Artificiell intelligens
MIT: Mätning av mediepartiskhet i stora nyhetskällor med maskinlärande

En studie från MIT har använt maskinlärandetekniker för att identifiera partiskt språkbruk i över 100 av de största och mest inflytelserika nyhetskällorna i USA och utanför, inklusive 83 av de mest inflytelserika tryckta nyhetspublikationerna. Det är ett forskningsarbete som visar vägen mot automatiserade system som potentiellt kan auto-klassificera den politiska karaktären hos en publikation och ge läsarna en djupare insikt i den etiska ståndpunkten hos en utgivare på ämnen som de kan känna starkt för.
Arbetet fokuserar på hur ämnen behandlas med särskilt språkbruk, såsom odokumenterad invandrare | olaglig invandrare, foster | ofödd baby, demonstranter | anarkister.
Projektet använde Natural Language Processing (NLP)-tekniker för att extrahera och klassificera sådana exempel på “laddat” språk (med antagandet att tydligen mer “neutrala” termer också representerar en politisk ståndpunkt) till en bred karta som avslöjar vänster- och högerinriktad partiskhet över tre miljoner artiklar från över 100 nyhetskällor, vilket resulterar i en navigerbar partiskhetslandskap av de publikationer i fråga.
Den artikeln kommer från Samantha D’Alonzo och Max Tegmark vid MIT:s fysikavdelning och observerar att ett antal nyliga initiativ runt “faktakontroll” i kölvattnet av flera “falska nyheter”-skandaler kan tolkas som oärliga och tjäna särskilda intressen. Projektet är tänkt att ge en mer datastyrd approach till att studera användningen av partiskhet och “påverkande” språk i ett förmodat neutralt nyhetskontext.

Ett spektrum av (bokstavligen) vänster-höger-fraser, som härrör från studien. Källa: https://arxiv.org/pdf/2109.00024.pdf
NLP-bearbetning
Källdatan från studien erhölls från den öppna källkoden Newspaper3K-databasen och bestod av 3 078 624 artiklar från 100 medienyhetskällor, inklusive 83 tidningar. Tidningarna valdes utifrån deras räckvidd, medan online-mediekällor också inkluderade artiklar från den militära nyhetsanalyswebbplatsen Defense One och Science.

