
Inteligencia artificial
Resolviendo el problema del artefacto JPEG en conjuntos de datos de visión por computadora
Un nuevo estudio de la Universidad de Maryland y Facebook AI encontró una "penalización de rendimiento significativa" para los sistemas de aprendizaje profundo que usan imágenes JPEG altamente comprimidas en sus conjuntos de datos, y ofrece algunos métodos nuevos para mitigar los efectos de esto.
El reporte, Titulado Análisis y mitigación de defectos de compresión JPEG en aprendizaje profundo, afirma ser "significativamente más completo" que estudios anteriores sobre los efectos de los artefactos en el entrenamiento de conjuntos de datos de visión por computadora. El artículo concluye que "la compresión JPEG [pesada] a moderada conlleva una importante penalización en el rendimiento de las métricas estándar", y que las redes neuronales tal vez no sean tan resistentes a tales perturbaciones como trabajos anteriores. sugieren.

Una foto de un perro del conjunto de datos MobileNetV2018 de 2. En la calidad 10 (izquierda), un sistema de clasificación no identifica la raza correcta 'Pembroke Welsh Corgi', sino que adivina 'Norwich terrier' (el sistema ya sabe que se trata de una foto de un perro, pero no de la raza); segundo desde la izquierda, una versión de la imagen corregida por artefactos JPEG lista para usar no logra identificar la raza correcta; segundo desde la derecha, la corrección de artefactos específicos restaura la clasificación correcta; ya la derecha, la foto original, correctamente clasificada. Fuente: https://arxiv.org/pdf/2011.08932.pdf
Artefactos de compresión como 'datos'
Es probable que la compresión JPEG extrema cree bordes visibles o semivisibles alrededor del 8 × 8 bloques a partir del cual se ensambla un JPEG en una cuadrícula de píxeles. Una vez que aparecen estos artefactos de bloqueo o "timbre", es probable que los sistemas de aprendizaje automático los malinterpreten como elementos del mundo real del sujeto de la imagen, a menos que se haga alguna compensación por esto.

Arriba, un sistema de aprendizaje automático de visión por computadora extrae una imagen de gradiente 'limpia' de una imagen de buena calidad. A continuación, los artefactos de 'bloqueo' en un guardado de menor calidad de la imagen oscurecen las características del sujeto y pueden terminar 'infectando' las características derivadas de un conjunto de imágenes, particularmente en los casos en que se producen imágenes de alta y baja calidad en el conjunto de datos. , como en las recopilaciones extraídas de la web a las que solo se ha aplicado una limpieza de datos genérica. Fuente: http://www.cs.utep.edu/ofuentes/papers/quijasfuentes2014.pdf
Como se ve en la primera imagen de arriba, tales artefactos pueden afectar las tareas de clasificación de imágenes, con implicaciones también para los algoritmos de reconocimiento de texto, que pueden no identificar correctamente los caracteres afectados por artefactos.
En el caso de los sistemas de entrenamiento de síntesis de imágenes (como el software deepfake o los sistemas de generación de imágenes basados en GAN), un bloque 'falso' de imágenes de baja calidad y altamente comprimidas en un conjunto de datos puede reducir la calidad media de la reproducción, o bien ser subsumido y esencialmente anulado por un mayor número de características de mayor calidad extraídas de mejores imágenes en el conjunto. En cualquier caso, es deseable disponer de mejores datos o, al menos, datos consistentes.
JPEG: generalmente 'suficientemente bueno'
La compresión JPEG es un códec con pérdida irreversible que se puede aplicar a varios formatos de imagen, aunque se aplica principalmente al archivo de imagen JFIF. envoltura. A pesar de esto, el formato JPEG (.jpg) recibió el nombre de su método de compresión asociado, y no del envoltorio JFIF para los datos de imagen.
En los últimos años han surgido arquitecturas completas de aprendizaje automático que incluyen la mitigación de artefactos de estilo JPEG como parte de las rutinas de mejora/restauración impulsadas por IA, y la eliminación de artefactos de compresión basada en IA ahora se incorpora en una serie de productos comerciales, como Topaz image/ video suite, y la caracteristicas neurales de versiones recientes de Adobe Photoshop.
Puesto que el 1986 El esquema JPEG actualmente en uso común estaba prácticamente bloqueado a principios de la década de 1990, no es posible agregar metadatos a una imagen que indicarían en qué nivel de calidad (1-100) se guardó una imagen JPEG, al menos, no sin modificar treinta años de sistemas de software heredados para consumidores, profesionales y académicos que no esperaban que tales metadatos estuvieran disponibles.
En consecuencia, no es raro adaptar las rutinas de entrenamiento de aprendizaje automático a la calidad evaluada o conocida de los datos de imagen JPEG, como lo han hecho los investigadores para el nuevo artículo (ver más abajo). En ausencia de una entrada de metadatos de 'calidad', actualmente es necesario conocer los detalles de cómo se comprimió la imagen (es decir, comprimida desde una fuente sin pérdidas) o estimar la calidad a través de algoritmos de percepción o clasificación manual.
