Möjligheten att generera digitala 3D-tillgångar från textmeddelanden representerar en av de mest spännande senaste utvecklingarna inom AI och datorgrafik. Eftersom marknaden för digitala 3D-tillgångar förväntas växa från 28.3 miljarder dollar 2024 till 51.8 miljarder dollar år 2029, text-to-3D AI-modeller är redo att spela en viktig roll för att revolutionera innehållsskapandet i branscher som spel, film, e-handel och mer. Men exakt hur fungerar dessa AI-system? I den här artikeln tar vi en djupdykning i de tekniska detaljerna bakom text-till-3D-generering.
Utmaningen med 3D-generering
Att generera 3D-tillgångar från text är en betydligt mer komplex uppgift än 2D-bildgenerering. Medan 2D-bilder i huvudsak är nät av pixlar, kräver 3D-tillgångar att representera geometri, texturer, material och ofta animationer i tredimensionellt utrymme. Denna extra dimensionalitet och komplexitet gör generationsuppgiften mycket mer utmanande.
Några viktiga utmaningar i text-till-3D-generering inkluderar:
Representerar 3D-geometri och struktur
Genererar konsekventa texturer och material över 3D-ytan
Säkerställa fysisk rimlighet och koherens ur flera synvinklar
Fånga fina detaljer och global struktur samtidigt
Generera tillgångar som enkelt kan renderas eller 3D-utskrivas
För att hantera dessa utmaningar använder text-till-3D-modeller flera nyckelteknologier och tekniker.
Nyckelkomponenter i text-till-3D-system
De flesta toppmoderna text-till-3D-genereringssystem delar några kärnkomponenter:
Textkodning: Konverterar inmatningstextprompten till en numerisk representation
3D-representation: En metod för att representera 3D-geometri och utseende
Generativ modell: Kärnmodellen för AI för att generera 3D-tillgången
rendering: Konverterar 3D-representationen till 2D-bilder för visualisering
Låt oss utforska var och en av dessa mer i detalj.
Textkodning
Det första steget är att konvertera inmatningstextprompten till en numerisk representation som AI-modellen kan arbeta med. Detta görs vanligtvis med hjälp av stora språkmodeller som BERT eller GPT.
3D-representation
Det finns flera vanliga sätt att representera 3D-geometri i AI-modeller:
Voxel rutnät: 3D-matriser av värden som representerar beläggning eller funktioner
Peka moln: Uppsättningar av 3D-punkter
maskor: Vertices och ytor som definierar en yta
Implicita funktioner: Kontinuerliga funktioner som definierar en yta (t.ex. teckenavståndsfunktioner)
Neurala strålningsfält (NeRF): Neurala nätverk som representerar densitet och färg i 3D-rymden
Var och en har kompromisser när det gäller upplösning, minnesanvändning och enkel generering. Många nyare modeller använder implicita funktioner eller NeRF eftersom de möjliggör resultat av hög kvalitet med rimliga beräkningskrav.
Till exempel kan vi representera en enkel sfär som en teckenavståndsfunktion:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluate SDF at a 3D point
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance to sphere surface: {distance}")
Generativ modell
Kärnan i ett text-till-3D-system är den generativa modellen som producerar 3D-representationen från textinbäddning. De flesta toppmoderna modeller använder någon variant av en diffusionsmodell, liknande de som används i 2D-bildgenerering.
Diffusionsmodeller fungerar genom att gradvis lägga till brus till data och sedan lära sig att vända denna process. För 3D-generering sker denna process i utrymmet för den valda 3D-representationen.
En förenklad pseudokod för ett utbildningssteg för diffusionsmodell kan se ut så här:
def diffusion_training_step(model, x_0, text_embedding):
# Sample a random timestep
t = torch.randint(0, num_timesteps, (1,))
# Add noise to the input
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Predict the noise
predicted_noise = model(x_t, t, text_embedding)
# Compute loss
loss = F.mse_loss(noise, predicted_noise)
return loss
# Training loop
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
Under genereringen utgår vi från rent brus och iterativt denoise, villkorat av textinbäddningen.
rendering
För att visualisera resultat och beräkna förluster under träning måste vi återge vår 3D-representation till 2D-bilder. Detta görs vanligtvis med hjälp av differentierbara renderingstekniker som tillåter gradienter att flöda tillbaka genom renderingsprocessen.
