
Inteligencia artificial
MagicDance: Generación de videos de danza humana realista

La visión por computadora es uno de los campos más discutidos en la industria de la IA, gracias a sus posibles aplicaciones en una amplia gama de tareas en tiempo real. En los últimos años, los marcos de visión por computadora han avanzado rápidamente y ahora los modelos modernos son capaces de analizar rasgos faciales, objetos y mucho más en escenarios en tiempo real. A pesar de estas capacidades, la transferencia del movimiento humano sigue siendo un desafío formidable para los modelos de visión por computadora. Esta tarea implica redireccionar los movimientos faciales y corporales desde una imagen o video de origen a una imagen o video de destino. La transferencia de movimiento humano se usa ampliamente en modelos de visión por computadora para diseñar imágenes o videos, editar contenido multimedia, síntesis humana digital e incluso generar datos para marcos basados en la percepción.
En este artículo, nos centramos en MagicDance, un modelo basado en difusión diseñado para revolucionar la transferencia del movimiento humano. El marco MagicDance tiene como objetivo específico transferir expresiones y movimientos faciales humanos en 2D a videos de danza humana desafiantes. Su objetivo es generar videos de baile novedosos basados en secuencias de poses para identidades objetivo específicas manteniendo la identidad original. El marco MagicDance emplea una estrategia de entrenamiento de dos etapas, centrándose en el desenredo del movimiento humano y factores de apariencia como el tono de la piel, las expresiones faciales y la ropa. Profundizaremos en el marco MagicDance, explorando su arquitectura, funcionalidad y rendimiento en comparación con otros marcos de transferencia de movimiento humano de última generación. Vamos a sumergirnos.
MagicDance: Transferencia de movimiento humano realista
Como se mencionó anteriormente, la transferencia de movimiento humano es una de las tareas de visión por computadora más complejas debido a la gran complejidad que implica transferir movimientos y expresiones humanos desde la imagen o video de origen a la imagen o video de destino. Tradicionalmente, los marcos de visión por computadora han logrado la transferencia del movimiento humano entrenando un modelo generativo de tarea específica que incluye GAN o Redes generativas antagónicas en conjuntos de datos objetivo para expresiones faciales y poses corporales. Aunque el entrenamiento y el uso de modelos generativos arrojan resultados satisfactorios en algunos casos, generalmente adolecen de dos limitaciones importantes.
- Dependen en gran medida de un componente de deformación de la imagen, como resultado de lo cual a menudo tienen dificultades para interpolar partes del cuerpo invisibles en la imagen de origen, ya sea debido a un cambio de perspectiva o a una autooclusión.
- No pueden generalizar a otras imágenes obtenidas externamente, lo que limita sus aplicaciones, especialmente en escenarios en tiempo real en la naturaleza.

Los modelos de difusión modernos han demostrado capacidades excepcionales de generación de imágenes en diferentes condiciones, y los modelos de difusión ahora son capaces de presentar imágenes potentes en una variedad de tareas posteriores, como la generación de videos y la pintura de imágenes, aprendiendo de conjuntos de datos de imágenes a escala web. Debido a sus capacidades, los modelos de difusión podrían ser una opción ideal para las tareas de transferencia de movimiento humano. Aunque los modelos de difusión se pueden implementar para la transferencia de movimiento humano, tienen algunas limitaciones ya sea en términos de la calidad del contenido generado, o en términos de preservación de la identidad o sufren de inconsistencias temporales como resultado de los límites de la estrategia de entrenamiento y diseño del modelo. Además, los modelos basados en difusión no demuestran ninguna ventaja significativa sobre Marcos GAN en términos de generalización.
Para superar los obstáculos que enfrentan los marcos de difusión y basados en GAN en las tareas de transferencia de movimiento humano, los desarrolladores han presentado MagicDance, un marco novedoso que tiene como objetivo explotar el potencial de los marcos de difusión para la transferencia de movimiento humano demostrando un nivel sin precedentes de preservación de la identidad, calidad visual superior, y generalización del dominio. En esencia, el concepto fundamental del marco MagicDance es dividir el problema en dos etapas: control de apariencia y control de movimiento, dos capacidades requeridas por los marcos de difusión de imágenes para ofrecer resultados de transferencia de movimiento precisos.

