Inteligencia artificial
GPT-4o de OpenAI: el modelo de IA multimodal que transforma la interacción hombre-máquina

OpenAI ha lanzado su modelo de lenguaje más reciente y avanzado hasta el momento: GPT-4o, también conocido como elOmni" modelo. Este revolucionario sistema de IA representa un gran paso adelante, con capacidades que desdibujan la línea entre la inteligencia humana y la artificial.
En el corazón de GPT-4o se encuentra su naturaleza multimodal nativa, que le permite procesar y generar contenido sin problemas en texto, audio, imágenes y video. Esta integración de múltiples modalidades en un solo modelo es la primera de su tipo y promete remodelar la forma en que interactuamos con los asistentes de IA.
Pero GPT-4o es mucho más que un simple sistema multimodal. Cuenta con una asombrosa mejora de rendimiento con respecto a su predecesor, GPT-4, y deja atrás a modelos de la competencia como Gemini 1.5 Pro, Claude 3 y Llama 3-70B. Profundicemos en lo que hace que este modelo de IA sea realmente innovador.
Rendimiento y eficiencia incomparables
Uno de los aspectos más impresionantes de GPT-4o es su capacidad de rendimiento sin precedentes. Según las evaluaciones de OpenAI, el modelo tiene una notable ventaja de 60 puntos Elo sobre el modelo anterior, el GPT-4 Turbo. Esta importante ventaja coloca a GPT-4o en una liga propia, eclipsando incluso a los modelos de IA más avanzados disponibles actualmente.
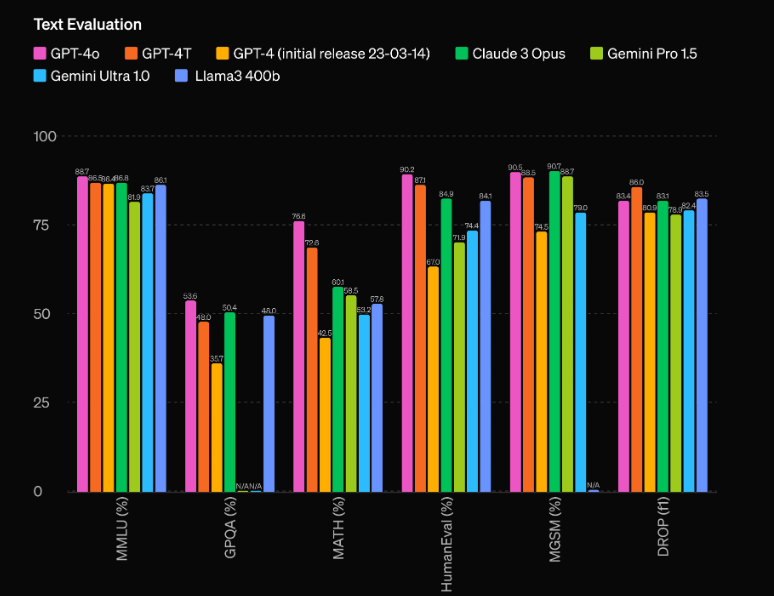
Pero el rendimiento bruto no es la única área donde brilla GPT-4o. El modelo también cuenta con una eficiencia impresionante, ya que funciona al doble de velocidad que el GPT-4 Turbo y su funcionamiento cuesta sólo la mitad. Esta combinación de rendimiento superior y rentabilidad hace de GPT-4o una propuesta extremadamente atractiva para desarrolladores y empresas que buscan integrar capacidades de IA de vanguardia en sus aplicaciones.
Capacidades multimodales: combinación de texto, audio y visión
Quizás el aspecto más innovador de GPT-4o es su naturaleza multimodal nativa, que le permite procesar y generar contenido sin problemas en múltiples modalidades, incluidos texto, audio y visión. Esta integración de múltiples modalidades en un solo modelo es la primera de su tipo y promete revolucionar la forma en que interactuamos con los asistentes de IA.
Con GPT-4o, los usuarios pueden entablar conversaciones naturales y en tiempo real mediante la voz, y el modelo reconoce y responde instantáneamente a las entradas de audio. Pero las capacidades no terminan ahí: GPT-4o también puede interpretar y generar contenido visual, abriendo un mundo de posibilidades para aplicaciones que van desde el análisis y la generación de imágenes hasta la comprensión y creación de videos.
Una de las demostraciones más impresionantes de las capacidades multimodales de GPT-4o es su capacidad para analizar una escena o imagen en tiempo real, describiendo e interpretando con precisión los elementos visuales que percibe. Esta característica tiene profundas implicaciones para aplicaciones como las tecnologías de asistencia para personas con discapacidad visual, así como en campos como la seguridad, la vigilancia y la automatización.
Pero las capacidades multimodales de GPT-4o se extienden más allá de la simple comprensión y generación de contenido en diferentes modalidades. El modelo también puede combinar a la perfección estas modalidades, creando experiencias verdaderamente inmersivas y atractivas. Por ejemplo, durante la demostración en vivo de OpenAI, GPT-4o pudo generar una canción basada en las condiciones de entrada, combinando su comprensión del lenguaje, la teoría musical y la generación de audio en un resultado cohesivo e impresionante.
Usando GPT0 usando Python
import openai
# Replace with your actual API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Function to extract the response content
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous function to send a request to the OpenAI chat API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Example usage
async def main():
prompt = "Hello!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Yo tengo:
- Importé el módulo openai directamente en lugar de usar una clase personalizada.
- Se cambió el nombre de la función openai_chat_resolve a get_response_content y se realizaron algunos cambios menores en su implementación.
- Se reemplazó la clase AsyncOpenAI con la función openai.ChatCompletion.acreate, que es el método asincrónico oficial proporcionado por la biblioteca OpenAI Python.
- Se agregó una función principal de ejemplo que demuestra cómo usar la función send_openai_chat_request.
Tenga en cuenta que debe reemplazar "your_openai_api_key_here" con su clave API de OpenAI real para que el código funcione correctamente.


















