El ángulo de Anderson
HunyuanCustom presenta videos deepfakes de una sola imagen, con audio y sincronización de labios.

Este artículo analiza una nueva versión de un modelo multimodal del mundo de Hunyuan Video llamado "HunyuanCustom". La amplitud de la cobertura del nuevo documento, junto con varios problemas en muchos de los videos de ejemplo proporcionados en el... página del proyecto*, nos limita a una cobertura más general de lo habitual y a una reproducción limitada de la enorme cantidad de material de video que acompaña a este lanzamiento (ya que muchos de los videos requieren una reedición y procesamiento significativos para mejorar la legibilidad del diseño).
Tenga en cuenta además que el artículo se refiere al sistema generativo basado en API Kling como «Keling». Para mayor claridad, me referiré a «Kling» en su lugar.
Tencent está en proceso de lanzar una nueva versión de su Modelo de vídeo de Hunyuan, Titulado HunyuanPersonalizado. El nuevo lanzamiento aparentemente es capaz de hacer Modelos Hunyuan LoRA redundante, al permitir al usuario crear una personalización de video estilo 'deepfake' a través de un soltero imagen:
Dele "click" para jugar. Indicación: «Un hombre escucha música y cocina fideos de caracol en la cocina». El nuevo método se compara con métodos de código cerrado y abierto, incluyendo Kling, un competidor importante en este ámbito. Fuente: https://hunyuancustom.github.io/ (advertencia: sitio que consume mucho CPU y memoria)
En la columna más a la izquierda del video anterior, vemos la imagen de origen única proporcionada a HunyuanCustom, seguida de la interpretación del mensaje por parte del nuevo sistema en la segunda columna, junto a ella. Las columnas restantes muestran los resultados de varios sistemas propietarios y de código abierto: Kling; Vidu; Pika; Hailuo; y el Wan-Basado SkyReels-A2.
En el vídeo a continuación, vemos renders de tres escenarios esenciales para este lanzamiento: respectivamente, persona + objeto; emulación de un solo carácter; y prueba virtual (persona + ropa):
Haga clic para jugarTres ejemplos editados del material del sitio de apoyo a Hunyuan Video.
Podemos notar algunas cosas en estos ejemplos, principalmente relacionadas con el sistema que se basa en un imagen de fuente única, en lugar de múltiples imágenes del mismo tema.
En el primer clip, el hombre prácticamente sigue mirando a la cámara. Inclina la cabeza hacia abajo y hacia los lados con una rotación de apenas 20-25 grados, pero, con una inclinación superior, el sistema tendría que empezar a calcular su aspecto de perfil. Es difícil, probablemente imposible, calcularlo con precisión a partir de una sola imagen frontal.
En el segundo ejemplo, vemos que la niña es sonriente En el vídeo renderizado, aparece igual que en la imagen estática original. De nuevo, con esta única imagen como referencia, HunyuanCustom tendría que hacer una suposición bastante desinformada sobre cómo se ve su "rostro en reposo". Además, su rostro no se desvía de la postura de cara a la cámara más que en el ejemplo anterior ("hombre comiendo patatas fritas").
En el último ejemplo, vemos que como el material original (la mujer y la ropa que se le pide que use) no son imágenes completas, la renderización ha recortado el escenario para que se ajuste, lo que en realidad es una buena solución a un problema de datos.
La cuestión es que, aunque el nuevo sistema puede gestionar varias imágenes (como persona + patatas fritaso persona + ropa), aparentemente no permite múltiples ángulos o vistas alternativas. de un solo personaje, de modo que se pudieran acomodar diversas expresiones o ángulos inusuales. En este sentido, el sistema podría tener dificultades para reemplazar el creciente ecosistema de modelos LoRA que tienen surgido alrededor de HunyuanVideo desde su lanzamiento en diciembre pasado, ya que estos pueden ayudar a HunyuanVideo a producir personajes consistentes desde cualquier ángulo y con cualquier expresión facial representada en el conjunto de datos de entrenamiento (20 a 60 imágenes es lo típico).
Cableado para sonido
Para el audio, HunyuanCustom aprovecha la Sincronización latente sistema (notoriamente difícil de configurar y de obtener buenos resultados para los aficionados) para obtener movimientos de labios que coincidan con el audio y el texto que proporciona el usuario:
Incluye audio. Haz clic para reproducir. Varios ejemplos de sincronización de labios del sitio complementario HunyuanCustom, editados juntos.
