
AI 101
Τι είναι το Overfitting;
Τι είναι το Overfitting;
Όταν εκπαιδεύετε ένα νευρωνικό δίκτυο, πρέπει να αποφύγετε την υπερβολική προσαρμογή. Υπερβολική τοποθέτηση είναι ένα ζήτημα στη μηχανική μάθηση και στα στατιστικά στοιχεία όπου ένα μοντέλο μαθαίνει πολύ καλά τα πρότυπα ενός συνόλου δεδομένων εκπαίδευσης, εξηγώντας τέλεια το σύνολο δεδομένων εκπαίδευσης, αλλά αποτυγχάνοντας να γενικεύσει την προγνωστική του ισχύ σε άλλα σύνολα δεδομένων.
Για να το θέσουμε διαφορετικά, στην περίπτωση ενός υπερπροσαρμοσμένου μοντέλου θα δείχνει συχνά εξαιρετικά υψηλή ακρίβεια στο σύνολο δεδομένων εκπαίδευσης αλλά χαμηλή ακρίβεια στα δεδομένα που συλλέγονται και εκτελούνται μέσω του μοντέλου στο μέλλον. Αυτός είναι ένας γρήγορος ορισμός της υπερπροσαρμογής, αλλά ας εξετάσουμε την έννοια της υπερπροσαρμογής με περισσότερες λεπτομέρειες. Ας ρίξουμε μια ματιά στο πώς συμβαίνει η υπερβολική προσαρμογή και πώς μπορεί να αποφευχθεί.
Κατανόηση του «Fit» και του Underfitting
Είναι χρήσιμο να ρίξουμε μια ματιά στην έννοια της υποπροσαρμογής και «ταιριάζουν” γενικά όταν συζητάμε για υπερπροσαρμογή. Όταν εκπαιδεύουμε ένα μοντέλο, προσπαθούμε να αναπτύξουμε ένα πλαίσιο που να είναι ικανό να προβλέψει τη φύση ή την κατηγορία στοιχείων σε ένα σύνολο δεδομένων, με βάση τα χαρακτηριστικά που περιγράφουν αυτά τα στοιχεία. Ένα μοντέλο θα πρέπει να μπορεί να εξηγεί ένα μοτίβο μέσα σε ένα σύνολο δεδομένων και να προβλέπει τις κατηγορίες μελλοντικών σημείων δεδομένων με βάση αυτό το μοτίβο. Όσο καλύτερα το μοντέλο εξηγεί τη σχέση μεταξύ των χαρακτηριστικών του προπονητικού σετ, τόσο πιο «ταιριασμένο» είναι το μοντέλο μας.
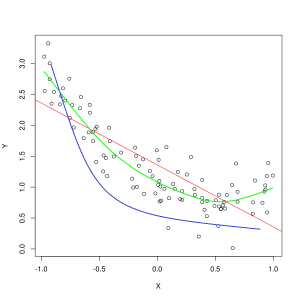
Η μπλε γραμμή αντιπροσωπεύει προβλέψεις από ένα μοντέλο που δεν ταιριάζει, ενώ η πράσινη γραμμή αντιπροσωπεύει ένα μοντέλο που ταιριάζει καλύτερα. Φωτογραφία: Pep Roca μέσω Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Ένα μοντέλο που εξηγεί ανεπαρκώς τη σχέση μεταξύ των χαρακτηριστικών των δεδομένων εκπαίδευσης και επομένως αποτυγχάνει να ταξινομήσει με ακρίβεια μελλοντικά παραδείγματα δεδομένων είναι υποσυναρμολόγηση τα δεδομένα της εκπαίδευσης. Εάν σχεδιάζατε τη γραφική παράσταση της προβλεπόμενης σχέσης ενός μοντέλου που δεν ταιριάζει με την πραγματική τομή των χαρακτηριστικών και των ετικετών, οι προβλέψεις θα αποκλίνουν από το σημάδι. Εάν είχαμε ένα γράφημα με επισημασμένο τις πραγματικές τιμές ενός συνόλου εκπαίδευσης, ένα μοντέλο που δεν προσαρμόζεται σοβαρά θα έχανε δραστικά τα περισσότερα από τα σημεία δεδομένων. Ένα μοντέλο με καλύτερη προσαρμογή μπορεί να κόψει μια διαδρομή μέσα από το κέντρο των σημείων δεδομένων, με τα μεμονωμένα σημεία δεδομένων να είναι ελάχιστα μακριά από τις προβλεπόμενες τιμές.
