
Inteligencia artificial
StreamDiffusion: una solución a nivel de canalización para generación interactiva en tiempo real

Debido a su vasto potencial y oportunidades de comercialización, particularmente en juegos, transmisión y transmisión de video, Metaverse es actualmente una de las tecnologías de más rápido crecimiento. Las aplicaciones modernas de Metaverse utilizan marcos de IA, incluidos modelos de difusión y visión por computadora, para mejorar su realismo. Un desafío importante para las aplicaciones de Metaverse es la integración de varios canales de difusión que proporcionen baja latencia y alto rendimiento, asegurando una interacción efectiva entre los humanos y estas aplicaciones.
Los marcos de IA actuales basados en difusión destacan en la creación de imágenes a partir de mensajes textuales o de imágenes, pero se quedan cortos en las interacciones en tiempo real. Esta limitación es particularmente evidente en tareas que requieren entrada continua y alto rendimiento, como gráficos de videojuegos, aplicaciones Metaverse, transmisiones y transmisión de video en vivo.
En este artículo, analizaremos StreamDiffusion, un canal de difusión en tiempo real desarrollado para generar imágenes interactivas y realistas, abordando las limitaciones actuales de los marcos basados en difusión en tareas que involucran entrada continua. StreamDiffusion es un enfoque innovador que transforma el ruido secuencial de la imagen original en eliminación de ruido por lotes, con el objetivo de permitir un alto rendimiento y flujos de fluidos. Este enfoque se aleja del método tradicional de esperar e interactuar utilizado por las empresas existentes. marcos basados en difusión. En las próximas secciones, profundizaremos en el marco StreamDiffusion en detalle, explorando su funcionamiento, arquitectura y resultados comparativos con los marcos de última generación actuales. Empecemos.
StreamDiffusion: Introducción a la generación interactiva en tiempo real
Metaverse son aplicaciones de rendimiento intensivo, ya que procesan una gran cantidad de datos, incluidos textos, animaciones, videos e imágenes en tiempo real para brindar a sus usuarios su experiencia e interfaces interactivas características. Las aplicaciones modernas de Metaverse se basan en marcos basados en inteligencia artificial que incluyen visión por computadora, procesamiento de imágenes y modelos de difusión para lograr una baja latencia y un alto rendimiento para garantizar una experiencia de usuario perfecta. Actualmente, la mayoría de las aplicaciones Metaverse dependen de la reducción de la aparición de iteraciones de eliminación de ruido para garantizar un alto rendimiento y mejorar las capacidades interactivas de la aplicación en tiempo real. Estos marcos optan por una estrategia común que implica replantear el proceso de difusión con EDO neuronales (ecuaciones diferenciales ordinarias) o reducir los modelos de difusión de varios pasos a unos pocos pasos o incluso a un solo paso. Aunque el enfoque ofrece resultados satisfactorios, tiene ciertas limitaciones, incluida una flexibilidad limitada y altos costos computacionales.
Por otro lado, StreamDiffusion es una solución a nivel de canalización que comienza desde una dirección ortogonal y mejora las capacidades del marco para generar imágenes interactivas en tiempo real al tiempo que garantiza un alto rendimiento. StreamDiffusion utiliza una estrategia simple en la que, en lugar de eliminar el ruido de la entrada original, el marco procesa por lotes el paso de eliminación de ruido. La estrategia se inspira en el procesamiento asincrónico, ya que el marco no tiene que esperar a que se complete la primera etapa de eliminación de ruido antes de poder pasar a la segunda etapa, como se demuestra en la siguiente imagen. Para abordar el problema de la frecuencia de procesamiento de U-Net y la frecuencia de entrada de forma sincrónica, el marco StreamDiffusion implementa una estrategia de cola para almacenar en caché la entrada y las salidas.