La figura anterior ofrece una breve descripción general del marco MagicDance y, como puede verse, el marco emplea el Modelo de difusión establey también implementa dos componentes adicionales: Modelo de control de apariencia y Pose ControlNet, donde el primero proporciona guía de apariencia al modelo SD desde una imagen de referencia a través de la atención, mientras que el segundo proporciona guía de expresión/pose al modelo de difusión a partir de una imagen o video condicionado. El marco también emplea una estrategia de entrenamiento de múltiples etapas para aprender estos submódulos de manera efectiva para desenredar el control de pose y la apariencia.
En resumen, el marco MagicDance es un
- Marco novedoso y eficaz que consiste en control de postura desenredado de la apariencia y preentrenamiento del control de la apariencia.
- El marco MagicDance es capaz de generar expresiones faciales humanas realistas y movimientos humanos bajo el control de entradas de condición de pose e imágenes o videos de referencia.
- El marco MagicDance tiene como objetivo generar contenido humano con apariencia consistente mediante la introducción de un módulo de atención de fuentes múltiples que ofrece una guía precisa para el marco UNet de difusión estable.
- El marco MagicDance también se puede utilizar como una extensión o complemento conveniente para el marco Stable Diffusion y también garantiza la compatibilidad con los pesos de los modelos existentes, ya que no requiere ajustes adicionales de los parámetros.
Además, el marco MagicDance muestra capacidades de generalización excepcionales tanto para la apariencia como para la generalización del movimiento.
- Generalización de apariencia: el marco MagicDance demuestra capacidades superiores cuando se trata de generar diversas apariencias.
- Generalización de movimiento: el marco MagicDance también tiene la capacidad de generar una amplia gama de movimientos.
MagicDance: Objetivos y Arquitectura
Para una imagen de referencia dada, ya sea de un ser humano real o una imagen estilizada, el objetivo principal del marco MagicDance es generar una imagen de salida o un video de salida condicionado a la entrada y las entradas de pose {P, F} donde P representa la pose humana. esqueleto y F representa los puntos de referencia faciales. La imagen o video de salida generado debe poder preservar la apariencia y la identidad de los humanos involucrados junto con los contenidos de fondo presentes en la imagen de referencia, al tiempo que conserva la pose y las expresiones definidas por las entradas de pose.
Arquitectura
Durante el entrenamiento, el marco MagicDance se entrena como una tarea de reconstrucción de cuadros para reconstruir la verdad del terreno con la imagen de referencia y la entrada de pose procedente del mismo video de referencia. Durante las pruebas para lograr la transferencia de movimiento, la entrada de pose y la imagen de referencia provienen de diferentes fuentes.
La arquitectura general del marco MagicDance se puede dividir en cuatro categorías: etapa preliminar, preentrenamiento de control de apariencia, control de pose desenredado de apariencia y módulo de movimiento.
Etapa preliminar
Los modelos de difusión latente o LDM representan modelos de difusión diseñados exclusivamente para operar dentro del espacio latente facilitado por el uso de un codificador automático, y el marco de difusión estable es un ejemplo notable de LDM que emplea un vector cuantificado-variacional. Codificador automático y arquitectura temporal U-Net. El modelo Stable Diffusion emplea un transformador basado en CLIP como codificador de texto para procesar entradas de texto mediante la conversión de entradas de texto en incrustaciones. La fase de entrenamiento del marco de Difusión Estable expone el modelo a una condición de texto y una imagen de entrada con el proceso que implica la codificación de la imagen en una representación latente, y lo somete a una secuencia predefinida de pasos de difusión dirigidos por un método gaussiano. La secuencia resultante produce una representación latente ruidosa que proporciona una distribución normal estándar, siendo el principal objetivo de aprendizaje del marco de Difusión Estable eliminar el ruido de las representaciones latentes ruidosas de forma iterativa y convertirlas en representaciones latentes.
Preentrenamiento de control de apariencia