Η υποπροσαρμογή μπορεί συχνά να συμβεί όταν δεν υπάρχουν επαρκή δεδομένα για τη δημιουργία ενός ακριβούς μοντέλου ή όταν προσπαθείτε να σχεδιάσετε ένα γραμμικό μοντέλο με μη γραμμικά δεδομένα. Περισσότερα δεδομένα προπόνησης ή περισσότερες δυνατότητες θα βοηθήσουν συχνά στη μείωση της υποπροσαρμογής.
Γιατί λοιπόν να μην δημιουργήσουμε απλώς ένα μοντέλο που να εξηγεί τέλεια κάθε σημείο των δεδομένων εκπαίδευσης; Σίγουρα η τέλεια ακρίβεια είναι επιθυμητή; Η δημιουργία ενός μοντέλου που έχει μάθει πολύ καλά τα μοτίβα των δεδομένων εκπαίδευσης είναι αυτό που προκαλεί την υπερβολική προσαρμογή. Το σύνολο δεδομένων εκπαίδευσης και άλλα, μελλοντικά σύνολα δεδομένων που εκτελείτε μέσω του μοντέλου δεν θα είναι ακριβώς τα ίδια. Πιθανότατα θα μοιάζουν πολύ από πολλές απόψεις, αλλά θα διαφέρουν επίσης σε βασικούς τρόπους. Επομένως, ο σχεδιασμός ενός μοντέλου που εξηγεί τέλεια το σύνολο δεδομένων εκπαίδευσης σημαίνει ότι καταλήγετε σε μια θεωρία σχετικά με τη σχέση μεταξύ των χαρακτηριστικών που δεν γενικεύεται καλά σε άλλα σύνολα δεδομένων.
Κατανόηση της υπερπροσαρμογής
Η υπερπροσαρμογή συμβαίνει όταν ένα μοντέλο μαθαίνει πολύ καλά τις λεπτομέρειες μέσα στο σύνολο δεδομένων εκπαίδευσης, με αποτέλεσμα το μοντέλο να υποφέρει όταν γίνονται προβλέψεις για εξωτερικά δεδομένα. Αυτό μπορεί να συμβεί όταν το μοντέλο όχι μόνο μαθαίνει τα χαρακτηριστικά του συνόλου δεδομένων, μαθαίνει επίσης και τυχαίες διακυμάνσεις ή θόρυβος μέσα στο σύνολο δεδομένων, δίνοντας σημασία σε αυτά τα τυχαία/ασήμαντα περιστατικά.
Η υπερπροσαρμογή είναι πιο πιθανό να συμβεί όταν χρησιμοποιούνται μη γραμμικά μοντέλα, καθώς είναι πιο ευέλικτα κατά την εκμάθηση χαρακτηριστικών δεδομένων. Οι μη παραμετρικοί αλγόριθμοι μηχανικής μάθησης έχουν συχνά διάφορες παραμέτρους και τεχνικές που μπορούν να εφαρμοστούν για να περιοριστεί η ευαισθησία του μοντέλου στα δεδομένα και έτσι να μειωθεί η υπερπροσαρμογή. Ως παράδειγμα, μοντέλα δέντρων αποφάσεων είναι πολύ ευαίσθητα στην υπερβολική προσαρμογή, αλλά μια τεχνική που ονομάζεται κλάδεμα μπορεί να χρησιμοποιηθεί για να αφαιρέσετε τυχαία ορισμένες από τις λεπτομέρειες που έχει μάθει το μοντέλο.
Εάν σχεδιάζατε τις προβλέψεις του μοντέλου στους άξονες X και Y, θα είχατε μια γραμμή πρόβλεψης που κάνει ζιγκ-ζαγκ εμπρός και πίσω, κάτι που αντικατοπτρίζει το γεγονός ότι το μοντέλο προσπάθησε πάρα πολύ να χωρέσει όλα τα σημεία του συνόλου δεδομένων σε η εξήγησή του.
