
AI 101
Τι είναι η μείωση διαστάσεων;
Τι είναι η μείωση διαστάσεων;
Μείωση διαστάσεων είναι μια διαδικασία που χρησιμοποιείται για τη μείωση της διάστασης ενός συνόλου δεδομένων, λαμβάνοντας πολλά χαρακτηριστικά και αντιπροσωπεύοντάς τα ως λιγότερα χαρακτηριστικά. Για παράδειγμα, η μείωση διαστάσεων θα μπορούσε να χρησιμοποιηθεί για τη μείωση ενός συνόλου είκοσι χαρακτηριστικών σε λίγα μόνο χαρακτηριστικά. Η μείωση διαστάσεων χρησιμοποιείται συνήθως σε μη εποπτευόμενη μάθηση εργασίες για αυτόματη δημιουργία τάξεων από πολλές δυνατότητες. Για να καταλάβουμε καλύτερα γιατί και πώς χρησιμοποιείται η μείωση διαστάσεων, θα ρίξουμε μια ματιά στα προβλήματα που σχετίζονται με τα δεδομένα υψηλών διαστάσεων και τις πιο δημοφιλείς μεθόδους μείωσης των διαστάσεων.
Περισσότερες διαστάσεις οδηγούν σε υπερπροσαρμογή
Η διάσταση αναφέρεται στον αριθμό των χαρακτηριστικών/στηλών σε ένα σύνολο δεδομένων.
Συχνά θεωρείται ότι στη μηχανική εκμάθηση περισσότερες δυνατότητες είναι καλύτερες, καθώς δημιουργεί ένα πιο ακριβές μοντέλο. Ωστόσο, περισσότερες δυνατότητες δεν μεταφράζονται απαραίτητα σε καλύτερο μοντέλο.
Τα χαρακτηριστικά ενός συνόλου δεδομένων μπορεί να διαφέρουν πολύ ως προς το πόσο χρήσιμα είναι για το μοντέλο, με πολλά χαρακτηριστικά να είναι μικρής σημασίας. Επιπλέον, όσο περισσότερα χαρακτηριστικά περιέχει το σύνολο δεδομένων, τόσο περισσότερα δείγματα χρειάζονται για να διασφαλιστεί ότι οι διαφορετικοί συνδυασμοί χαρακτηριστικών αντιπροσωπεύονται καλά στα δεδομένα. Επομένως, ο αριθμός των δειγμάτων αυξάνεται ανάλογα με τον αριθμό των χαρακτηριστικών. Περισσότερα δείγματα και περισσότερα χαρακτηριστικά σημαίνουν ότι το μοντέλο πρέπει να είναι πιο περίπλοκο και καθώς τα μοντέλα γίνονται πιο σύνθετα γίνονται πιο ευαίσθητα στην υπερβολική προσαρμογή. Το μοντέλο μαθαίνει πολύ καλά τα μοτίβα στα δεδομένα εκπαίδευσης και αποτυγχάνει να γενικευτεί σε δεδομένα εκτός δείγματος.
Η μείωση της διάστασης ενός συνόλου δεδομένων έχει πολλά πλεονεκτήματα. Όπως αναφέρθηκε, τα απλούστερα μοντέλα είναι λιγότερο επιρρεπή σε υπερπροσαρμογή, καθώς το μοντέλο πρέπει να κάνει λιγότερες υποθέσεις σχετικά με το πώς σχετίζονται τα χαρακτηριστικά μεταξύ τους. Επιπλέον, λιγότερες διαστάσεις σημαίνουν ότι απαιτείται λιγότερη υπολογιστική ισχύς για την εκπαίδευση των αλγορίθμων. Ομοίως, απαιτείται λιγότερος χώρος αποθήκευσης για ένα σύνολο δεδομένων που έχει μικρότερες διαστάσεις. Η μείωση της διάστασης ενός συνόλου δεδομένων μπορεί επίσης να σας επιτρέψει να χρησιμοποιήσετε αλγόριθμους που δεν είναι κατάλληλοι για σύνολα δεδομένων με πολλές δυνατότητες.
