Τεχνητή νοημοσύνη 101
Τι είναι ένα Δέντρο Απόφασης;
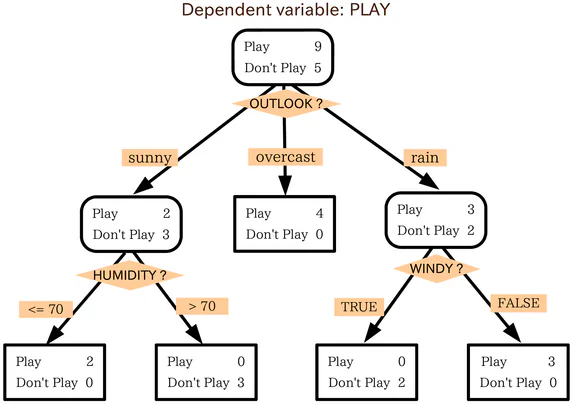
Τι είναι ένα Δέντρο Απόφασης;
Ένα δέντρο απόφασης είναι ένα χρήσιμο αλγόριθμο μηχανικής μάθησης που χρησιμοποιείται για καθήκοντα ταξινόμησης και回귀σης. Το όνομα «δέντρο απόφασης» προέρχεται από το γεγονός ότι ο αλγόριθμος συνεχίζει να χωρίζει το σύνολο δεδομένων σε μικρότερα και μικρότερα τμήματα μέχρι τα δεδομένα να έχουν χωριστεί σε μεμονωμένες περιπτώσεις, οι οποίες στη συνέχεια ταξινομούνται. Αν οραματιστήκατε τα αποτελέσματα του αλγορίθμου, ο τρόπος με τον οποίο οι κατηγορίες χωρίζονται θα έμοιαζε με ένα δέντρο και πολλά φύλλα.
Αυτή είναι μια γρήγορη ορισμός ενός δέντρου απόφασης, αλλά ας κάνουμε einen βαθύερη έρευνα για το πώς λειτουργούν τα δέντρα απόφασης. Έχοντας μια καλύτερη κατανόηση του πώς λειτουργούν τα δέντρα απόφασης, καθώς και των περιπτώσεων χρήσης τους, θα σας βοηθήσει να γνωρίζετε πότε να τα χρησιμοποιείτε κατά τη διάρκεια των έργων μηχανικής μάθησης.
Μορφή ενός Δέντρου Απόφασης
Ένα δέντρο απόφασης είναι πολύ σαν ένα διαγράμμα ροής. Για να χρησιμοποιήσετε ένα διαγράμμα ροής, ξεκινάτε από το σημείο εκκίνησης ή την ρίζα του διαγράμματος και στη συνέχεια, με βάση το πώς απαντάτε στα κριτήρια φιλτραρίσματος του αρχικού κόμβου, μεταφέρεστε σε έναν από τους επόμενους πιθανούς κόμβους. Αυτή η διαδικασία επαναλαμβάνεται μέχρι να φθάσετε σε ένα τέλος.
Τα δέντρα απόφασης λειτουργούν ουσιαστικά με τον ίδιο τρόπο, με κάθε εσωτερικό κόμβο στο δέντρο να είναι κάποιο είδος δοκιμής/κριτηρίου φιλτραρίσματος. Οι κόμβοι στην εξωτερική πλευρά, τα τελικά σημεία του δέντρου, είναι οι ετικέτες για το δεδομένο σημείο και ονομάζονται «φύλλα». Οι κλάδοι που οδηγούν από τους εσωτερικούς κόμβους στον επόμενο κόμβο είναι χαρακτηριστικά ή συνδυασμοί χαρακτηριστικών. Οι κανόνες που χρησιμοποιούνται για την ταξινόμηση των δεδομένων είναι οι διαδρομές που τρέχουν από τη ρίζα στα φύλλα.

Αλγόριθμοι για Δέντρα Απόφασης
Τα δέντρα απόφασης λειτουργούν με μια αλγοριθμική προσέγγιση που χωρίζει το σύνολο δεδομένων σε μεμονωμένα δεδομένα με βάση διαφορετικά κριτήρια. Αυτά τα διαχωρισμοί γίνονται με διαφορετικές μεταβλητές ή τα διαφορετικά χαρακτηριστικά του συνόλου δεδομένων. Για παράδειγμα, αν ο στόχος είναι να καθορίσετε αν περιγράφεται ένας σκύλος ή μια γάτα από τα εισαγόμενα χαρακτηριστικά, μεταβλητές που τα δεδομένα χωρίζονται μπορεί να είναι πράγματα όπως «νύχια» και «γάβγισμα».