Un compromiso económico
JPEG no es el único método de compresión con pérdida que puede afectar la calidad de los conjuntos de datos de aprendizaje automático; la configuración de compresión en archivos PDF también puede descartar información de esta manera y establecerse en niveles de calidad muy bajos para ahorrar espacio en disco para fines de archivo local o de red.
Esto se puede observar probando varios archivos PDF en archive.org, algunos de los cuales se han comprimido tanto que son un desafío notable para los sistemas de reconocimiento de imágenes o texto. En muchos casos, como en el caso de los libros con derechos de autor, esta intensa compresión parece haberse aplicado como una forma de DRM barato, de la misma manera que los titulares de los derechos de autor pueden optar por reducir la resolución de los videos de YouTube subidos por los usuarios en los que poseen la propiedad intelectual. dejar los videos 'bloqueados' como tokens promocionales para inspirar compras de 'resolución completa', en lugar de eliminarlos.
En muchos otros casos, la resolución o la calidad de la imagen es baja simplemente porque los datos son muy antiguos y provienen de una era en la que el almacenamiento local y en red era más caro, y cuando las velocidades de red limitadas favorecían las imágenes portátiles y altamente optimizadas sobre la reproducción de alta calidad. .
Se ha argumentado que JPEG, aunque no es la mejor solución ahora, ha sido 'consagrado' como infraestructura heredada inamovible que está esencialmente entrelazada con los cimientos de Internet.
Carga del legado
Aunque las innovaciones posteriores como JPEG 2000, PNG y (más recientemente) el formato .webp ofrecen una calidad superior, volver a muestrear conjuntos de datos de aprendizaje automático más antiguos y muy populares posiblemente "restablecería" la continuidad y la historia de los desafíos de visión artificial año tras año. en la comunidad académica, un impedimento que se aplicaría también en el caso de volver a guardar imágenes de conjuntos de datos PNG en configuraciones de mayor calidad. Esto podría considerarse como una especie de deuda técnica.
Si bien las venerables bibliotecas de procesamiento de imágenes impulsadas por servidores, como ImageMagick, admiten mejores formatos, incluido .webp, los requisitos de transformación de imágenes ocurren con frecuencia en sistemas heredados que no están configurados para otra cosa que no sea JPG o PNG (que ofrece compresión sin pérdida, pero a expensas de latencia y espacio en disco). Incluso WordPress, el CMS que impulsa casi el 40% de todos los sitios web, solo se agregó compatibilidad con .webp hace tres meses.
PNG fue una entrada tardía (posiblemente demasiado tarde) en el sector del formato de imagen, que surgió como una solución de código abierto a finales de la década de 1990 en respuesta a una declaración de 1995 por Unisys y CompuServe que en lo sucesivo se pagarían regalías sobre el formato de compresión LZW utilizado en los archivos GIF, que en ese entonces se usaban comúnmente para logotipos y elementos de color plano, incluso si el formato Resurrección a principios de la década de 2010 se centró en su capacidad para proporcionar contenido animado ágil y de bajo ancho de banda (irónicamente, los PNG animados nunca ganaron popularidad o apoyo amplio, e incluso fueron prohibido de Twitter en 2019).
A pesar de sus deficiencias, la compresión JPEG es rápida, ocupa poco espacio y está profundamente integrada en sistemas de todo tipo y, por lo tanto, no es probable que desaparezca por completo de la escena del aprendizaje automático en un futuro próximo.
Sacar lo mejor de la distensión AI/JPEG
Hasta cierto punto, la comunidad de aprendizaje automático se ha acomodado a las debilidades de la compresión JPEG: en 2011, la Sociedad Europea de Radiología (ESR) publicó un estudio sobre la 'Usabilidad de la compresión de imágenes irreversibles en imágenes radiológicas', proporcionando pautas para la pérdida 'aceptable'; cuando el venerable MNIST El conjunto de datos de reconocimiento de texto (cuyos datos de imagen se proporcionaron originalmente en un formato binario novedoso) se transfirió a un formato de imagen "normal", JPEG, no PNG, fue elegido; y una colaboración anterior (2020) de los autores del nuevo artículo ofrecida 'una arquitectura novedosa' para calibrar los sistemas de aprendizaje automático para las deficiencias de la calidad variable de la imagen JPEG, sin necesidad de que los modelos se entrenen en cada configuración de calidad JPEG, una característica utilizada en el nuevo trabajo.
De hecho, la investigación sobre la utilidad de los datos JPEG con variantes de calidad es un campo relativamente próspero en el aprendizaje automático. Un proyecto (no relacionado) de 2016 del Centro de Investigación de Automatización de la Universidad de Maryland, en realidad se centra en el dominio DCT (donde los artefactos JPEG ocurren en configuraciones de baja calidad) como una ruta para la extracción de características profundas; otro proyecto de 2019 se concentra en lectura a nivel de byte de datos JPEG sin la necesidad de descomprimir realmente las imágenes (es decir, abrirlas en algún punto en un flujo de trabajo automatizado); y un estudio de Francia en 2019 aprovecha activamente la compresión JPEG al servicio de las rutinas de reconocimiento de objetos.