För mesh-baserade representationer kan vi använda en rasteriseringsbaserad renderare:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Set up camera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Example usage
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
För implicita representationer som NeRFs använder vi vanligtvis strålmarschtekniker för att återge vyer.
Putting it All Together: Text-to-3D Pipeline
Nu när vi har täckt nyckelkomponenterna, låt oss gå igenom hur de sammanfaller i en typisk text-till-3D-genereringspipeline:
Textkodning: Inmatningsprompten kodas till en tät vektorrepresentation med hjälp av en språkmodell.
Initial generation: En diffusionsmodell, beroende på textinbäddningen, genererar en initial 3D-representation (t.ex. en NeRF eller implicit funktion).
Konsistens i flera vyer: Modellen återger flera vyer av den genererade 3D-tillgången och säkerställer konsekvens över synpunkter.
Förfining: Ytterligare nätverk kan förfina geometrin, lägga till texturer eller förbättra detaljer.
Slutlig utgång: 3D-representationen konverteras till ett önskat format (t.ex. texturerat nät) för användning i nedströmsapplikationer.
Här är ett förenklat exempel på hur detta kan se ut i kod:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode text
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Generate initial 3D representation
initial_3d = self.diffusion_model(text_embedding)
# Render multiple views
views = self.renderer(initial_3d, num_views=4)
# Refine based on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Usage
model = TextTo3D()
text_prompt = "A red sports car"
generated_3d = model(text_prompt)
Topptext till 3d-tillgångsmodeller tillgängliga
3DGen – Meta
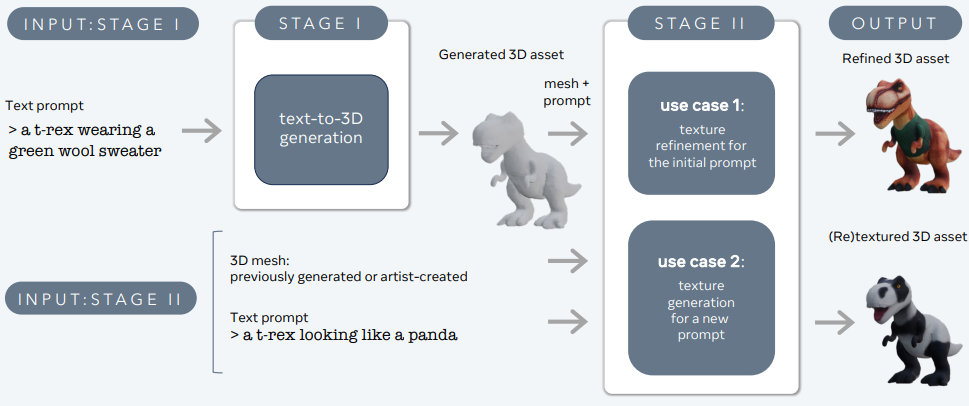
3DGen är utformad för att ta itu med problemet med att generera 3D-innehåll – som karaktärer, rekvisita och scener – från textbeskrivningar.
3DGen stöder fysiskt baserad rendering (PBR), väsentligt för realistisk 3D-tillgångsbelysning i verkliga applikationer. Det möjliggör också generativ omstrukturering av tidigare genererade eller konstnärskapade 3D-former med hjälp av nya textinmatningar. Pipelinen integrerar två kärnkomponenter: Meta 3D AssetGen och Meta 3D TextureGen, som hanterar text-till-3D respektive text-till-texturgenerering.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) ansvarar för den första genereringen av 3D-tillgångar från textmeddelanden. Denna komponent producerar ett 3D-nät med texturer och PBR-materialkartor på cirka 30 sekunder.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) förfinar texturerna som genereras av AssetGen. Den kan också användas för att generera nya texturer för befintliga 3D-nät baserat på ytterligare textbeskrivningar. Detta steg tar cirka 20 sekunder.