Un problema importante con el marco ControlNet original es su incapacidad para controlar consistentemente la apariencia entre movimientos que varían espacialmente, aunque tiende a generar imágenes con poses muy parecidas a las de la imagen de entrada y la apariencia general está influenciada predominantemente por entradas textuales. Aunque este método funciona, no es adecuado para la transferencia de movimiento que involucra tareas en las que no son las entradas de texto sino la imagen de referencia la que sirve como fuente principal de información sobre la apariencia.
El módulo de preentrenamiento de control de apariencia en el marco MagicDance está diseñado como una rama auxiliar para proporcionar orientación para el control de apariencia en un enfoque capa por capa. En lugar de depender de entradas de texto, el módulo general se centra en aprovechar los atributos de apariencia de la imagen de referencia con el objetivo de mejorar la capacidad del marco para generar las características de apariencia con precisión, particularmente en escenarios que involucran dinámicas de movimiento complejas. Además, sólo el modelo de control de apariencia se puede entrenar durante el preentrenamiento del control de apariencia.
Control de pose desenredado por la apariencia
Una solución ingenua para controlar la pose en la imagen de salida es integrar el modelo ControlNet previamente entrenado con el modelo de control de apariencia previamente entrenado directamente sin realizar ajustes. Sin embargo, la integración podría hacer que el marco tenga problemas con el control de pose independiente de la apariencia, lo que puede generar una discrepancia entre las poses de entrada y las poses generadas. Para abordar esta discrepancia, el marco MagicDance afina el modelo Pose ControlNet junto con el modelo de control de apariencia previamente entrenado.
Módulo Motion
Cuando trabajan juntos, Pose ControlNet desenredado de apariencia y el modelo de control de apariencia pueden lograr una transferencia de imagen a movimiento precisa y efectiva, aunque puede resultar en una inconsistencia temporal. Para garantizar la coherencia temporal, el marco integra un módulo de movimiento adicional en la arquitectura primaria Stable Diffusion UNet.
MagicDance: preentrenamiento y conjuntos de datos
Para el entrenamiento previo, el marco MagicDance utiliza un conjunto de datos de TikTok que consta de más de 350 videos de baile de diferentes duraciones, entre 10 y 15 segundos, que capturan a una sola persona bailando y la mayoría de estos videos contienen la cara y la parte superior del cuerpo. el humano. El marco MagicDance extrae cada vídeo individual a 30 FPS y ejecuta OpenPose en cada fotograma individualmente para inferir la pose del esqueleto, las posturas de las manos y los puntos de referencia faciales.
Para el entrenamiento previo, el modelo de control de apariencia se entrena previamente con un tamaño de lote de 64 en 8 GPU NVIDIA A100 para 10 mil pasos con un tamaño de imagen de 512 x 512, seguido del ajuste conjunto de los modelos de control de pose y control de apariencia con un tamaño de lote de 16 para 20 mil pasos. Durante el entrenamiento, el marco MagicDance toma muestras aleatorias de dos fotogramas como objetivo y referencia, respectivamente, y las imágenes se recortan en la misma posición a la misma altura. Durante la evaluación, el modelo recorta la imagen centralmente en lugar de recortarla al azar.
MagicDance: Resultados
Los resultados experimentales realizados en el marco MagicDance se demuestran en la siguiente imagen y, como puede verse, el marco MagicDance supera a los marcos existentes como Disco y DreamPose en cuanto a la transferencia del movimiento humano en todas las métricas. Los marcos que contienen un “*” delante de su nombre utilizan la imagen de destino directamente como entrada e incluyen más información en comparación con los otros marcos.
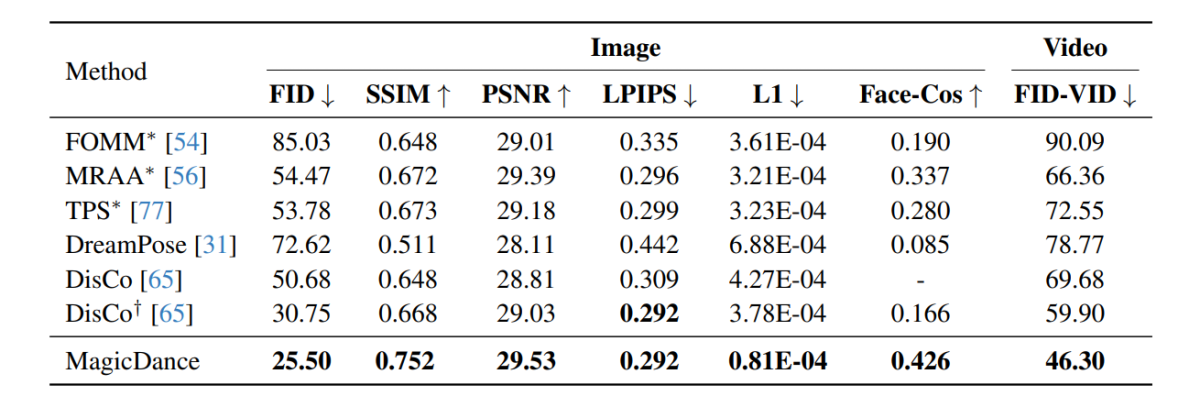
Es interesante observar que el marco MagicDance alcanza una puntuación Face-Cos de 0.426, una mejora del 156.62 % con respecto al marco Disco y un aumento de casi el 400 % en comparación con el marco DreamPose. Los resultados indican la sólida capacidad del marco MagicDance para preservar la información de identidad, y el aumento visible en el rendimiento indica la superioridad del marco MagicDance sobre los métodos de última generación existentes.
Las siguientes figuras comparan la calidad de la generación de video humano entre los marcos MagicDance, Disco y TPS. Como se puede observar, los resultados generados por los marcos GT, Disco y TPS adolecen de identidad de pose humana y expresiones faciales inconsistentes.