Κοινές μέθοδοι μείωσης διαστάσεων
Η μείωση των διαστάσεων μπορεί να γίνει με επιλογή χαρακτηριστικών ή μηχανική χαρακτηριστικών. Η επιλογή χαρακτηριστικών είναι όπου ο μηχανικός προσδιορίζει τα πιο σχετικά χαρακτηριστικά του συνόλου δεδομένων, ενώ μηχανική χαρακτηριστικών είναι η διαδικασία δημιουργίας νέων χαρακτηριστικών με συνδυασμό ή μετατροπή άλλων χαρακτηριστικών.
Η επιλογή χαρακτηριστικών και η μηχανική μπορούν να γίνουν μέσω προγραμματισμού ή χειροκίνητα. Κατά την επιλογή και τη μηχανική μηχανική χαρακτηριστικών, η οπτικοποίηση των δεδομένων για την ανακάλυψη συσχετίσεων μεταξύ χαρακτηριστικών και κλάσεων είναι τυπική. Η διεξαγωγή μείωσης διαστάσεων με αυτόν τον τρόπο μπορεί να είναι αρκετά χρονοβόρα και επομένως μερικοί από τους πιο συνηθισμένους τρόπους μείωσης της διαστάσεων περιλαμβάνουν τη χρήση αλγορίθμων που διατίθενται σε βιβλιοθήκες όπως το Scikit-learn για Python. Αυτοί οι κοινοί αλγόριθμοι μείωσης διαστάσεων περιλαμβάνουν: Ανάλυση Κύριων Στοιχείων (PCA), Αποσύνθεση Ενιαίας Τιμής (SVD) και Γραμμική Διακριτική Ανάλυση (LDA).
Οι αλγόριθμοι που χρησιμοποιούνται στη μείωση διαστάσεων για εργασίες μάθησης χωρίς επίβλεψη είναι συνήθως οι PCA και SVD, ενώ αυτοί που χρησιμοποιούνται για τη μείωση των διαστάσεων εποπτευόμενης μάθησης είναι συνήθως LDA και PCA. Στην περίπτωση μοντέλων εποπτευόμενης εκμάθησης, οι νέες δυνατότητες που δημιουργήθηκαν απλώς τροφοδοτούνται στον ταξινομητή μηχανικής εκμάθησης. Λάβετε υπόψη ότι οι χρήσεις που περιγράφονται εδώ είναι απλώς περιπτώσεις γενικής χρήσης και όχι οι μόνες συνθήκες στις οποίες μπορούν να χρησιμοποιηθούν αυτές οι τεχνικές. Οι αλγόριθμοι μείωσης διαστάσεων που περιγράφονται παραπάνω είναι απλώς στατιστικές μέθοδοι και χρησιμοποιούνται εκτός μοντέλων μηχανικής εκμάθησης.
Ανάλυση κύριων συστατικών

Φωτογραφία: Matrix με τα κύρια συστατικά που προσδιορίζονται
Ανάλυση κύριων συστατικών (PCA) είναι μια στατιστική μέθοδος που αναλύει τα χαρακτηριστικά/χαρακτηριστικά ενός συνόλου δεδομένων και συνοψίζει τα χαρακτηριστικά που έχουν τη μεγαλύτερη επιρροή. Τα χαρακτηριστικά του συνόλου δεδομένων συνδυάζονται σε αναπαραστάσεις που διατηρούν τα περισσότερα από τα χαρακτηριστικά των δεδομένων αλλά κατανέμονται σε λιγότερες διαστάσεις. Μπορείτε να το σκεφτείτε αυτό ως «συμπίεση» των δεδομένων από μια αναπαράσταση υψηλότερης διάστασης σε μια με λίγες μόνο διαστάσεις.