Källorna som användes i studien.
Artikeln rapporterar att den nedladdade texten “minimalt” förbehandlades. Direkta citat eliminerades, eftersom studien är intresserad av det språk som valts av journalister (även om citatval i sig är ett intressant studieområde).
Brittiska stavningar ändrades till amerikanska för att standardisera databasen, all punktion togs bort och alla utom ordinala tal också togs bort. Initial meningsstorlek konverterades till gemener, men all annan storlek behölls.
De första 100 000 vanligaste fraserna identifierades och slutligen rankades, rensades och sammanslogs till en fraslista. All redundant språk som kunde identifieras (såsom “Dela den här artikeln” och “artikel återpublicerad”) togs också bort. Variationer över i princip identiska fraser (t.ex. “stort tech” och “Big Tech”, “cybersäkerhet” och “cyber säkerhet”) standardiserades.
‘Nutpicking’
Den första testen var på ämnet “Black lives matter” och kunde urskilja fraspartiskhet och valenta synonymer över hela datamängden.
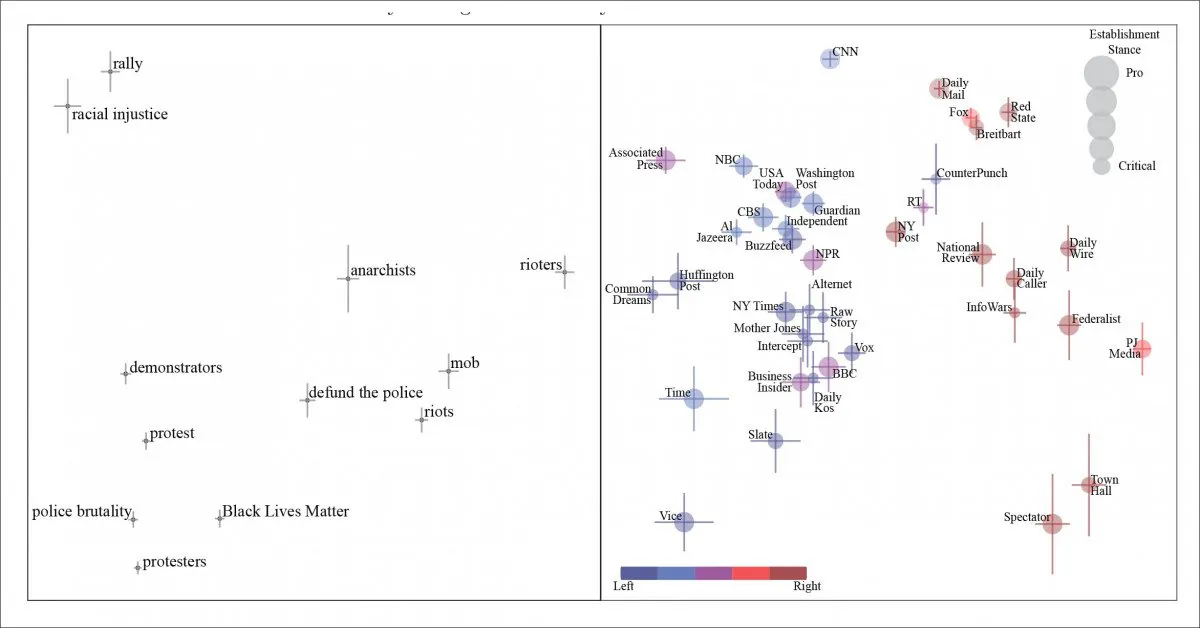
Allmänna principkomponenter för artiklar om Black Lives Matter (BLM). Vi ser människor som deltar i civila åtgärder karakteriserade, bokstavligen och figurativt, från vänster till höger, som demonstranter, anarkister och, i den högersta änden av spektrumet, som ‘kravallmakare’. Tidningarna som gav upphov till frasen representeras i den högra panelen.
Medan ‘protestanter’ övergår från ‘anarkister’ till ‘kravallmakare’ när vi glider längs den politiska ståndpunkten hos utgivaren i fråga, noterar artikeln att NLP-extraktionen och analysen hindras av praktiken att “nutpicking” – där en mediekälla citerar en fras som ses som giltig av en skild politisk sektor av samhället och kan (tydligen) lita på att dess läsarskara ser frasen negativt. Artikeln citerar ‘avskaffa polisen’ som ett exempel på detta.
Detta betyder att en “vänsterinriktad” fras dyker upp i ett annat högerextremt sammanhang och representerar en ovanlig utmaning för ett NLP-system som förlitar sig på kodifierade fraser för att fungera som indikatorer för politiska ståndpunkter.
Sådana fraser är “bi-valenta” , medan vissa andra fraser har en så universellt negativ konnotation (t.ex. “barnamord”) att de alltid representeras som negativa över ett spektrum av utgivare.
Forskningen visar också liknande kartor för “heta” ämnen som abort, tech-censur, USA-invandring och vapenkontroll.
Hobbyhästar
Det finns vissa kontroversiella politiska inriktningar i mediekällor som inte delar sig förutsägbart på detta sätt, såsom ämnet militärutgifter. Artikeln fann att “vänsterinriktade” CNN hamnade bredvid högerinriktade National Review och Fox News på detta ämne.
I allmänhet kan dock den politiska ståndpunkten bestämmas av andra fraser, såsom att föredra frasen “militär-industriell komplex” över den mer högerinriktade “försvarsindustrin”. Resultaten visar att den förra används av etableringskritiska utgivare som Canary och American Conservative, medan den senare används oftare av Fox och CNN.
Forskningen etablerar flera andra övergångar från etableringskritisk till pro-etableringsspråk, inklusive övergången från “skjuten till döds” till den mer passiva “dödandet av”; “fångar som är brottslingar” till “fängslade människor”; och “oljeproducenter” till “stort oljeindustri”.