Al momento de escribir esto, no hay ejemplos en inglés, pero parecen ser bastante buenos, más aún si el método para crearlos es fácilmente instalable y accesible.
Edición de vídeo existente
El nuevo sistema ofrece resultados impresionantes para la edición de vídeo a vídeo (V2V o Vid2Vid), donde un segmento de un vídeo real existente se enmascara y se reemplaza inteligentemente por un sujeto presente en una única imagen de referencia. A continuación, se muestra un ejemplo del sitio de materiales complementarios:
Dele "click" para jugar. Solo se selecciona el objeto central, pero lo que queda a su alrededor también se modifica en un pase vid2vid de HunyuanCustom.
Como podemos ver, y como es estándar en un escenario vid2vid, el video completo se altera hasta cierto punto por el proceso, aunque la mayor parte se altera en la región objetivo, es decir, el peluche. Presumiblemente, se podrían desarrollar canales para crear tales transformaciones bajo un tapete de basura Un enfoque que mantiene la mayor parte del contenido de video idéntico al original. Esto es lo que Adobe Firefly hace internamente, y lo hace bastante bien, pero es un proceso poco estudiado en el mundo generativo de software libre y de código abierto.
Dicho esto, la mayoría de los ejemplos alternativos proporcionados hacen un mejor trabajo al apuntar a estas integraciones, como podemos ver en la compilación a continuación:
Dele "click" para jugar. Diversos ejemplos de contenido intercalado utilizando vid2vid en HunyuanCustom, que muestran un notable respeto por el material no dirigido.
¿Un nuevo comienzo?
Esta iniciativa es un desarrollo de la Proyecto de vídeo Hunyuan, no un cambio radical en esa línea de desarrollo. Las mejoras del proyecto se introducen como inserciones arquitectónicas discretas en lugar de cambios estructurales radicales, con el objetivo de permitir que el modelo mantenga la fidelidad de identidad entre los marcos sin depender de... específico del tema sintonia FINA, como ocurre con LoRA o los enfoques de inversión textual.
Para ser claros, por lo tanto, HunyuanCustom no se entrena desde cero, sino que es un ajuste del modelo base de HunyuanVideo de diciembre de 2024.
Quienes han desarrollado LoRAs de HunyuanVideo pueden preguntarse si seguirán funcionando con esta nueva edición o si tendrán que reinventar la rueda LoRA. una vez más si desean más capacidades de personalización que las integradas en esta nueva versión.
En general, una versión muy ajustada de un modelo de hiperescala altera la pesos del modelo Es suficiente que los LoRA creados para el modelo anterior no funcionen correctamente, o en absoluto, con el modelo recientemente refinado.
A veces, sin embargo, la popularidad de una melodía puede desafiar sus orígenes: un ejemplo de una melodía que se convierte en una melodía eficaz es tenedor, con un ecosistema dedicado y seguidores propios, es el Difusión de ponis afinación de Difusión estable XL (SDXL). Pony actualmente tiene más de 592,000 descargas en siempre cambiante Dominio CivitAI, con una amplia gama de LoRA que han utilizado Pony (y no SDXL) como modelo base y que requieren Pony en el momento de la inferencia.
Liberando
La página del proyecto para nuevo documento (que se titula HunyuanCustom: una arquitectura multimodal para la generación de vídeo personalizado) incluye enlaces a un Sitio de GitHub que, mientras escribo, acaba de volverse funcional y parece contener todo el código y los pesos necesarios para la implementación local, junto con un cronograma propuesto (donde lo único importante que aún está por venir es la integración de ComfyUI).
En el momento de redactar este artículo, el proyecto Presencia de rostro abrazado Sigue siendo un 404. Sin embargo, hay una Versión basada en API de donde aparentemente uno puede demostrar el sistema, siempre que pueda proporcionar un código de escaneo de WeChat.
Rara vez he visto un uso tan elaborado y extenso de una variedad tan amplia de proyectos en un solo ensamblaje, como es evidente en HunyuanCustom, y es de suponer que algunas de las licencias obligarían en todo caso a un lanzamiento completo.
Se anuncian dos modelos en la página de GitHub: una versión de 720px1280px que requiere 8 GB de memoria máxima de GPU y una versión de 512px896px que requiere 60 GB de memoria máxima de GPU.