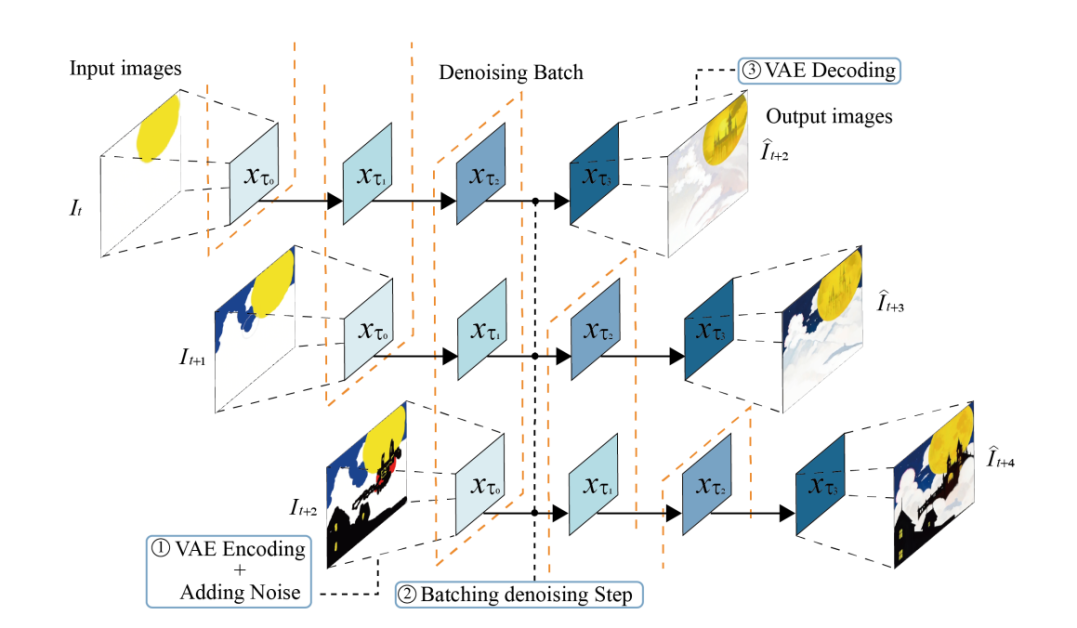
Aunque el canal StreamDiffusion busca inspiración en el procesamiento asincrónico, es único a su manera ya que implementa el paralelismo de GPU que permite que el marco utilice un único componente UNet para eliminar el ruido de una característica latente de ruido por lotes. Además, existentes tuberías basadas en difusión Enfatice las indicaciones dadas en las imágenes generadas incorporando guía sin clasificador, como resultado de lo cual las tuberías actuales están plagadas de gastos computacionales redundantes y excesivos. Para garantizar que el oleoducto StreamDiffusion no encuentre los mismos problemas, implementa un innovador RCFG o enfoque de guía sin clasificador residual que utiliza un ruido residual virtual para aproximar las condiciones negativas, lo que permite que el marco calcule las condiciones de ruido negativo en la fase inicial. etapas del proceso mismo. Además, el canal StreamDiffusion también reduce los requisitos computacionales de un canal de difusión tradicional al implementar una estrategia de filtrado de similitud estocástica que determina si el canal debe procesar las imágenes de entrada calculando las similitudes entre las entradas continuas.
El marco StreamDiffusion se basa en los aprendizajes de modelos de difusión y modelos de difusión por aceleración.
