Τεχνητή νοημοσύνη 101
Τι είναι το Θεώρημα του Bayes;
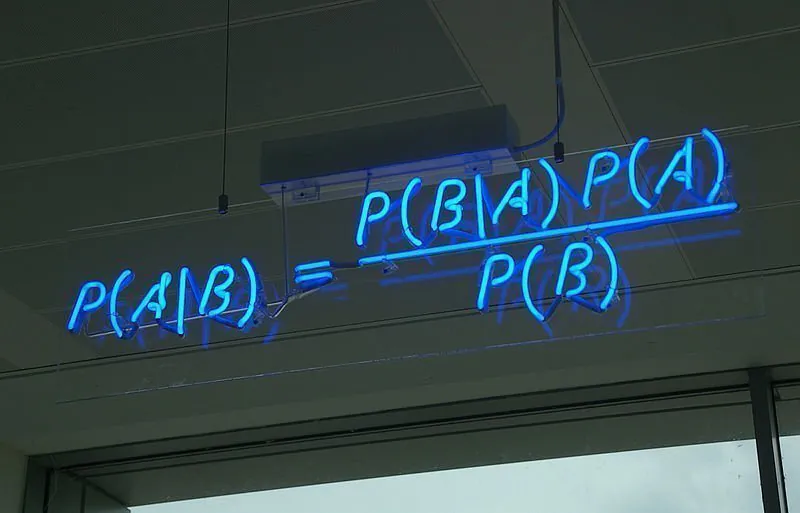
Αν έχετε μάθει για την επιστήμη των δεδομένων ή το machine learning, υπάρχει μια καλή πιθανότητα να έχετε ακούσει τον όρο “Θεώρημα του Bayes” trước, ή einen “ταξινομητή Bayes”. Αυτές οι έννοιες μπορούν να είναι κάπως συναρπαστικές, đặc biệt αν δεν είστε συνηθισμένοι να σκέφτεστε την πιθανότητα από μια παραδοσιακή, συχνιστική στατιστική προοπτική. Αυτό το άρθρο θα προσπαθήσει να εξηγήσει τις αρχές πίσω από το Θεώρημα του Bayes και πώς χρησιμοποιείται στο machine learning.
Τι είναι το Θεώρημα του Bayes;
Το Θεώρημα του Bayes είναι μια μέθοδος υπολογισμού της συνθηκικής πιθανότητας. Η παραδοσιακή μέθοδος υπολογισμού της συνθηκικής πιθανότητας (η πιθανότητα ότι ένα γεγονός συμβαίνει υπό την επίδραση ενός διαφορετικού γεγονότος) είναι να χρησιμοποιηθεί η συνθηκική πιθανότητα формуλα, υπολογίζοντας την κοινή πιθανότητα του γεγονότος ένα και του γεγονότος δύο να συμβαίνουν την ίδια στιγμή, και στη συνέχεια να διαιρέσετε από την πιθανότητα του γεγονότος δύο να συμβαίνει. Ωστόσο, η συνθηκική πιθανότητα μπορεί επίσης να υπολογιστεί με ένα немного διαφορετικό τρόπο χρησιμοποιώντας το Θεώρημα του Bayes.
Όταν υπολογίζουμε τη συνθηκική πιθανότητα με το Θεώρημα του Bayes, χρησιμοποιούμε τα ακόλουθα βήματα:
- Καθορίστε την πιθανότητα της συνθήκης Β να είναι αληθής, υποθέτοντας ότι η συνθήκη Α είναι αληθής.
- Καθορίστε την πιθανότητα του γεγονότος Α να είναι αληθές.
- Πολυπλασιάστε τις δύο πιθανότητες μαζί.
- Διαιρέστε από την πιθανότητα του γεγονότος Β να συμβαίνει.
Αυτό σημαίνει ότι η формуλα για το Θεώρημα του Bayes μπορεί να εκφραστεί όπως αυτό:
P(A|B) = P(B|A)*P(A) / P(B)
Ο υπολογισμός της συνθηκικής πιθανότητας με αυτόν τον τρόπο είναι ιδιαίτερα χρήσιμος όταν η αντίστροφη συνθηκική πιθανότητα μπορεί να υπολογιστεί εύκολα, ή όταν ο υπολογισμός της κοινής πιθανότητας θα ήταν πολύ δύσκολος.
Παράδειγμα του Θεώρηματος του Bayes
Αυτό μπορεί να είναι πιο εύκολο να ερμηνευτεί αν περάσουμε κάποιο χρόνο εξετάζοντας ένα παράδειγμα του πώς θα εφαρμόζαμε τη λογική του Bayes και το Θεώρημα του Bayes. Ας υποθέσουμε ότι παίζατε ένα απλό παιχνίδι όπου πολλοί συμμετέχοντες σας λένε μια ιστορία και πρέπει να καθορίσετε ποιος από τους συμμετέχοντες ψεύδεται σε σας. Ας γεμίσουμε την εξίσωση για το Θεώρημα του Bayes με τις μεταβλητές σε αυτό το υποθετικό σενάριο.