Los estados del repositorio 'La memoria mínima de GPU requerida es de 24 GB para 720px1280px129f, pero es muy lenta... Recomendamos usar una GPU con 80 GB de memoria para una mejor calidad de generación' – y reitera que el sistema sólo ha sido probado hasta ahora en Linux.
El modelo anterior de Hunyuan Video ha sido, desde su lanzamiento oficial, cuantificado a tamaños en los que puede ejecutarse con menos de 24 GB de VRAM, y parece razonable suponer que el nuevo modelo también será adaptado a formas más amigables para el consumidor por la comunidad, y que rápidamente se adaptará para su uso también en sistemas Windows.
Debido a las limitaciones de tiempo y a la abrumadora cantidad de información que acompaña a este lanzamiento, solo podemos analizarlo en profundidad. No obstante, analicemos un poco a HunyuanCustom.
Una mirada al documento
El canal de datos de HunyuanCustom, aparentemente compatible con la GDPR El marco incorpora conjuntos de datos de vídeo sintetizados y de código abierto, incluidos OpenHumanVid, con ocho categorías principales representadas: los seres humanos., animales, plantas, paisajes, vehículos, objetos, arquitectura y animado.

Del documento publicado, se ofrece una descripción general de los diversos paquetes que contribuyen al proceso de construcción de datos de HunyuanCustom. Fuente: https://arxiv.org/pdf/2505.04512
El filtrado inicial comienza con Detección de escenas de PyScene, que segmenta los vídeos en clips de toma única. TextoBPN-Plus-Plus Luego se utiliza para eliminar vídeos que contienen texto excesivo, subtítulos, marcas de agua o logotipos en pantalla.
Para corregir las inconsistencias en la resolución y la duración, los clips se estandarizan a cinco segundos de duración y se redimensionan a 512 o 720 píxeles en el lado corto. El filtrado estético se gestiona mediante Koala-36M, con un umbral personalizado de 0.06 aplicado para el conjunto de datos personalizado seleccionado por los investigadores del nuevo artículo.
El proceso de extracción de sujetos combina la Qwen7B Modelo de lenguaje grande (LLM), el YOLO11X Marco de reconocimiento de objetos y el popular InsightFace arquitectura, para identificar y validar identidades humanas.
Para sujetos no humanos, QwenVL y SAM 2 puesto a tierra se utilizan para extraer cuadros delimitadores relevantes, que se descartan si son demasiado pequeños.

Ejemplos de segmentación semántica con Grounded SAM 2, utilizados en el proyecto Hunyuan Control. Fuente: https://github.com/IDEA-Research/Grounded-SAM-2
La extracción multisujeto utiliza florencia2 para la anotación del cuadro delimitador y Grounded SAM 2 para la segmentación, seguido de la agrupación y segmentación temporal de los marcos de entrenamiento.
Los clips procesados se mejoran aún más mediante anotaciones, utilizando un sistema de etiquetado estructurado patentado desarrollado por el equipo de Hunyuan, y que proporciona metadatos en capas, como descripciones y señales de movimiento de la cámara.
Aumento con máscara Se aplicaron estrategias, incluida la conversión a cuadros delimitadores, durante el entrenamiento para reducir sobreajuste y garantizar que el modelo se adapte a diversas formas de objetos.
Los datos de audio se sincronizaron utilizando el LatentSync mencionado anteriormente y los clips se descartaron si los puntajes de sincronización caen por debajo de un umbral mínimo.
El marco de evaluación de la calidad de la imagen a ciegas HiperIQA Se utilizó para excluir vídeos con una puntuación inferior a 40 (en la escala personalizada de HyperIQA). Las pistas de audio válidas se procesaron con Susurro para extraer características para tareas posteriores.
Los autores incorporan la LLaVA Modelo de asistente de lenguaje durante la fase de anotación, y enfatizan la importancia de este marco en HunyuanCustom. LLaVA se utiliza para generar subtítulos de imágenes y facilitar la alineación del contenido visual con las indicaciones textuales, lo que facilita la construcción de una señal de entrenamiento coherente en todas las modalidades.
