग-अलग परिस्थितियों का उपयोग करते थे: ‘स्थिति बी’ (बेसलाइन) में, लेखकों ने एक आम ऑनलाइन छात्र व्याख्यान को पुन: प्रस्तुत किया, जहां अधिकांश छात्र अपने वेबकैम बंद रखते हैं, और वक्ता को दर्शकों के चेहरे दिखाई नहीं देते; ‘स्थिति सीआर-ई’ में, वक्ता गेज़ प्रतिक्रिया (हीट मैप) देख सकता था; ‘स्थिति सीआर-एन’ में, वक्ता दोनों नोडिंग और गेज़ गतिविधि देख सकता था।
पहले प्रयोगात्मक परिदृश्य में स्थिति बी और स्थिति सीआर-ई शामिल थे; दूसरे में स्थिति बी और स्थिति सीआर-एन शामिल थे। वक्ता और दर्शक दोनों से प्रतिक्रिया प्राप्त की गई।
प्रत्येक प्रयोग में, तीन कारकों का मूल्यांकन किया गया था: प्रस्तुति का वस्तुनिष्ठ और विषयगत मूल्यांकन (वक्ता द्वारा स्वयं-रिपोर्ट किए गए प्रश्नावली सहित, जो यह बताती है कि प्रस्तुति कैसे चली गई); ‘फ़िलर’ भाषण की घटनाओं की संख्या, जो क्षणिक असुरक्षा और संदेह का संकेत देती है; और गुणात्मक टिप्पणियां। ये मानदंड सामान्य मूल्यांकक हैं भाषण की गुणवत्ता और वक्ता की चिंता के लिए।
परीक्षण पूल में 38 लोग शामिल थे, जिनकी आयु 19-44 वर्ष थी, जिनमें 29 पुरुष और नौ महिलाएं शामिल थीं, जिनकी औसत आयु 24.7 वर्ष थी, सभी जापानी या चीनी थे, और सभी जापानी में धाराप्रवाह थे। उन्हें यादृच्छिक रूप से पांच समूहों में विभाजित किया गया था, जिनमें से प्रत्येक में 6-7 प्रतिभागी थे, और कोई भी विषय एक दूसरे को व्यक्तिगत रूप से नहीं जानता था।
परीक्षण ज़ूम पर किए गए थे, जिसमें पहले प्रयोग में पांच वक्ता और दूसरे में छह वक्ता प्रस्तुतियां दे रहे थैं।
[कैप्शन id=”अटैचमेंट_181042″ align=”alignnone” width=”602″]
शोधकर्ताओं का उल्लेख है कि एक वक्ता के फ़िलर में उल्लेखनीय रूप से कमी आई, और ‘स्थिति सीआर-एन’ में, वक्ता ने शायद ही कभी फ़िलर वाक्यांशों का उच्चारण किया। विस्तृत और विस्तृत परिणामों के लिए लेख देखें; हालांकि, सबसे उल्लेखनीय परिणाम वक्ताओं और दर्शक प्रतिभागियों से विषयगत मूल्यांकन में थे।
दर्शकों की टिप्पणियों में शामिल हैं:
‘मुझे लगा कि मैं प्रस्तुतियों में शामिल था” [एएन2], “मुझे यह नहीं पता था कि वक्ताओं के भाषण में सुधार हुआ था, लेकिन मैंने दूसरों की सिर की हरकत के दृश्यीकरण से एकता की भावना महसूस की।’ [एएन6]
‘मुझे यह नहीं पता था कि वक्ताओं के भाषण में सुधार हुआ था, लेकिन मैंने दूसरों की सिर की हरकत के दृश्यीकरण से एकता की भावना महसूस की।’[/caption]
निष्कर्ष
एक ऐसी प्रणाली में एक उल्लेखनीय लाभ यह है कि इसके उपयोग के बाद सभी गैर-मानक अनुपूरक प्रौद्योगिकियां पूरी तरह से गायब हो जाती हैं। कोई अवशेष ब्राउज़र प्लगइन्स नहीं हैं जिन्हें अनइंस्टॉल करने की आवश्यकता है, या जो प्रतिभागियों के दिमाग में संदेह पैदा करें कि क्या उन्हें अपने संबंधित सिस्टम पर रहना चाहिए; और उपयोगकर्ताओं को प्रक्रिया के माध्यम से मार्गदर्शन करने की आवश्यकता नहीं है (हालांकि वेब-आधारित फ़्रेमवर्क को उपयोगकर्ता द्वारा प्रारंभिक कैलिब्रेशन की एक मिनट या दो की आवश्यकता होती है), या स्थानीय सॉफ़्टवेयर, ब्राउज़र-आधारित प्लगइन्स और एक्सटेंशन को स्थापित करने की अनुमति देने की आवश्यकता नहीं है।
चूंकि गेज़ और मुद्रा अनुमान में उच्च सटीकता की आवश्यकता की तुलना में सरल कार्यान्वयन और खुरदरा, सामूहिक प्रतिक्रिया मान्यता की आवश्यकता अधिक है, यह लगभग घर्षण-मुक्त दृष्टिकोण दर्शक मूल्यांकन के लिए पर्याप्त सटीकता प्रदान करता है जो सामान्य वीडियोकॉन्फ़्रेंस परिदृश्यों में भावना और रुख विश्लेषण के लिए पर्याप्त है। सबसे महत्वपूर्ण बात, यह बहुत सस्ता है।
लेख के नीचे संबंधित परियोजना वीडियो देखें:
पहली बार 11 अप्रैल 2022 को प्रकाशित।