Además, la siguiente imagen demuestra la visualización de la expresión facial y la transferencia de poses humanas en el conjunto de datos de TikTok con el marco MagicDance, capaz de generar expresiones y movimientos realistas y vívidos bajo diversos puntos de referencia faciales y pose entradas de esqueleto mientras se preserva con precisión la información de identidad de la entrada de referencia. imagen.

Vale la pena señalar que el marco MagicDance cuenta con capacidades excepcionales de generalización a imágenes de referencia fuera del dominio de poses y estilos invisibles con una controlabilidad de apariencia impresionante, incluso sin ningún ajuste adicional en el dominio objetivo. Los resultados se demuestran en la siguiente imagen. .

Las siguientes imágenes demuestran las capacidades de visualización del marco MagicDance en términos de transferencia de expresiones faciales y movimiento humano de disparo cero. Como puede verse, el marco MagicDance se generaliza perfectamente a los movimientos humanos en la naturaleza.

MagicDance: Limitaciones
OpenPose es un componente esencial del marco MagicDance, ya que desempeña un papel crucial para el control de la pose, afectando significativamente la calidad y la coherencia temporal de las imágenes generadas. Sin embargo, al marco MagicDance todavía le resulta un poco difícil detectar puntos de referencia faciales y posar esqueletos con precisión, especialmente cuando los objetos en las imágenes son parcialmente visibles o muestran movimientos rápidos. Estos problemas pueden provocar artefactos en la imagen generada.
Conclusión
En este artículo, hemos hablado de MagicDance, un modelo basado en difusión que pretende revolucionar la transferencia del movimiento humano. El marco MagicDance intenta transferir expresiones y movimientos faciales humanos en 2D en videos de danza humana desafiantes con el objetivo específico de generar videos de danza humana impulsados por secuencias de poses novedosas para identidades objetivo específicas mientras se mantiene la identidad constante. El marco MagicDance es una estrategia de entrenamiento de dos etapas para desenredar el movimiento humano y la apariencia, como el tono de la piel, las expresiones faciales y la ropa.
MagicDance es un enfoque novedoso para facilitar la generación de videos humanos realistas al incorporar la transferencia de expresiones faciales y de movimiento, y permitir una generación de animación consistente en la naturaleza sin necesidad de ningún ajuste adicional que demuestre un avance significativo sobre los métodos existentes. Además, el marco MagicDance demuestra capacidades de generalización excepcionales sobre secuencias de movimiento complejas y diversas identidades humanas, lo que establece el marco MagicDance como líder en el campo de la transferencia de movimiento asistida por IA y la generación de video.