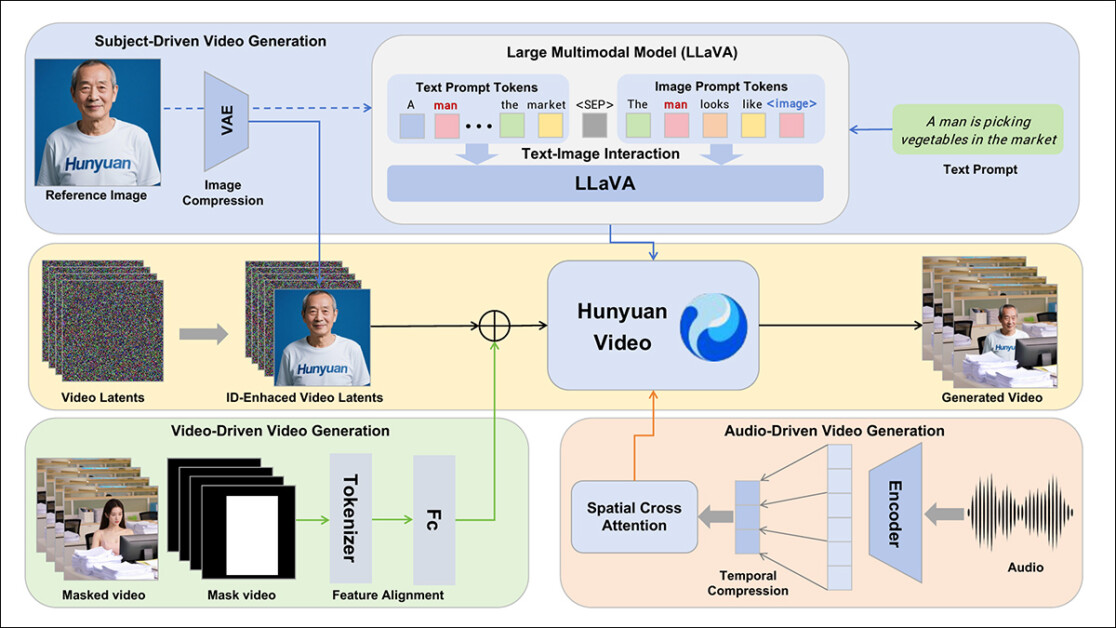
El marco HunyuanCustom admite la generación de vídeo consistente en cuanto a identidad condicionada a entradas de texto, imagen, audio y vídeo.
Al aprovechar las capacidades de alineación de visión y lenguaje de LLaVA, el canal obtiene una capa adicional de consistencia semántica entre los elementos visuales y sus descripciones textuales, especialmente valiosa en escenarios de múltiples sujetos o escenas complejas.
Video personalizado
Para permitir la generación de vídeo a partir de una imagen de referencia y un mensaje, se crearon los dos módulos centrados en LLaVA, primero adaptando la estructura de entrada de HunyuanVideo para que pudiera aceptar una imagen junto con el texto.
Esto implicó formatear el mensaje de forma que la imagen se incrustara directamente o se etiquetara con una breve descripción de identidad. Se utilizó un token separador para evitar que la incrustación de la imagen sobrecargara el contenido del mensaje.
Dado que el codificador visual de LLaVA tiende a comprimir o descartar detalles espaciales de grano fino durante la alineación de las características de la imagen y el texto (en particular cuando se traduce una sola imagen de referencia en una incrustación semántica general), un módulo de mejora de la identidad Se incorporó. Dado que casi todos los modelos de difusión latente de video tienen dificultades para mantener una identidad sin un LoRA, incluso en un clip de cinco segundos, el rendimiento de este módulo en las pruebas comunitarias podría ser significativo.
En cualquier caso, la imagen de referencia se redimensiona y se codifica utilizando el 3D-VAE causal del modelo original de HunyuanVideo, y su latente insertado en el video latente a través del eje temporal, con un desplazamiento espacial aplicado para evitar que la imagen se reproduzca directamente en la salida, mientras se sigue guiando la generación.
El modelo fue entrenado usando Coincidencia de flujo, con muestras de ruido extraídas de un logit-normal Distribución, y la red fue entrenada para recuperar el video correcto de estas latentes ruidosas. LLaVA y el generador de video se ajustaron conjuntamente para que la imagen y el mensaje pudieran guiar la salida con mayor fluidez y mantener la identidad del sujeto consistente.
Para indicaciones de múltiples temas, cada par de imagen-texto se integró por separado y se le asignó una posición temporal distinta, lo que permitió distinguir identidades y apoyó la generación de escenas que involucraban una variedad sujetos interactuantes.