Έλεγχος υπερπροσαρμογής
Όταν εκπαιδεύουμε ένα μοντέλο, ιδανικά θέλουμε το μοντέλο να μην κάνει λάθη. Όταν η απόδοση του μοντέλου συγκλίνει προς την πραγματοποίηση σωστών προβλέψεων σε όλα τα σημεία δεδομένων στο σύνολο δεδομένων εκπαίδευσης, η προσαρμογή γίνεται καλύτερη. Ένα μοντέλο με καλή εφαρμογή είναι σε θέση να εξηγήσει σχεδόν όλο το σύνολο δεδομένων εκπαίδευσης χωρίς υπερβολική προσαρμογή.
Καθώς ένα μοντέλο προπονείται, η απόδοσή του βελτιώνεται με την πάροδο του χρόνου. Το ποσοστό σφάλματος του μοντέλου θα μειώνεται καθώς περνά ο χρόνος εκπαίδευσης, αλλά μειώνεται μόνο σε ένα ορισμένο σημείο. Το σημείο στο οποίο η απόδοση του μοντέλου στο σετ δοκιμής αρχίζει να αυξάνεται ξανά είναι συνήθως το σημείο στο οποίο συμβαίνει η υπερπροσαρμογή. Προκειμένου να πετύχουμε την καλύτερη εφαρμογή για ένα μοντέλο, θέλουμε να σταματήσουμε να εκπαιδεύουμε το μοντέλο στο σημείο της χαμηλότερης απώλειας στο σετ εκπαίδευσης, προτού το σφάλμα αρχίσει να αυξάνεται ξανά. Το βέλτιστο σημείο στάσης μπορεί να εξακριβωθεί με τη γραφική παράσταση της απόδοσης του μοντέλου καθ' όλη τη διάρκεια της προπόνησης και τη διακοπή της προπόνησης όταν η απώλεια είναι η μικρότερη. Ωστόσο, ένας κίνδυνος με αυτήν τη μέθοδο ελέγχου της υπερπροσαρμογής είναι ότι ο καθορισμός του τελικού σημείου για την εκπαίδευση με βάση την απόδοση της δοκιμής σημαίνει ότι τα δεδομένα της δοκιμής περιλαμβάνονται κάπως στη διαδικασία εκπαίδευσης και χάνουν την κατάστασή τους ως καθαρά «άθικτα» δεδομένα.
Υπάρχουν μερικοί διαφορετικοί τρόποι με τους οποίους μπορεί κανείς να καταπολεμήσει την υπερβολική τοποθέτηση. Μια μέθοδος μείωσης της υπερπροσαρμογής είναι η χρήση μιας τακτικής επαναδειγματοληψίας, η οποία λειτουργεί με την εκτίμηση της ακρίβειας του μοντέλου. Μπορείτε επίσης να χρησιμοποιήσετε α επικύρωση σύνολο δεδομένων εκτός από το σύνολο δοκιμής και σχεδιάστε την ακρίβεια εκπαίδευσης έναντι του συνόλου επικύρωσης αντί για το σύνολο δεδομένων δοκιμής. Αυτό διατηρεί το δοκιμαστικό σας σύνολο αόρατο. Μια δημοφιλής μέθοδος επαναδειγματοληψίας είναι η διασταυρούμενη επικύρωση με πτυχές K. Αυτή η τεχνική σάς δίνει τη δυνατότητα να διαιρέσετε τα δεδομένα σας σε υποσύνολα στα οποία έχει εκπαιδευτεί το μοντέλο και στη συνέχεια αναλύεται η απόδοση του μοντέλου στα υποσύνολα για να εκτιμηθεί η απόδοση του μοντέλου σε εξωτερικά δεδομένα.
Η χρήση της διασταυρούμενης επικύρωσης είναι ένας από τους καλύτερους τρόπους εκτίμησης της ακρίβειας ενός μοντέλου σε μη ορατά δεδομένα και, όταν συνδυάζεται με ένα σύνολο δεδομένων επικύρωσης, η υπερβολική προσαρμογή μπορεί συχνά να περιοριστεί στο ελάχιστο.