Προσπαθούμε να προβλέψουμε αν κάθε άτομο στο παιχνίδι ψεύδεται ή λέει την αλήθεια, οπότε αν υπάρχουν τρεις παίκτες εκτός από εσάς, οι κατηγορικές μεταβλητές μπορούν να εκφραστούν ως A1, A2 και A3. Τα στοιχεία για τα ψέματα/την αλήθεια τους είναι η συμπεριφορά τους. Όπως όταν παίζατε πόκερ, θα ψάχνατε για certains “συνήθειες” που ένα άτομο ψεύδεται και θα τα χρησιμοποιούσατε ως κομμάτια πληροφορίας για να ενημερώσετε την εκτίμηση σας. Ή αν σας επιτρεπόταν να τους ρωτήσετε, θα ήταν οποιοδήποτε στοιχείο που η ιστορία τους δεν προσθέτει. Μπορούμε να αντιπροσωπεύσουμε τα στοιχεία ότι ένα άτομο ψεύδεται ως Β.
Για να είμαστε σαφείς, προσπαθούμε να προβλέψουμε την Πιθανότητα(Α ψεύδεται/λέει την αλήθεια|με τα στοιχεία της συμπεριφοράς τους). Για να το κάνουμε αυτό, θα ήθελα να καθορίσω την πιθανότητα του Β να δώσει Α, ή την πιθανότητα ότι η συμπεριφορά τους θα συμβαίνει υπό την επίδραση του ατόμου να ψεύδεται ή να λέει την αλήθεια. Προσπαθώ να καθορίσω υπό ποιες συνθήκες η συμπεριφορά που βλέπω θα είχε την περισσότερη λογική. Αν υπάρχουν τρεις συμπεριφορές που παρατηρώ, θα κάνατε τον υπολογισμό για κάθε συμπεριφορά. Για παράδειγμα, P(B1, B2, B3 * A). Θα το κάνατε αυτό για κάθε εμφάνιση του Α/για κάθε άτομο στο παιχνίδι εκτός από εσάς. Αυτό είναι αυτό το μέρος της εξίσωσης παραπάνω:
P(B1, B2, B3,|A) * P|A
Τέλος, απλώς διαιρούμε αυτό από την πιθανότητα του Β.
Αν λάβουμε οποιαδήποτε στοιχεία σχετικά με τις πραγματικές πιθανότητες σε αυτήν την εξίσωση, θα αναδημιουργούμε το μοντέλο πιθανότητας μας, λαμβάνοντας υπόψη τα νέα στοιχεία. Αυτό ονομάζεται ενημέρωση των προκαταλήψεων σας, καθώς ενημερώνετε τις υποθέσεις σας σχετικά με την πιθανότητα των παρατηρούμενων γεγονότων.
Εφαρμογές του Machine Learning για το Θεώρημα του Bayes
Η πιο συνηθισμένη χρήση του Θεώρηματος του Bayes όταν πρόκειται για machine learning είναι στη μορφή του αλγορίθμου Naive Bayes.
Ο αλγόριθμος Naive Bayes χρησιμοποιείται για την ταξινόμηση και των δυαδικών και των πολυκατηγορικών συνόλων δεδομένων, ο αλγόριθμος Naive Bayes πήρε το όνομά του επειδή οι τιμές που ανατεθούν στα στοιχεία/τα χαρακτηριστικά – τα Β στο P(B1, B2, B3 * A) – θεωρούνται ανεξάρτητα το ένα από το άλλο. Θεωρείται ότι αυτά τα χαρακτηριστικά δεν επηρεάζουν το ένα το άλλο για να απλοποιηθεί το μοντέλο και να γίνουν δυνατοί οι υπολογισμοί, αντί να προσπαθήσουμε να υπολογίσουμε τις σχέσεις μεταξύ κάθε χαρακτηριστικού.尽管 αυτή η απλοποιημένη εκδοχή του μοντέλου, ο αλγόριθμος Naive Bayes τείνει να λειτουργεί khá καλά ως αλγόριθμος ταξινόμησης, ακόμη και όταν αυτή η υπόθεση πιθανότατα δεν είναι αληθής (που είναι η περισσότερη φορά).
Υπάρχουν επίσης συνήθως χρησιμοποιούμενες παραλλαγές του ταξινομητή Naive Bayes, όπως ο Multinomial Naive Bayes, ο Bernoulli Naive Bayes και ο Gaussian Naive Bayes.
Οι αλγόριθμοι Multinomial Naive Bayes χρησιμοποιούνται συχνά για την ταξινόμηση εγγράφων, καθώς είναι αποτελεσματικοί στην ερμηνεία της συχνότητας των λέξεων μέσα σε ένα έγγραφο.
Ο αλγόριθμος Bernoulli Naive Bayes λειτουργεί παρόμοια με τον Multinomial Naive Bayes, αλλά οι προβλέψεις που παράγει ο αλγόριθμος είναι boolean. Αυτό σημαίνει ότι όταν προβλέπετε μια κατηγορία, οι τιμές θα είναι δυαδικές, ναι ή όχι. Στο πεδίο της ταξινόμησης κειμένου, ένας αλγόριθμος Bernoulli Naive Bayes θα ανατεθεί στα παραμέτρους ναι ή όχι με βάση το αν μια λέξη υπάρχει ή όχι στο έγγραφο κειμένου.
Αν η τιμή των προβλεπτών/χαρακτηριστικών δεν είναι διακριτά αλλά συνεχείς, ο Gaussian Naive Bayes μπορεί να χρησιμοποιηθεί. Θεωρείται ότι οι τιμές των συνεχών χαρακτηριστικών έχουν δειγματιστεί από μια κανονική κατανομή.