Sonido y visión
HunyuanCustom condiciona la generación de audio/voz utilizando tanto el audio ingresado por el usuario como un mensaje de texto, lo que permite que los personajes hablen dentro de escenas que reflejan la configuración descrita.
Para respaldar esto, un módulo AudioNet con identidad desenredada introduce características de audio sin interrumpir las señales de identidad integradas de la imagen de referencia y el mensaje. Estas características se alinean con la línea de tiempo del video comprimido, se dividen en segmentos a nivel de fotograma y se inyectan mediante un enfoque espacial. atención cruzada mecanismo que mantiene cada fotograma aislado, preservando la consistencia del sujeto y evitando interferencias temporales.
Un segundo módulo de inyección temporal proporciona un control más preciso sobre el tiempo y el movimiento, trabajando en conjunto con AudioNet, asignando características de audio a regiones específicas de la secuencia latente y utilizando un Perceptrón multicapa (MLP) para convertirlos en token-wise Desplazamientos de movimiento. Esto permite que los gestos y el movimiento facial sigan el ritmo y el énfasis de la voz con mayor precisión.
HunyuanCustom permite editar directamente los sujetos de los vídeos existentes, reemplazando o insertando personas u objetos en una escena sin necesidad de reconstruir todo el clip desde cero. Esto resulta útil para tareas que implican modificar la apariencia o el movimiento de forma específica.
Dele "click" para jugar. Un ejemplo más del sitio complementario.
Para facilitar la sustitución eficiente de temas en los vídeos existentes, el nuevo sistema evita el enfoque intensivo en recursos de los métodos recientes, como el actualmente popular vace, o aquellos que fusionan secuencias de video completas, priorizando la compresión de un video de referencia mediante el 3D-VAE causal preentrenado, alineándolo con las latentes de video internas del canal de generación y luego sumándolos. Esto mantiene el proceso relativamente ligero, a la vez que permite que el contenido de video externo guíe la salida.
Una pequeña red neuronal gestiona la alineación entre el vídeo de entrada limpio y las latentes con ruido utilizadas en la generación. El sistema prueba dos maneras de inyectar esta información: fusionando los dos conjuntos de características antes de comprimirlos de nuevo; y añadiendo las características fotograma a fotograma. El segundo método funciona mejor, según los autores, y evita la pérdida de calidad, manteniendo la carga computacional inalterada.
Datos y Pruebas
En las pruebas, las métricas utilizadas fueron: el módulo de consistencia de identidad en Cara de arco, que extrae incrustaciones faciales tanto de la imagen de referencia como de cada fotograma del vídeo generado, y luego calcula la similitud del coseno promedio entre ellos; similitud de sujetos, mediante el envío de segmentos YOLO11x a Dino 2 para comparación; CLIP-B, alineación de texto y video, que mide la similitud entre el mensaje y el video generado; CLIP-B nuevamente, para calcular la similitud entre cada cuadro y sus cuadros vecinos y el primer cuadro, así como la consistencia temporal; y grado dinámico, Según lo definido por Banco virtual.
Como se indicó anteriormente, los competidores de código cerrado de referencia fueron Hailuo; Vidu 2.0; Kling (1.6); y Pika. Los frameworks FOSS competidores fueron VACE y SkyReels-A2.
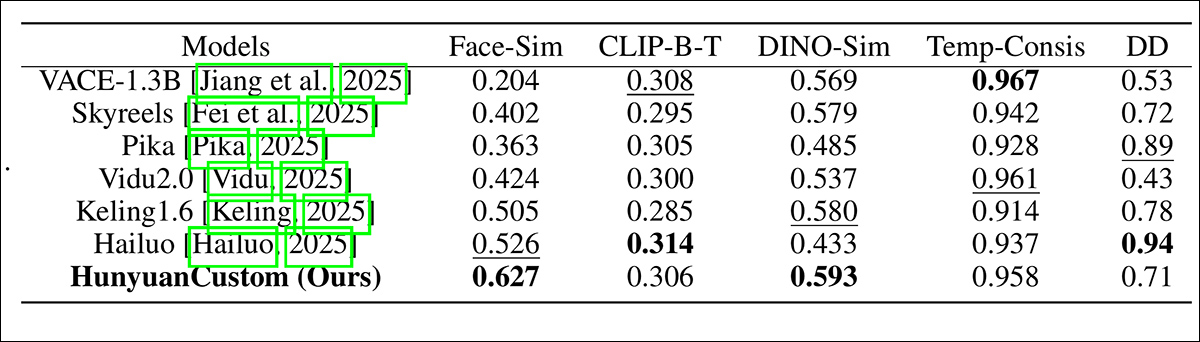
Evaluación del rendimiento del modelo comparando HunyuanCustom con los principales métodos de personalización de video en cuanto a consistencia de identificación (Face-Sim), similitud de sujetos (DINO-Sim), alineación texto-video (CLIP-BT), consistencia temporal (Temp-Consis) e intensidad de movimiento (DD). Los resultados óptimos y subóptimos se muestran en negrita y subrayados, respectivamente.