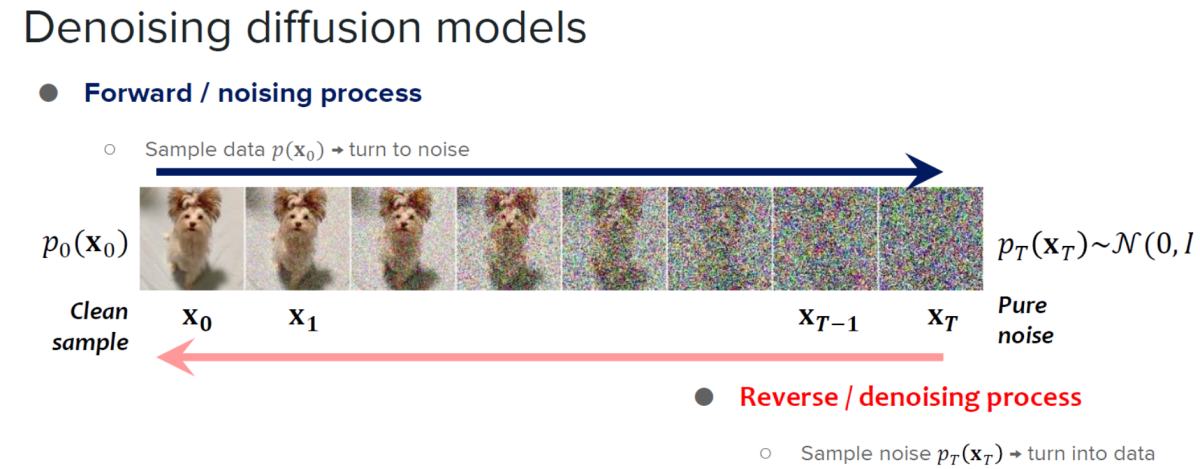
Los modelos de difusión son conocidos por sus excepcionales capacidades de generación de imágenes y la cantidad de control que ofrecen. Debido a sus capacidades, los modelos de difusión han encontrado sus aplicaciones en la edición de imágenes, la generación de texto a imagen y la generación de videos. Además, el desarrollo de modelos consistentes ha demostrado el potencial de mejorar la eficiencia del procesamiento de muestras sin comprometer la calidad de las imágenes generadas por el modelo, lo que ha abierto nuevas puertas para expandir la aplicabilidad y eficiencia de los modelos de difusión al reducir el número de pasos de muestreo. Aunque son extremadamente capaces, los modelos de difusión tienden a tener una limitación importante: la generación lenta de imágenes. Para abordar esta limitación, los desarrolladores introdujeron modelos de difusión acelerada, marcos basados en difusión que no requieren pasos de entrenamiento adicionales ni implementan estrategias de predictor-corrector y solucionadores de tamaño de paso adaptativos para aumentar las velocidades de salida.
El factor distintivo entre StreamDiffusion y los marcos tradicionales basados en difusión es que mientras el último se centra principalmente en la baja latencia de modelos individuales, el primero introduce un enfoque a nivel de canalización diseñado para lograr altos rendimientos que permitan una difusión interactiva eficiente.
StreamDiffusion: Trabajo y Arquitectura
El canal StreamDiffusion es un canal de difusión en tiempo real desarrollado para generar imágenes interactivas y realistas, y emplea 6 componentes clave, a saber: RCFG o guía libre del clasificador residual, estrategia Stream Batch, filtro de similitud estocástica, una cola de entrada-salida y herramientas de aceleración de modelos. con codificador automático y un procedimiento de precálculo. Hablemos de estos componentes en detalle.
Estrategia de transmisión por lotes
Tradicionalmente, los pasos de eliminación de ruido en un modelo de difusión se realizan de forma secuencial, lo que resulta en un aumento significativo en el tiempo de procesamiento de U-Net hasta el número de pasos de procesamiento. Sin embargo, es esencial aumentar la cantidad de pasos de procesamiento para generar imágenes de alta fidelidad, y el marco StreamDiffusion introduce la estrategia Stream Batch para superar la resolución de alta latencia en marcos de difusión interactivos.
En la estrategia Stream Batch, las operaciones secuenciales de eliminación de ruido se reestructuran en procesos por lotes y cada lote corresponde a un número predeterminado de pasos de eliminación de ruido, y el número de estos pasos de eliminación de ruido está determinado por el tamaño de cada lote. Gracias a este enfoque, cada elemento del lote puede avanzar un paso más utilizando el paso único UNet en la secuencia de eliminación de ruido. Al implementar la estrategia de flujo por lotes de forma iterativa, las imágenes de entrada codificadas en el paso de tiempo "t" se pueden transformar en sus respectivos resultados de imagen a imagen en el paso de tiempo "t+n", agilizando así el proceso de eliminación de ruido.