Τι αλγόριθμοι χρησιμοποιούνται για να χωρίσουν τα δεδομένα σε κλάδους και φύλλα; Υπάρχουν διάφοροι μέθοδοι που μπορούν να χρησιμοποιηθούν για να χωρίσουν ένα δέντρο, αλλά η πιο συνηθισμένη μέθοδος διαχωρισμού είναι πιθανώς μια τεχνική που ονομάζεται «αναδρομικός δυαδικός διαχωρισμός». Όταν πραγματοποιείται αυτή η μέθοδος διαχωρισμού, η διαδικασία ξεκινά από τη ρίζα και ο αριθμός των χαρακτηριστικών του συνόλου δεδομένων αντιπροσωπεύει τον πιθανό αριθμό πιθανών διαχωρισμών. Μια συνάρτηση χρησιμοποιείται για να καθορίσει πόση ακρίβεια κάθε πιθανός διαχωρισμός θα κοστίσει και ο διαχωρισμός γίνεται χρησιμοποιώντας τα κριτήρια που θυσιάζουν την ελάχιστη ακρίβεια. Αυτή η διαδικασία πραγματοποιείται αναδρομικά και υποομάδες σχηματίζονται χρησιμοποιώντας την ίδια γενική στρατηγική.
Για να καθορίσετε το κόστος του διαχωρισμού, χρησιμοποιείται μια συνάρτηση κόστους. Μια διαφορετική συνάρτηση κόστους χρησιμοποιείται για καθήκοντα回귀σης και ταξινόμησης. Ο στόχος και των δύο συναρτήσεων κόστους είναι να καθορίσει ποιοι κλάδοι έχουν τις πιο相似的 απαντήσεις ή τους πιο ομοιογενείς κλάδους. Υποθέστε ότι θέλετε τα δεδομένα δοκιμής μιας συγκεκριμένης κατηγορίας να ακολουθούν συγκεκριμένες διαδρομές και αυτό έχει εννοιολογική σημασία.
Σχετικά με τη συνάρτηση κόστους για την回귀ση, ο αλγόριθμος που χρησιμοποιείται για να υπολογίσει το κόστος είναι ο ακόλουθος:
sum(y – prediction)^2
Η πρόβλεψη για μια συγκεκριμένη ομάδα δεδομένων είναι το μέσο των απαντήσεων των δεδομένων εκπαίδευσης για αυτή την ομάδα. Όλα τα δεδομένα περνούν από τη συνάρτηση κόστους για να καθορίσει το κόστος για όλους τους πιθανούς διαχωρισμούς και ο διαχωρισμός με το χαμηλότερο κόστος επιλέγεται.
Σχετικά με τη συνάρτηση κόστους για την ταξινόμηση, η συνάρτηση είναι η ακόλουθη:
G = sum(pk * (1 – pk))
Αυτή είναι η βαθμολογία Gini, και είναι ένα μέτρο της αποτελεσματικότητας ενός διαχωρισμού, με βάση τον αριθμό των περιπτώσεων διαφορετικών κατηγοριών στις ομάδες που προκύπτουν από τον διαχωρισμό. Με άλλα λόγια, ποσοτικοποιεί πόσο μεικτές είναι οι ομάδες μετά τον διαχωρισμό. Ένας ιδανικός διαχωρισμός είναι όταν όλες οι ομάδες που προκύπτουν από τον διαχωρισμό αποτελούνται μόνο από εισαγωγές από μια κατηγορία. Αν έχει δημιουργηθεί ένας ιδανικός διαχωρισμός, η τιμή «pk» θα είναι είτε 0 είτε 1 και G θα είναι ίσο με 0. Μπορείτε να μαντέψετε ότι ο χειρότερος διαχωρισμός είναι ένας όπου υπάρχει μια αναλογία 50-50 των κατηγοριών στον διαχωρισμό, στην περίπτωση της δυαδικής ταξινόμησης. Σε αυτή την περίπτωση, η τιμή «pk» θα είναι 0,5 και G θα είναι επίσης 0,5.