Ως παράδειγμα μιας κατάστασης όπου το PCA μπορεί να είναι χρήσιμο, σκεφτείτε τους διάφορους τρόπους που θα μπορούσε κανείς να περιγράψει το κρασί. Ενώ είναι δυνατό να περιγραφεί το κρασί χρησιμοποιώντας πολλά ιδιαίτερα ειδικά χαρακτηριστικά όπως επίπεδα CO2, επίπεδα αερισμού κ.λπ., τέτοια συγκεκριμένα χαρακτηριστικά μπορεί να είναι σχετικά άχρηστα όταν προσπαθείτε να αναγνωρίσετε έναν συγκεκριμένο τύπο κρασιού. Αντίθετα, θα ήταν πιο συνετό να προσδιορίσετε τον τύπο με βάση πιο γενικά χαρακτηριστικά όπως η γεύση, το χρώμα και η ηλικία. Το PCA μπορεί να χρησιμοποιηθεί για να συνδυάσει πιο συγκεκριμένα χαρακτηριστικά και να δημιουργήσει λειτουργίες που είναι πιο γενικές, χρήσιμες και λιγότερο πιθανό να προκαλέσουν υπερπροσαρμογή.
Το PCA πραγματοποιείται προσδιορίζοντας πώς τα χαρακτηριστικά εισόδου ποικίλλουν από τη μέση τιμή μεταξύ τους, προσδιορίζοντας εάν υπάρχουν σχέσεις μεταξύ των χαρακτηριστικών. Για να γίνει αυτό, δημιουργείται ένας πίνακας συμμεταβλητών, ο οποίος δημιουργεί έναν πίνακα που αποτελείται από τις συνδιακυμάνσεις σε σχέση με τα πιθανά ζεύγη των χαρακτηριστικών του συνόλου δεδομένων. Αυτό χρησιμοποιείται για τον προσδιορισμό των συσχετίσεων μεταξύ των μεταβλητών, με μια αρνητική συνδιακύμανση να υποδηλώνει αντίστροφη συσχέτιση και μια θετική συσχέτιση που υποδεικνύει μια θετική συσχέτιση.
Τα κύρια (με τη μεγαλύτερη επιρροή) στοιχεία του συνόλου δεδομένων δημιουργούνται με τη δημιουργία γραμμικών συνδυασμών των αρχικών μεταβλητών, που γίνεται με τη βοήθεια εννοιών γραμμικής άλγεβρας που ονομάζονται ιδιοτιμές και ιδιοδιανύσματα. Οι συνδυασμοί δημιουργούνται έτσι ώστε τα κύρια συστατικά να μην συσχετίζονται μεταξύ τους. Οι περισσότερες από τις πληροφορίες που περιέχονται στις αρχικές μεταβλητές συμπιέζονται στα πρώτα βασικά στοιχεία, που σημαίνει ότι έχουν δημιουργηθεί νέα χαρακτηριστικά (τα κύρια στοιχεία) που περιέχουν τις πληροφορίες από το αρχικό σύνολο δεδομένων σε μικρότερο διαστατικό χώρο.