Orientación gratuita sobre clasificadores residuales
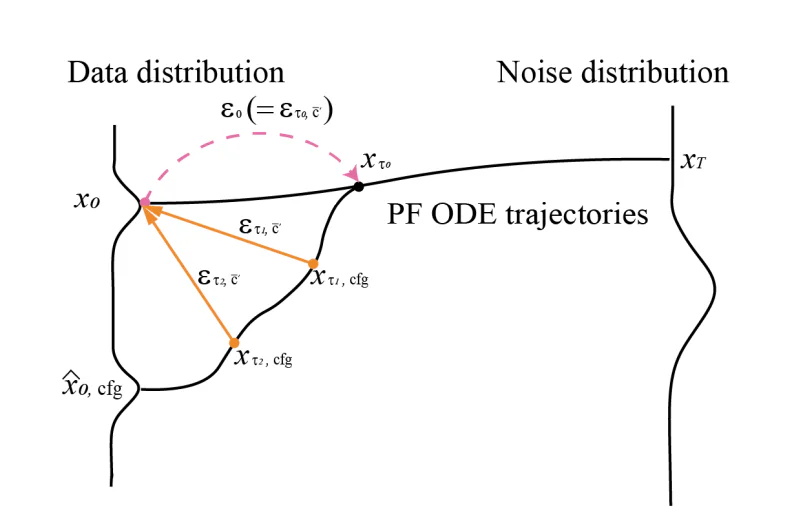
CFG o Classifier Free Guidance es un algoritmo de IA que realiza una serie de cálculos vectoriales entre el término de condicionamiento original y un término de condicionamiento negativo o incondicionamiento para mejorar el efecto del condicionamiento original. El algoritmo fortalece el efecto del mensaje aunque para calcular el ruido residual de acondicionamiento negativo, es necesario emparejar variables latentes de entrada individuales con una incrustación de acondicionamiento negativo y luego pasar las incrustaciones a través de UNet en el tiempo de referencia.
Para abordar este problema planteado por el algoritmo de orientación libre del clasificador, el marco StreamDiffusion introduce el algoritmo de orientación libre del clasificador residual con el objetivo de reducir los costos computacionales de la interferencia UNet adicional para la incrustación de condicionamiento negativo. En primer lugar, la entrada latente codificada se transfiere a la distribución de ruido utilizando valores determinados por el programador de ruido. Una vez que se ha implementado el modelo de consistencia latente, el algoritmo puede predecir la distribución de datos y utilizar el ruido residual CFG para generar la distribución de ruido del siguiente paso.
Cola de entrada y salida
El principal problema con los marcos de generación de imágenes de alta velocidad son sus módulos de red neuronal, incluidos los componentes UNet y VAE. Para maximizar la eficiencia y la velocidad de salida general, los marcos de generación de imágenes mueven procesos como el procesamiento previo y posterior de imágenes que no requieren un manejo adicional por parte de los módulos de red neuronal fuera de la tubería, después de lo cual se procesan en paralelo. Además, en términos de manejo de la imagen de entrada, la canalización ejecuta meticulosamente operaciones específicas que incluyen la conversión del formato tensorial, el cambio de tamaño de las imágenes de entrada y la normalización.
Para abordar la disparidad en las frecuencias de procesamiento entre el rendimiento del modelo y la entrada humana, la tubería integra un sistema de colas de entrada y salida que permite una paralelización eficiente, como se demuestra en la siguiente imagen.
