AI 101
Hvad er CNN’er (Convolutionelle Neurale Netværk)?
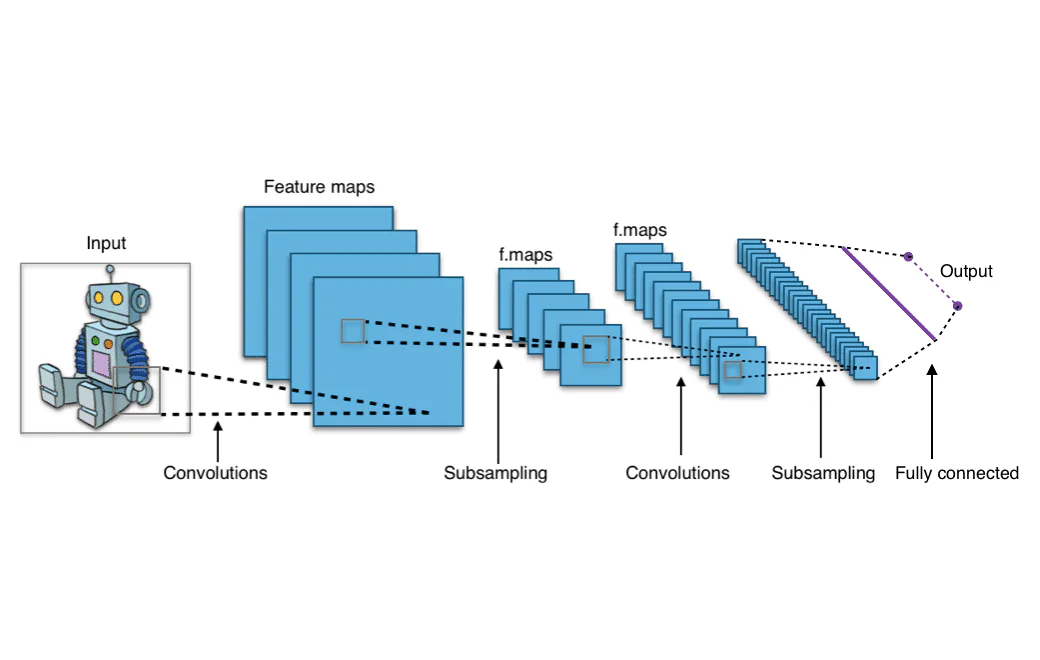
Måske har du undret dig over, hvordan Facebook eller Instagram kan automatisk genkende ansigter på et billede, eller hvordan Google kan lade dig søge på webben efter lignende billeder ved blot at uploade et billede af din egen. Disse funktioner er eksempler på computer vision, og de drives af convolutionelle neurale netværk (CNN’er). Men hvad er convolutionelle neurale netværk egentlig? Lad os dykke dybt ind i arkitekturen af et CNN og forstå, hvordan de fungerer.
Hvad er Neurale Netværk?
Før vi begynder at tale om convolutionelle neurale netværk, lad os tage et øjeblik til at definere et almindeligt neuralt netværk. Der er en anden artikel på dette emne, så vi vil ikke gå for dybt ind i det her. Men for at definere det kort er de computermæssige modeller inspireret af det menneskelige hjerte. Et neuralt netværk fungerer ved at tage imod data og manipulere data ved at justere “vægte”, som er antagelser om, hvordan inputfunktionerne er relateret til hinanden og objektets klasse. Da netværket trænes, bliver værdierne af vægtene justeret, og de vil håbefuldt konvergere på vægte, der nøjagtigt fanger relationerne mellem funktionerne.
Dette er, hvordan et feed-forward neuralt netværk fungerer, og CNN’er består af to halvdele: et feed-forward neuralt netværk og en gruppe convolutionelle lag.
Hvad er Convolutionelle Neurale Netværk (CNN’er)?
Hvad er de “konvolutioner”, der sker i et convolutionelt neuralt netværk? En konvolution er en matematisk operation, der opretter en sæt af vægte, som grundlæggende opretter en repræsentation af dele af billedet. Dette sæt af vægte kaldes en kernel eller filter. Filtreren, der oprettes, er mindre end det hele inputbillede, og dækker kun en undersektion af billedet. Værdierne i filtreren bliver multipliceret med værdierne i billedet. Filtreren bliver herefter flyttet hen for at danne en repræsentation af en ny del af billedet, og processen gentages, indtil hele billedet er dækket.