Μοναδική Αποσύνθεση Αξίας
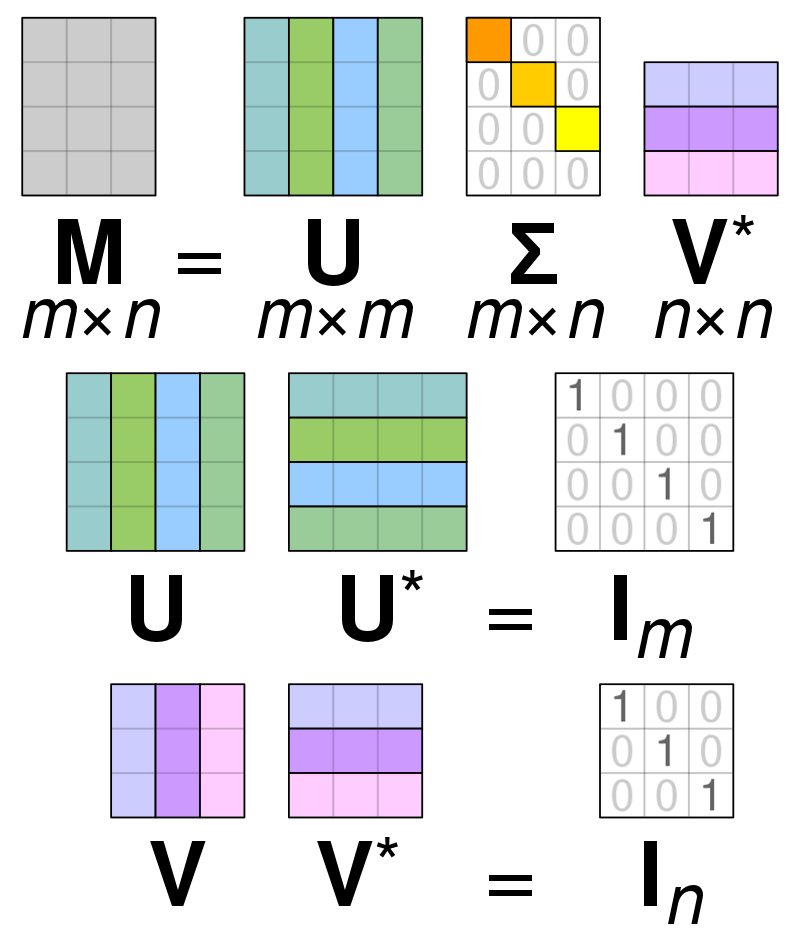
Φωτογραφία: By Cmglee – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Αποσύνθεση μοναδικής τιμής (SVD) is χρησιμοποιείται για την απλοποίηση των τιμών μέσα σε έναν πίνακα, μειώνοντας τον πίνακα στα συστατικά του μέρη και διευκολύνοντας τους υπολογισμούς με αυτόν τον πίνακα. Το SVD μπορεί να χρησιμοποιηθεί τόσο για πίνακες πραγματικής αξίας όσο και για μιγαδικούς πίνακες, αλλά για τους σκοπούς αυτής της εξήγησης, θα εξετάσει πώς να αποσυντεθεί ένας πίνακας πραγματικών τιμών.
Ας υποθέσουμε ότι έχουμε έναν πίνακα που αποτελείται από δεδομένα πραγματικής αξίας και στόχος μας είναι να μειώσουμε τον αριθμό των στηλών/χαρακτηριστικών εντός του πίνακα, παρόμοια με τον στόχο του PCA. Όπως το PCA, το SVD θα συμπιέσει τη διάσταση του πίνακα διατηρώντας όσο το δυνατόν μεγαλύτερη μεταβλητότητα του πίνακα. Εάν θέλουμε να λειτουργήσουμε στον πίνακα A, μπορούμε να αναπαραστήσουμε τον πίνακα A ως τρεις άλλους πίνακες που ονομάζονται U, D, & V. Ο πίνακας A αποτελείται από τα αρχικά στοιχεία x * y ενώ ο πίνακας U αποτελείται από στοιχεία X * X (είναι μια ορθογώνια μήτρα). Ο πίνακας V είναι ένας διαφορετικός ορθογώνιος πίνακας που περιέχει στοιχεία y * y. Ο πίνακας D περιέχει τα στοιχεία x * y και είναι ένας διαγώνιος πίνακας.
Προκειμένου να αποσυνθέσουμε τις τιμές για τον πίνακα A, πρέπει να μετατρέψουμε τις αρχικές τιμές του μοναδικού πίνακα στις διαγώνιες τιμές που βρίσκονται σε έναν νέο πίνακα. Όταν εργάζεστε με ορθογώνιους πίνακες, οι ιδιότητές τους δεν αλλάζουν εάν πολλαπλασιαστούν με άλλους αριθμούς. Επομένως, μπορούμε να προσεγγίσουμε τον πίνακα Α εκμεταλλευόμενοι αυτήν την ιδιότητα. Όταν πολλαπλασιάζουμε τους ορθογώνιους πίνακες μαζί με μια μετάθεση του πίνακα V, το αποτέλεσμα είναι ένας ισοδύναμος πίνακας με τον αρχικό μας A.