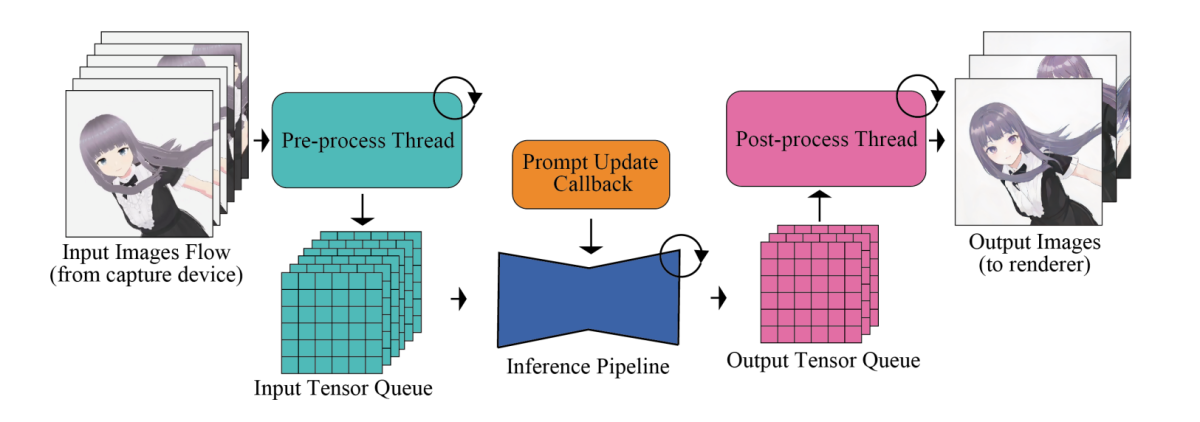
Los tensores de entrada procesados primero se ponen en cola metódicamente para los modelos de difusión y, durante cada cuadro, el modelo recupera el tensor más reciente de la cola de entrada y reenvía el tensor al codificador VAE, iniciando así el proceso de generación de imágenes. Al mismo tiempo, la salida del tensor del decodificador VAE se introduce en la cola de salida. Finalmente, los datos de la imagen procesada se transmiten al cliente de renderizado.
Filtro de similitud estocástica
En escenarios donde las imágenes permanecen sin cambios o muestran cambios mínimos sin un entorno estático o sin interacción activa del usuario, las imágenes de entrada que se parecen entre sí se introducen repetidamente en los componentes UNet y VAE. La alimentación repetida genera imágenes casi idénticas y un consumo adicional de recursos de GPU. Además, en escenarios que involucran entradas continuas, ocasionalmente pueden aparecer imágenes de entrada sin modificar. Para superar este problema y evitar la utilización innecesaria de recursos, la canalización StreamDiffusion emplea un componente de filtro de similitud estocástica en su canalización. El filtro de similitud estocástica primero calcula la similitud del coseno entre la imagen de referencia y la imagen de entrada, y utiliza la puntuación de similitud del coseno para calcular la probabilidad de omitir los procesos UNet y VAE posteriores.
Sobre la base de la puntuación de probabilidad, la canalización decide si los procesos posteriores como VAE Encoding, VAE Decoding y U-Net deben omitirse o no. Si no se omiten estos procesos, la canalización guarda la imagen de entrada en ese momento y simultáneamente actualiza la imagen de referencia que se utilizará en el futuro. Este mecanismo de omisión basado en la probabilidad permite que el canal StreamDiffusion funcione completamente en escenarios dinámicos con baja similitud entre cuadros, mientras que en escenarios estáticos, el canal opera con una mayor similitud entre cuadros. El enfoque ayuda a conservar los recursos computacionales y también garantiza una utilización óptima de la GPU en función de la similitud de las imágenes de entrada.
Pre-cálculo
La arquitectura UNet necesita tanto incorporaciones condicionantes como variables latentes de entrada. Tradicionalmente, las incrustaciones condicionantes se derivan de incrustaciones rápidas que permanecen constantes en todos los fotogramas. Para optimizar la derivación de incrustaciones de mensajes, la canalización StreamDiffusion calculó previamente estas incrustaciones de mensajes y las almacena en un caché, que luego se llama en modo de transmisión o interactivo. Dentro del marco UNet, el par clave-valor se calcula sobre la base de la incrustación de mensajes precalculada de cada marco y, con ligeras modificaciones en U-Net, estos pares clave-valor se pueden reutilizar.