En anden måde at tænke over dette er at forestille sig en mur af mursten, hvor murstenene repræsenterer pixelerne i inputbilledet. Et “vindue” bliver flyttet frem og tilbage langs muren, som er filtreren. Murstenene, der kan ses gennem vinduet, er pixelerne, der får deres værdi multipliceret med værdierne i filtreren. Af denne grund kaldes denne metode til at oprette vægte med en filter ofte for “sliding windows”-teknikken.
Udgangen fra filtrerne, der flyttes rundt på hele inputbilledet, er en todimensionel array, der repræsenterer hele billedet. Denne array kaldes en “feature map”.
Hvorfor er Konvolutioner Essentielle
Hvad er formålet med at oprette konvolutioner overhovedet? Konvolutioner er nødvendige, fordi et neuralt netværk skal kunne fortolke pixelerne i et billede som numeriske værdier. Funktionen af de convolutionelle lag er at konvertere billedet til numeriske værdier, som det neurale netværk kan fortolke og derefter trække relevante mønstre ud af. Jobbet med filtrerne i det convolutionelle netværk er at oprette en todimensionel array af værdier, der kan overføres til de senere lag af et neuralt netværk, som vil lære mønstrene i billedet.
Filtre og Kanaler
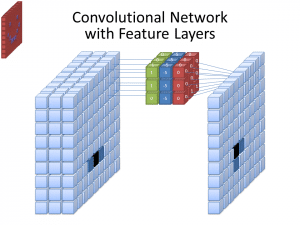
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN’er bruger ikke bare ét filter til at lære mønstre fra inputbillederne. Multiple filtre bliver brugt, da de forskellige arrayer, der oprettes af de forskellige filtre, fører til en mere kompleks, rig repræsentation af inputbilledet. Almindelige antal filtre for CNN’er er 32, 64, 128 og 512. Jo flere filtre der er, desto flere muligheder har CNN’en for at undersøge inputdata og lære af det.
En CNN analyserer forskellene i pixelværdier for at bestemme grænserne for objekter. I et gråtonebillede vil CNN’en kun se på forskellene i sort og hvid, lys til mørk. Når billederne er farvebilleder, skal CNN’en ikke kun tage mørk og lys i betragtning, men også de tre forskellige farvekkanaler – rød, grøn og blå. I dette tilfælde har filtrerne 3 kanaler, ligesom billedet selv har. Antallet af kanaler, en filter har, kaldes for dets dybde, og antallet af kanaler i filtreren skal matche antallet af kanaler i billedet.
Convolutionelt Neuralt Netværk (CNN) Arkitektur
Lad os tage et kig på den komplette arkitektur af et convolutionelt neuralt netværk. Et convolutionelt lag findes i begyndelsen af hvert convolutionelt netværk, da det er nødvendigt for at transformere billeddata til numeriske arrayer. Men convolutionelle lag kan også komme efter andre convolutionelle lag, hvilket betyder, at disse lag kan stable på toppen af hinanden. At have multiple convolutionelle lag betyder, at udgangen fra ét lag kan undergå yderligere konvolutioner og blive grupperet sammen i relevante mønstre. I praksis betyder dette, at da billeddataene passerer gennem de convolutionelle lag, begynder netværket at “genkende” mere komplekse funktioner af billedet.
De tidlige lag af et ConvNet er ansvarlige for at trække de lavniveaufunktioner ud, såsom pixelerne, der udgør simple linjer. Senere lag af ConvNet vil samle disse linjer sammen til former. Denne proces med at gå fra overfladeanalyse til dybdeanalyse fortsætter, indtil ConvNet genkender komplekse former som dyr, menneskeansigter og biler.
Efter at dataene er passeret gennem alle de convolutionelle lag, går de ind i den tæt forbundne del af CNN. De tæt forbundne lag er, hvad et traditionelt feed-forward neuralt netværk ligner, en række noder arrangeret i lag, der er forbundet til hinanden. Dataene passerer gennem disse tæt forbundne lag, som lærer mønstrene, der blev trukket ud af de convolutionelle lag, og på den måde bliver netværket i stand til at genkende objekter.