Η διαδικασία διαχωρισμού τερματίζεται όταν όλα τα δεδομένα έχουν μετατραπεί σε φύλλα και ταξινομηθεί. Ωστόσο, μπορείτε να θέλετε να σταματήσετε την ανάπτυξη του δέντρου νωρίς. Μεγάλα και σύνθετα δέντρα είναι ευάλωτα σε υπερπροσαρμογή, αλλά υπάρχουν διάφορες μέθοδοι που μπορούν να χρησιμοποιηθούν για να καταπολεμήσουν αυτό. Μια μέθοδος για την μείωση της υπερπροσαρμογής είναι να ορίσετε einen ελάχιστο αριθμό δεδομένων που θα χρησιμοποιηθούν για να δημιουργηθεί ένα φύλλο. Μια άλλη μέθοδος για τον έλεγχο της υπερπροσαρμογής είναι η περιορισμός του δέντρου σε ένα συγκεκριμένο μέγιστο βάθος, το οποίο ελέγχει πόσο μακρύ μπορεί να είναι ένας δρόμος από τη ρίζα σε ένα φύλλο.
Μια άλλη διαδικασία που εμπλέκεται στη δημιουργία δέντρων απόφασης είναι η κοπή. Η κοπή μπορεί να βοηθήσει στην αύξηση της απόδοσης ενός δέντρου απόφασης με την αφαίρεση κλάδων που περιέχουν χαρακτηριστικά με μικρή προβλεπτική δύναμη/μικρή σημασία για το μοντέλο. Με αυτόν τον τρόπο, η πολυπλοκότητα του δέντρου μειώνεται, γίνεται λιγότερο πιθανό να υπερπροσαρμοστεί και η προβλεπτική उपयσιμότητα του μοντέλου αυξάνεται.
Όταν πραγματοποιείται η κοπή, η διαδικασία μπορεί να ξεκινήσει είτε από την κορυφή του δέντρου είτε από την βάση του δέντρου. Ωστόσο, η πιο εύκολη μέθοδος κοπής είναι να ξεκινήσετε από τα φύλλα και να προσπαθήσετε να αφαιρέσετε τον κόμβο που περιέχει την πιο συχνή κατηγορία μέσα σε αυτό το φύλλο. Αν η ακρίβεια του μοντέλου δεν επιβαρύνεται όταν γίνεται αυτό, τότε η αλλαγή διατηρείται. Υπάρχουν άλλες τεχνικές που χρησιμοποιούνται για την κοπή, αλλά η μέθοδος που περιγράφηκε παραπάνω – κοπή με μειωμένο σφάλμα – είναι πιθανώς η πιο συνηθισμένη μέθοδος κοπής δέντρων απόφασης.
Συζητήσεις για τη Χρήση Δέντρων Απόφασης
Τα δέντρα απόφασης είναι συχνά χρήσιμα όταν πρέπει να πραγματοποιηθεί ταξινόμηση αλλά ο χρόνος υπολογισμού είναι ένας σημαντικός περιορισμός. Τα δέντρα απόφασης μπορούν να κάνουν φανερό ποια χαρακτηριστικά στο επιλεγμένο σύνολο δεδομένων έχουν την περισσότερη προβλεπτική δύναμη. Επιπλέον, αντίθετα με πολλούς αλγόριθμους μηχανικής μάθησης όπου οι κανόνες που χρησιμοποιούνται για την ταξινόμηση των δεδομένων μπορεί να είναι δύσκολο να ερμηνευτούν, τα δέντρα απόφασης μπορούν να παράγουν ερμηνεύσιμους κανόνες. Τα δέντρα απόφασης μπορούν επίσης να χρησιμοποιήσουν και κατηγορικές και συνεχείς μεταβλητές, που σημαίνει ότι απαιτείται λιγότερη προεπεξεργασία, σε σύγκριση με αλγόριθμους που μπορούν να χειριστούν μόνο ένα από αυτά τα είδη μεταβλητών.
Τα δέντρα απόφασης δεν λειτουργούν πολύ καλά όταν χρησιμοποιούνται για να καθορίσουν τις τιμές συνεχών χαρακτηριστικών. Một περιορισμός των δέντρων απόφασης είναι ότι, όταν πραγματοποιείται ταξινόμηση, αν υπάρχουν λίγα παραδείγματα εκπαίδευσης αλλά πολλές κατηγορίες, το δέντρο απόφασης τείνει να είναι ανακριβές.