Aceleración de modelos y Tiny AutoEncoder
El canal StreamDiffusion emplea TensorRT, un conjunto de herramientas de optimización de Nvidia para interfaces de aprendizaje profundo, para construir los motores VAE y UNet y acelerar la velocidad de inferencia. Para lograr esto, el componente TensorRT realiza numerosas optimizaciones en redes neuronales que están diseñadas para aumentar la eficiencia y mejorar el rendimiento de los marcos y aplicaciones de aprendizaje profundo.
Para optimizar la velocidad, StreamDiffusion configura el marco para utilizar dimensiones de entrada fijas y tamaños de lotes estáticos para garantizar una asignación de memoria óptima y gráficos computacionales para un tamaño de entrada específico en un intento de lograr tiempos de procesamiento más rápidos.
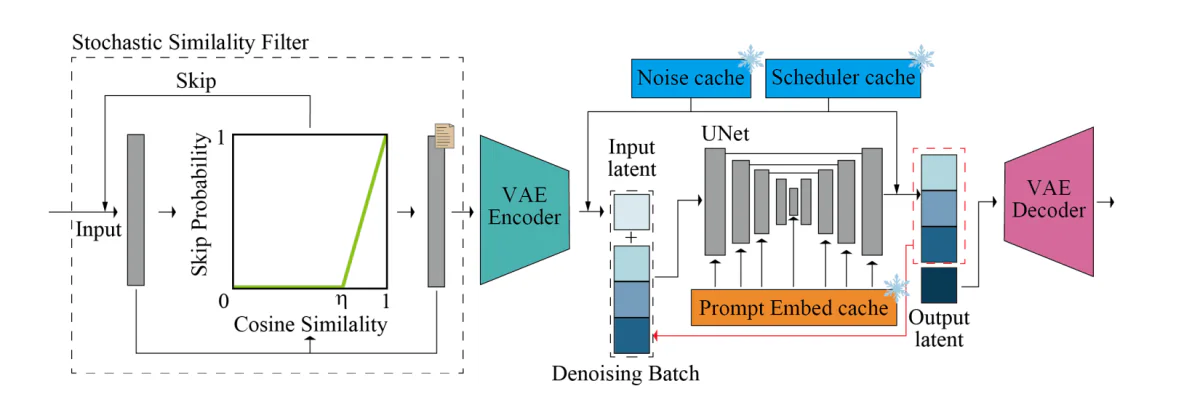
La figura anterior proporciona una descripción general del proceso de inferencia. La tubería de difusión central alberga los componentes UNet y VAE. La canalización incorpora un lote de eliminación de ruido, caché de ruido muestreado, caché de incrustación de avisos precalculados y caché de valores del programador para mejorar la velocidad y la capacidad de la canalización para generar imágenes en tiempo real. El filtro de similitud estocástica o SSF se implementa para optimizar el uso de la GPU y también para controlar dinámicamente el paso del modelo de difusión.
StreamDiffusion: experimentos y resultados
Para evaluar sus capacidades, el canal StreamDiffusion se implementa en marcos LCM y SD-turbo. TensorRT de NVIDIA se utiliza como acelerador de modelo y, para permitir un VAE de eficiencia liviana, la canalización emplea el componente TAESD. Ahora echemos un vistazo a cómo se desempeña la canalización StreamDiffusion en comparación con los marcos de trabajo más modernos actuales.
Evaluación cuantitativa
La siguiente figura demuestra la comparación de eficiencia entre el UNet secuencial original y los componentes por lotes de eliminación de ruido en la tubería y, como puede verse, la implementación del enfoque por lotes de eliminación de ruido ayuda a reducir significativamente el tiempo de procesamiento en casi un 50 % en comparación con el UNet tradicional. bucles en pasos secuenciales de eliminación de ruido.