Pruebas y Conclusiones
Volviendo al último estudio de la UoM y Facebook, los investigadores intentaron probar la comprensibilidad y la utilidad de JPEG en imágenes comprimidas entre 10 y 90 (por debajo del cual, la imagen se ve increíblemente perturbada y por encima del cual es igual a la compresión sin pérdidas). Las imágenes utilizadas en las pruebas se comprimieron previamente en cada valor dentro del rango de calidad objetivo, lo que implica al menos ocho sesiones de entrenamiento.
Los modelos se entrenaron en descenso de gradiente estocástico mediante cuatro métodos: base, donde no se agregaron mitigaciones adicionales; puesta a punto supervisada, donde el conjunto de entrenamiento tiene la ventaja de pesos previamente entrenados y datos etiquetados (aunque los investigadores admiten que esto es difícil de replicar en aplicaciones a nivel de consumidor); corrección de artefactos, donde el aumento/mejora se realiza en las imágenes comprimidas antes del entrenamiento; y corrección de artefactos dirigida a tareas, donde la red de corrección de artefactos se ajusta con precisión en los errores devueltos.
La capacitación se realizó en una amplia variedad de conjuntos de datos aptos, incluidas múltiples variantes de ResNet, RápidoRCNN, MóvilNetV2, MáscaraRCNN y Keras' OrigenV3.
Los resultados de pérdida de muestras después de la corrección de artefactos dirigida a la tarea se visualizan a continuación (menor = mejor).
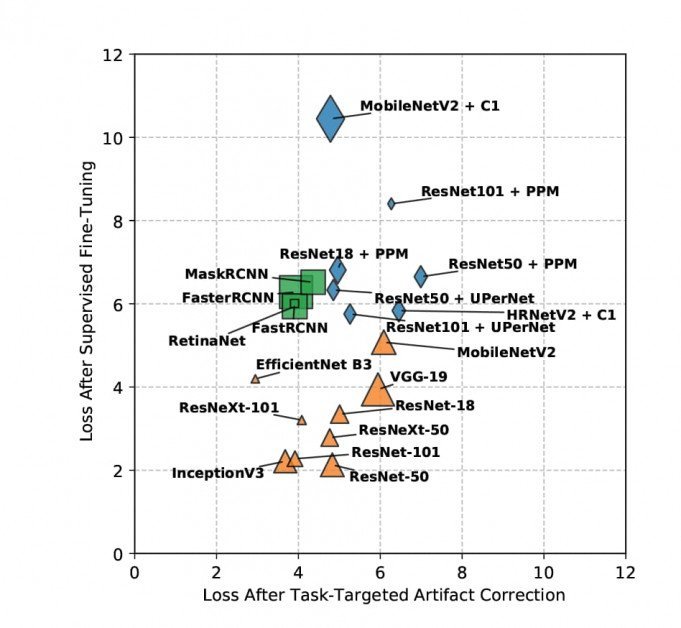
No es posible profundizar en los detalles de los resultados obtenidos en el estudio, porque los hallazgos de los investigadores se dividen entre el objetivo de evaluar los artefactos JPEG y los nuevos métodos para paliar esto; el entrenamiento fue iterado por calidad sobre tantos conjuntos de datos; y las tareas incluían múltiples objetivos, como la detección, segmentación y clasificación de objetos. Esencialmente, el nuevo informe se posiciona como una obra de referencia integral que aborda múltiples temas.
No obstante, el documento concluye en términos generales que "la compresión JPEG tiene una fuerte penalización en todos los ámbitos para configuraciones de compresión pesadas a moderadas". También afirma que sus novedosas estrategias de mitigación no etiquetadas logran resultados superiores entre otros enfoques similares; que, para tareas complejas, el método supervisado de los investigadores también supera a sus pares, a pesar de no tener acceso a las etiquetas de verdad del terreno; y que estas metodologías novedosas permiten la reutilización de modelos, ya que los pesos obtenidos son transferibles entre tareas.
En cuanto a las tareas de clasificación, el documento establece explícitamente que 'JPEG degrada la calidad del gradiente e induce errores de localización'.
Los autores esperan ampliar los estudios futuros para cubrir otros métodos de compresión como el ampliamente ignorado JPEG 2000, así como WebP, HEIF y BPG. Sugieren además que su metodología podría aplicarse a investigaciones análogas sobre algoritmos de compresión de video.
Dado que el método de corrección de artefactos dirigido a la tarea ha demostrado ser tan exitoso en el estudio, los autores también señalan su intención de liberar los pesos entrenados durante el proyecto, anticipando que "[muchas] aplicaciones se beneficiarán del uso de nuestros pesos TTAC sin modificación".
Nota: la imagen de origen del artículo proviene de thispersondoesnotexist.com