De estos resultados, los autores afirman:
Nuestro [HunyuanCustom] logra la mejor consistencia de identificación y consistencia del sujeto. También logra resultados comparables en seguimiento de indicaciones y consistencia temporal. [Hailuo] tiene la mejor puntuación de clip porque puede seguir bien las instrucciones de texto con solo consistencia de identificación, sacrificando la consistencia de los sujetos no humanos (el peor DINO-Sim). En cuanto al grado dinámico, [Vidu] y [VACE] tienen un rendimiento bajo, lo que podría deberse al pequeño tamaño del modelo.
Aunque el sitio web del proyecto está repleto de videos comparativos (cuyo diseño parece haber sido diseñado para la estética del sitio web, más que para facilitar la comparación), actualmente no incluye un video equivalente a los resultados estáticos agrupados en el PDF, en relación con las pruebas cualitativas iniciales. Aunque lo incluyo aquí, animo al lector a examinar con atención los videos en el sitio web del proyecto, ya que ofrecen una mejor visión de los resultados.
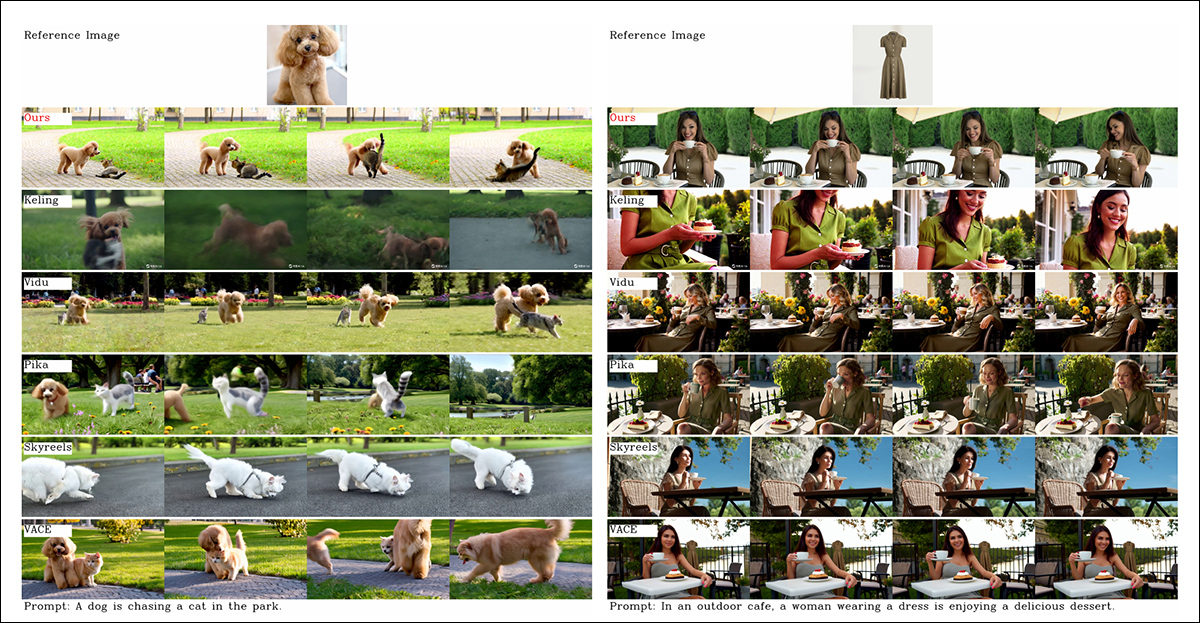
Del artículo, una comparación sobre la personalización de vídeo centrada en objetos. Si bien el espectador debería (como siempre) consultar el PDF original para una mejor resolución, los vídeos del sitio web del proyecto podrían ser un recurso más ilustrativo en este caso.