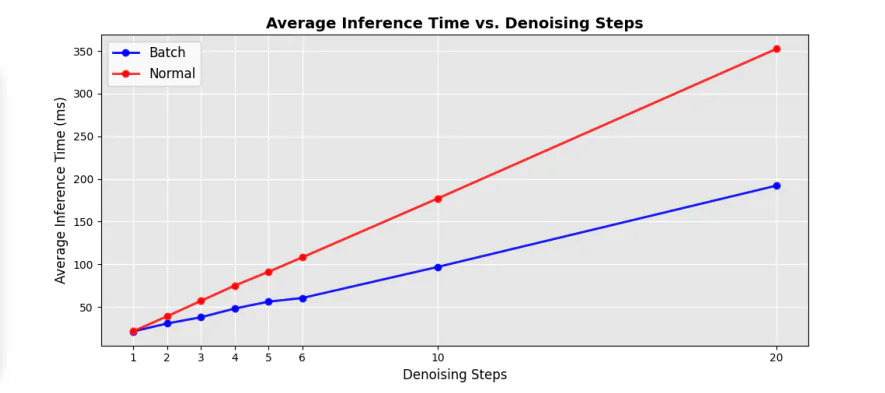
Además, el tiempo de inferencia promedio en diferentes pasos de eliminación de ruido también experimenta un aumento sustancial con diferentes factores de aceleración en comparación con las tuberías de última generación actuales, y los resultados se demuestran en la siguiente imagen.

En el futuro, la canalización StreamDiffusion con el componente RCFG demuestra menos tiempo de inferencia en comparación con las canalizaciones que incluyen el componente CFG tradicional.
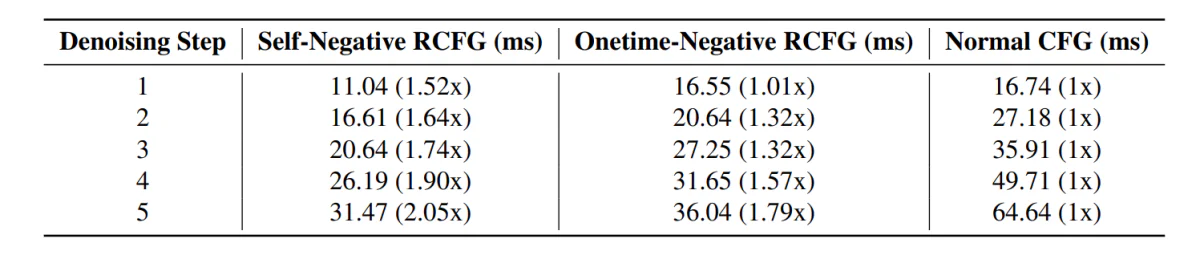
Además, el impacto del uso del componente RCFG es evidente en las siguientes imágenes en comparación con el uso del componente CFG.

Como puede verse, el uso de CFG intensifica el impacto del mensaje textual en la generación de imágenes, y la imagen se parece mucho más a los mensajes de entrada en comparación con las imágenes generadas por el pipeline sin usar el componente CFG. Los resultados mejoran aún más con el uso del componente RCFG ya que la influencia de las indicaciones en las imágenes generadas es bastante significativa en comparación con el componente CFG original.
Consideraciones Finales:
En este artículo, hablamos sobre StreamDiffusion, un canal de difusión en tiempo real desarrollado para generar imágenes interactivas y realistas, y abordamos las limitaciones actuales que plantean los marcos basados en difusión en tareas que implican entrada continua. StreamDiffusion es un enfoque simple y novedoso que tiene como objetivo transformar el ruido secuencial de la imagen original en eliminación de ruido por lotes. StreamDiffusion tiene como objetivo permitir flujos fluidos y de alto rendimiento eliminando el enfoque tradicional de espera e interacción optado por los marcos actuales basados en difusión. Las posibles ganancias de eficiencia resaltan el potencial del canal StreamDiffusion para aplicaciones comerciales que ofrecen computación de alto rendimiento y soluciones atractivas para IA generativa.