Valenta synonymer med etableringspartiskhet, från topp till botten.
Forskningen erkänner att utgivare kommer att “svänga bort” från sin baspolitiska ståndpunkt, antingen på ett språkligt plan (såsom användningen av bi-valenta fraser) eller av olika andra motiv. Till exempel publicerar den ärevördiga högerextrema brittiska publikationen The Spectator, som etablerades 1828, ofta och framträdande vänsterinriktade tankeartiklar som gnager mot den allmänna politiska flödet av dess innehåll, antingen av oförvitlighet eller för att periodvis antända dess kärnläsarskara till trafikgenererande kommentarsstormar – en sak som är svår att bedöma och inte en lätt sak för ett maskinlärandesystem som letar efter tydliga och konsekventa token.
Dessa särskilda “hobbyhästar” och tvetydiga användning av “stötande” perspektiv bland enskilda nyhetsorganisationer förvirrar något den vänster-höger-karta som forskningen slutligen erbjuder, men ger en bred indikation av politisk tillhörighet.

Undanhållen betydelse
Även om den daterats den 2 september och publicerats i slutet av augusti 2021, har artikeln fått relativt liten uppmärksamhet. Delvis kan detta bero på att kritisk forskning som riktar sig mot mainstream-media inte sannolikt kommer att mottas entusiastiskt av den; men det kan också bero på att författarna är ovilliga att producera tydliga och entydiga grafer som stratifierar var inflytelserika och kraftfulla mediepublikationer står på olika frågor, tillsammans med aggregerade värden som indikerar i vilken utsträckning en publikation lutar åt vänster eller höger. I själva verket verkar författarna ta smärre för att dämpa den potentiella kontroversiella effekten av resultaten.
Likaså visar den omfattande publicerade datan från projektet frekvensräkningar av incidenter av ord, men verkar vara anonymiserad, vilket gör det svårt att få en tydlig bild av mediepartiskhet över de studerade publikationerna. Utan att operationalisera projektet på något sätt, lämnar detta endast de valda exemplen som presenteras i artikeln.
Senare studier av detta slag skulle möjligtvis vara mer användbara om de också skulle överväga inte bara det språk som används för ämnen, utan om ämnet behandlades alls, eftersom tystnad talar volymer och har i sig en särskild politisk karaktär som ofta talar till mer än bara budgetbegränsningar eller andra praktiska faktorer som kan informera nyhetsurval.
Ändå verkar MIT-studien vara den största av sitt slag hittills och kunde utgöra ramen för framtida klassificeringssystem och till och med sekundära teknologier som t.ex. webbläsartillägg som kan varna läsare för den politiska färgen på den publikation de för närvarande läser.
Bubblor, partiskhet och motreaktion
Dessutom måste det övervägas om sådana system skulle förstärka en av de mest kontroversiella aspekterna av algoritmiska rekommendationssystem – benägenheten att leda en tittare in i miljöer där de aldrig ser en motsatt eller utmanande synvinkel, vilket sannolikt kommer att ytterligare förankra läsarens ståndpunkt på kärnfrågor.
Om en sådan innehållsbubbla är en “säker miljö”, ett hinder för intellektuell tillväxt eller ett skydd mot partiell propaganda, är en värdering – en filosofisk fråga som är svår att närma sig från den mekanistiska, statistiska synvinkeln hos maskinlärandesystem.
Vidare, liksom MIT-studien har tagit sig tid att låta datan definiera resultaten, är klassificeringen av det politiska värdet av fraser oundvikligen också en slags värdering, och en som inte kan motstå språkets förmåga att omkodifiera giftigt eller kontroversiellt innehåll till nya fraser som inte finns i handboken, forumreglerna eller utbildningsdatabasen.
Om en sådan kodifiering skulle bli inbäddad i populära onlinesystem, verkar det troligt att en fortlöpande ansträngning att karta den etiska och politiska temperaturen hos stora nyhetskällor kunde utvecklas till ett kallt krig mellan AI:s förmåga att urskilja partiskhet och utgivarnas förmåga att uttrycka sin ståndpunkt i en utvecklande idiom som regelbundet överträffar maskinlärandets förståelse av semantik.
14/09/21 – 1.41 GMT+2 – Ändrat ‘100 tidningar’ till ‘100 nyhetskällor’
4:58 pm – Rättat artikeln för att inkludera Samantha D’Alonzo, och relaterade korrigeringar.