Los autores comentan aquí:
'Se puede ver que [Vidu], [Skyreels A2] y nuestro método logran resultados relativamente buenos en la alineación rápida y la consistencia del sujeto, pero nuestra calidad de video es mejor que la de Vidu y Skyreels, gracias al buen desempeño de generación de video de nuestro modelo base, es decir, [Hunyuanvideo-13B].
'Entre los productos comerciales, aunque [Kling] tiene una buena calidad de video, el primer cuadro del video tiene un [problema de] copiar y pegar, y a veces el sujeto se mueve demasiado rápido y [se ve borroso], lo que genera una mala experiencia de visualización.'
Los autores comentan además que Pika tiene un desempeño deficiente en términos de consistencia temporal, introduciendo artefactos en los subtítulos (efectos de una mala conservación de los datos, donde se ha permitido que elementos de texto en videoclips contaminen los conceptos centrales).
Hailuo conserva la identidad facial, afirman, pero no logra preservar la consistencia corporal completa. Entre los métodos de código abierto, VACE, afirman los investigadores, no logra mantener la consistencia de la identidad, mientras que HunyuanCustom, según ellos, produce videos con una sólida preservación de la identidad, a la vez que conserva la calidad y la diversidad.
A continuación se realizaron pruebas para personalización de vídeo multitema, contra los mismos contendientes. Como en el ejemplo anterior, los resultados en PDF aplanados no son equivalentes impresos de los videos disponibles en el sitio del proyecto, pero son únicos entre los resultados presentados:

Comparaciones con personalizaciones de vídeo multisujeto. Consulte el PDF para mayor detalle y resolución.
El documento dice:
[Pika] puede generar los sujetos especificados, pero presenta inestabilidad en los fotogramas de vídeo, con casos de un hombre que desaparece en un escenario y una mujer que no abre una puerta cuando se le indica. [Vidu] y [VACE] capturan parcialmente la identidad humana, pero pierden detalles significativos de los objetos no humanos, lo que indica una limitación en la representación de sujetos no humanos.
'[SkyReels A2] experimenta una grave inestabilidad de cuadros, con cambios notables en los chips y numerosos artefactos en el escenario correcto.
'Por el contrario, nuestro HunyuanCustom captura de manera efectiva identidades de sujetos tanto humanos como no humanos, genera videos que se adhieren a las indicaciones dadas y mantienen una alta calidad visual y estabilidad.'
Otro experimento fue el de la "publicidad humana virtual", en el que se encargó a los marcos integrar un producto con una persona:

Ejemplos de "colocación de producto" neuronal de la ronda de pruebas cualitativas. Consulte el PDF para obtener más detalles y resolución.
Para esta ronda, los autores afirman:
'Los [resultados] demuestran que HunyuanCustom mantiene eficazmente la identidad del ser humano al tiempo que preserva los detalles del producto de destino, incluido el texto que contiene.
'Además, la interacción entre el ser humano y el producto parece natural, y el vídeo se ajusta estrechamente a la instrucción dada, lo que resalta el potencial sustancial de HunyuanCustom en la generación de vídeos publicitarios.'
Un área en la que los resultados de vídeo habrían sido muy útiles fue la ronda cualitativa para la personalización de sujetos basada en audio, donde el personaje dice el audio correspondiente a una escena y una postura descritas en texto.