Point-E (OpenAI)
Point-E, utvecklad av OpenAI, är en annan anmärkningsvärd text-till-3D-genereringsmodell. Till skillnad från DreamFusion, som producerar NeRF-representationer, genererar Point-E 3D-punktmoln.
Viktiga egenskaper hos Point-E:
a) Tvåstegs pipeline: Point-E genererar först en syntetisk 2D-vy med hjälp av en text-till-bild-diffusionsmodell, och använder sedan denna bild för att konditionera en andra diffusionsmodell som producerar 3D-punktmolnet.
b) Effektivitet: Point-E är designad för att vara beräkningseffektiv och kan generera 3D-punktmoln på några sekunder på en enda GPU.
c) Färginformation: Modellen kan generera färgade punktmoln och bevara både geometrisk information och utseendeinformation.
Begränsningar:
Lägre trohet jämfört med mesh-baserade eller NeRF-baserade metoder
Punktmoln kräver ytterligare bearbetning för många nedströmsapplikationer
Shap-E (OpenAI):
Bygger på Point-E introducerade OpenAI Shap-E, som genererar 3D-nät istället för punktmoln. Detta åtgärdar några av begränsningarna med Point-E samtidigt som beräkningseffektiviteten bibehålls.
Nyckelfunktioner hos Shap-E:
a) Implicit representation: Shap-E lär sig att generera implicita representationer (signerade avståndsfunktioner) av 3D-objekt.
b) Nätextraktion: Modellen använder en differentierbar implementering av algoritmen för marschkuber för att konvertera den implicita representationen till ett polygonalt nät.
c) Texturgenerering: Shap-E kan också generera texturer för 3D-maskorna, vilket resulterar i mer visuellt tilltalande utdata.
fördelar:
Snabba generationstider (sekunder till minuter)
Direkt mesh-utgång lämplig för rendering och nedströmsapplikationer
Förmåga att generera både geometri och textur
GET3D (NVIDIA):
GET3D, utvecklad av NVIDIA-forskare, är en annan kraftfull text-till-3D-generationsmodell som fokuserar på att producera högkvalitativa texturerade 3D-nät.
Nyckelfunktioner i GET3D:
a) Explicit ytrepresentation: Till skillnad från DreamFusion eller Shap-E genererar GET3D direkt explicita ytrepresentationer (maskor) utan mellanliggande implicita representationer.
b) Texturgenerering: Modellen inkluderar en differentierbar renderingsteknik för att lära sig och generera högkvalitativa texturer för 3D-maskorna.
c) GAN-baserad arkitektur: GET3D använder ett generativt motstridigt nätverk (GAN), vilket möjliggör snabb generering när modellen väl har tränats.
fördelar:
Högkvalitativ geometri och texturer
Snabba slutledningstider
Direkt integration med 3D-renderingsmotorer
Begränsningar:
Kräver 3D-träningsdata, som kan vara knappa för vissa objektkategorier
Slutsats
Text-to-3D AI-generering representerar en grundläggande förändring i hur vi skapar och interagerar med 3D-innehåll. Genom att utnyttja avancerade djupinlärningstekniker kan dessa modeller producera komplexa, högkvalitativa 3D-tillgångar från enkla textbeskrivningar. När tekniken fortsätter att utvecklas kan vi förvänta oss att se allt mer sofistikerade och kapabla text-till-3D-system som kommer att revolutionera industrier från spel och film till produktdesign och arkitektur.
Jag har ägnat de senaste fem åren åt att fördjupa mig i den fascinerande världen av Machine Learning och Deep Learning. Min passion och expertis har lett mig till att bidra till över 50 olika programvaruutvecklingsprojekt, med särskilt fokus på AI/ML. Min pågående nyfikenhet har också dragit mig mot Natural Language Processing, ett område som jag är ivrig att utforska vidare.