Όταν ο πίνακας a αποσυντίθεται σε πίνακες U, D και V, περιέχουν τα δεδομένα που βρίσκονται μέσα στον πίνακα A. Ωστόσο, οι πιο αριστερές στήλες των πινάκων θα κρατούν την πλειοψηφία των δεδομένων. Μπορούμε να πάρουμε μόνο αυτές τις πρώτες στήλες και να έχουμε μια αναπαράσταση του Matrix A που έχει πολύ λιγότερες διαστάσεις και τα περισσότερα δεδομένα εντός του A.
Γραμμική Διακριτική Ανάλυση

Αριστερά: Matrix πριν από το LDA, Δεξιά: Άξονας μετά το LDA, τώρα διαχωρίσιμο
Γραμμική ανάλυση διακρίσεων (LDA) είναι μια διαδικασία που λαμβάνει δεδομένα από ένα πολυδιάστατο γράφημα και το επαναπροβάλλει σε γραμμικό γράφημα. Μπορείτε να το οραματιστείτε αυτό λαμβάνοντας υπόψη ένα δισδιάστατο γράφημα γεμάτο με σημεία δεδομένων που ανήκουν σε δύο διαφορετικές κατηγορίες. Ας υποθέσουμε ότι τα σημεία είναι διάσπαρτα γύρω, έτσι ώστε να μην μπορεί να τραβηχτεί καμία γραμμή που θα χωρίζει τις δύο διαφορετικές κατηγορίες. Για να χειριστεί αυτή την κατάσταση, τα σημεία που βρίσκονται στο δισδιάστατο γράφημα μπορούν να μειωθούν σε ένα γράφημα 2D (γραμμή). Αυτή η γραμμή θα έχει όλα τα σημεία δεδομένων κατανεμημένα σε αυτήν και ελπίζουμε ότι μπορεί να χωριστεί σε δύο τμήματα που αντιπροσωπεύουν τον καλύτερο δυνατό διαχωρισμό των δεδομένων.
Κατά την εκτέλεση της LDA υπάρχουν δύο πρωταρχικοί στόχοι. Ο πρώτος στόχος είναι η ελαχιστοποίηση της διακύμανσης για τις τάξεις, ενώ ο δεύτερος στόχος είναι η μεγιστοποίηση της απόστασης μεταξύ των μέσων των δύο τάξεων. Αυτοί οι στόχοι επιτυγχάνονται με τη δημιουργία ενός νέου άξονα που θα υπάρχει στο 2D γράφημα. Ο άξονας που δημιουργήθηκε πρόσφατα ενεργεί για να διαχωρίσει τις δύο τάξεις με βάση τους στόχους που περιγράφηκαν προηγουμένως. Αφού δημιουργηθεί ο άξονας, τα σημεία που βρίσκονται στο δισδιάστατο γράφημα τοποθετούνται κατά μήκος του άξονα.
Απαιτούνται τρία βήματα για να μετακινήσετε τα αρχικά σημεία σε μια νέα θέση κατά μήκος του νέου άξονα. Στο πρώτο βήμα, η απόσταση μεταξύ των μέσων των επιμέρους κλάσεων (η διακύμανση μεταξύ των κλάσεων) χρησιμοποιείται για τον υπολογισμό της διαχωρισιμότητας των κλάσεων. Στο δεύτερο βήμα, υπολογίζεται η διακύμανση εντός των διαφορετικών κλάσεων, προσδιορίζοντας την απόσταση μεταξύ του δείγματος και του μέσου όρου για την εν λόγω κατηγορία. Στο τελικό βήμα, δημιουργείται ο χώρος χαμηλότερης διάστασης που μεγιστοποιεί τη διακύμανση μεταξύ των κλάσεων.
Η τεχνική LDA επιτυγχάνει τα καλύτερα αποτελέσματα όταν τα μέσα για τις κατηγορίες-στόχους απέχουν πολύ μεταξύ τους. Το LDA δεν μπορεί να διαχωρίσει αποτελεσματικά τις κλάσεις με έναν γραμμικό άξονα εάν τα μέσα για τις κατανομές αλληλοεπικαλύπτονται.