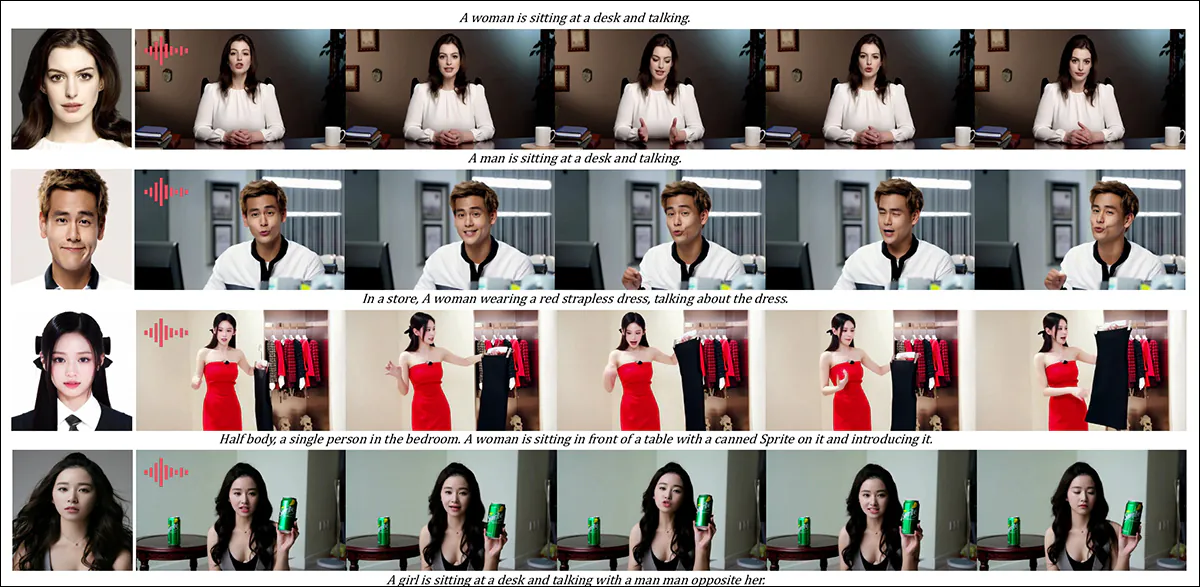
Resultados parciales de la ronda de audio, aunque en este caso habría sido preferible contar con resultados en video. Solo se reproduce aquí la mitad superior de la figura en PDF, ya que es grande y difícil de incluir en este artículo. Consulte el PDF original para obtener más detalles y resolución.
Los autores afirman:
'Los métodos anteriores de animación humana basados en audio ingresan una imagen humana y un audio, donde la postura humana, la vestimenta y el entorno siguen siendo consistentes con la imagen dada y no pueden generar videos con otros gestos y entornos, lo que puede [restringir] su aplicación.
'…[Nuestro] HunyuanCustom permite la personalización humana basada en audio, donde el personaje dice el audio correspondiente en una escena y postura descritas por texto, lo que permite una animación humana basada en audio más flexible y controlable.'
Otras pruebas (consulte el PDF para obtener todos los detalles) incluyeron una ronda que enfrentó al nuevo sistema contra VACE y Kling 1.6 para el reemplazo de sujetos de video:

Prueba de sustitución de sujetos en modo video a video. Consulte el PDF original para obtener más detalles y resolución.
De estas, las últimas pruebas presentadas en el nuevo artículo, los investigadores opinan:
VACE presenta artefactos en los bordes debido a la estricta adherencia a las máscaras de entrada, lo que resulta en formas poco naturales de los sujetos y una interrupción en la continuidad del movimiento. [Kling], en cambio, presenta un efecto de copiar y pegar, donde los sujetos se superponen directamente al video, lo que resulta en una integración deficiente con el fondo.
'En comparación, HunyuanCustom evita eficazmente los artefactos de los bordes, logra una integración perfecta con el fondo del video y mantiene una fuerte preservación de la identidad, lo que demuestra su desempeño superior en las tareas de edición de video.'
Conclusión
Se trata de un lanzamiento fascinante, sobre todo porque aborda algo sobre lo que la cada vez más descontenta escena de aficionados se ha estado quejando más últimamente: la falta de sincronización de labios, de modo que el mayor realismo posible en sistemas como Hunyuan Video y Wan 2.1 podría adquirir una nueva dimensión de autenticidad.
Aunque el diseño de casi todos los ejemplos de videos comparativos en el sitio del proyecto hace que sea bastante difícil comparar las capacidades de HunyuanCustom contra los contendientes anteriores, debe notarse que muy, muy pocos proyectos en el espacio de síntesis de video tienen el coraje de enfrentarse en pruebas contra Kling, la API de difusión de video comercial que siempre está rondando o cerca de la cima de las tablas de clasificación; Tencent parece haber avanzado contra este titular de una manera bastante impresionante.
* El problema es que algunos de los videos son tan anchos, cortos y de alta resolución que no se reproducen en reproductores de video estándar como VLC o Windows Media Player y muestran pantallas negras.
Primera publicación: jueves 8 de mayo de 2025












