Artificiell intelligens
Hur Stable Diffusion Kan Utvecklas Som En Mainstream-Konsumentprodukt

Ironiskt nog är Stable Diffusion, det nya AI-bildsyntesramverket som har tagit världen med storm, varken stabilt eller riktigt “diffuserat” – åtminstone inte ännu.
Den fulla omfattningen av systemets funktioner sprids över en varierad samling av konstant föränderliga erbjudanden från ett fåtal utvecklare som febrilt utbyter den senaste informationen och teorierna i olika diskussioner på Discord – och den överväldigande majoriteten av installationsförfarandena för de paket de skapar eller modifierar är mycket långt ifrån “plug and play”.
Istället tenderar de att kräva kommandorads- eller BAT-driven installation via GIT, Conda, Python, Miniconda och andra bländande utvecklingsramverk – programvarupaket som är så sällsynta bland den allmänna konsumenten att deras installation ofta flaggas av antivirus- och anti-malware-leverantörer som bevis på ett komprometterat värdsystem.

Bara ett litet urval av etapperna i hinderbanan som den standardmässiga Stable Diffusion-installationen för närvarande kräver. Många av distributionerna kräver också specifika versioner av Python, som kan vara i konflikt med befintliga versioner som är installerade på användarens maskin – även om detta kan undvikas med Docker-baserade installationer och, i viss mån, genom användning av Conda-miljöer.
Meddelandetrådar i både SFW- och NSFW-Stable Diffusion-samhällen är översvämmade av tips och tricks relaterade till hackning av Python-skript och standardinstallationer, för att möjliggöra förbättrad funktion, eller för att lösa vanliga beroendefel och en rad andra problem.
Detta lämnar den genomsnittliga konsumenten, som är intresserad av att skapa fantastiska bilder från textprompt, ganska mycket på nåder av det växande antalet kommersiella API-webbgränssnitt, de flesta av vilka erbjuder ett minimalt antal gratis bildgenerationer innan de kräver inköp av token.
Dessutom vägrar nästan alla dessa webbaserade erbjudanden att producera NSFW-innehåll (mycket av vilket kan relatera till icke-porografiska ämnen av allmänt intresse, såsom “krig”), som skiljer Stable Diffusion från de censurerade tjänsterna från OpenAI’s DALL-E 2.
‘Photoshop för Stable Diffusion’
Förvirrat av de fantastiska, vågade eller övervärldsliga bilderna som dagligen befolkar Twitter’s #stablediffusion-hashtag, väntar världen i stort sett på ‘Photoshop för Stable Diffusion’ – ett installerbart program som omfattar det bästa och kraftfullaste funktionsomfånget i Stability.ai:s arkitektur, samt de olika innovativa innovationerna från den framväxande SD-utvecklingsgemenskapen, utan några flytande CLI-fönster, oklara och ständigt föränderliga installations- och uppdateringsrutiner, eller saknade funktioner.
Vad vi för närvarande har, i de flesta av de mer kapabla installationerna, är en varierat elegant webbsida som sträcker sig över ett avskalat kommandofönster, och vars URL är en localhost-port:

Liknande CLI-drivna syntesappar som FaceSwap och BAT-centrerade DeepFaceLab, visar ‘prepack’-installationen av Stable Diffusion sina kommandorotsrötter, med gränssnittet som nås via en localhost-port (se toppen av bilden ovan) som kommunicerar med den CLI-baserade Stable Diffusion-funktionaliteten.
Utan tvekan är ett mer strömlinjeformat program på väg. Redan finns det flera Patreon-baserade integrala program som kan laddas ner, såsom GRisk och NMKD (se bild nedan) – men ingen som, ännu, integrerar det fulla utbudet av funktioner som vissa av de mer avancerade och mindre tillgängliga implementationerna av Stable Diffusion kan erbjuda.

Tidiga, Patreon-baserade paket av Stable Diffusion, lätt ‘app-iserade’. NMKD:s är den första som integrerar CLI-utdata direkt i GUI:t.
Låt oss ta en titt på vad en mer polerad och integral implementation av denna förbluffande öppna källkodsunderverk kan komma att se ut – och vilka utmaningar den kan möta.
Juridiska överväganden för en fullt finansierad kommersiell Stable Diffusion-applikation
NSFW-faktorn
Stable Diffusion-källkoden har släppts under en extremt tillåtande licens som inte förbjuder kommersiella återimplementeringar och derivatverk som bygger omfattande från källkoden.
Förutom den ovannämnda och växande mängden Patreon-baserade Stable Diffusion-byggnader, samt det omfattande antalet applikationsplugin som utvecklas för Figma, Krita, Photoshop, GIMP och Blender (bland andra), finns det ingen praktisk anledning till varför en välfinansierad programvaruutvecklingsenhet inte kunde utveckla en långt mer sofistikerad och kapabel Stable Diffusion-applikation. Från en marknads synvinkel finns det alla skäl att tro att flera sådana initiativ redan är väl på gång.
Här möter sådana ansträngningar omedelbart dilemmat om huruvida eller inte applikationen ska tillåta Stable Diffusions inbyggda NSFW-filter (en fragment av kod), att stängas av.
‘Begrava’ NSFW-omkopplaren
Även om Stability.ai:s öppna källlicens för Stable Diffusion innehåller en brett tolkningsbar lista över tillämpningar som den inte kan användas för (t.ex. pornografiskt innehåll och deepfakes), är den enda sättet en leverantör kunde effektivt förhindra sådan användning att man skulle sammanställa NSFW-filtret till en ogenomskinlig körbar fil istället för en parameter i en Python-fil, eller tvinga en kontrollsummejämförelse på Python-filen eller DLL som innehåller NSFW-direktivet, så att renderingar inte kan ske om användare ändrar dessa inställningar.
Detta skulle lämna den påstådda applikationen “kastrerad” på samma sätt som DALL-E 2 för närvarande är, vilket minskar dess kommersiella attraktionskraft. Dessutom skulle det oundvikligen dyka upp dekompilerade “doktorerade” versioner av dessa komponenter (antingen ursprungliga Python-körbara element eller sammanställda DLL-filer, som nu används i Topaz-linjen av AI-bildförbättringsverktyg) som skulle kunna låsa upp sådana begränsningar, enbart genom att ersätta de hinderliga elementen och ogiltigförklara eventuella kontrollsummebehov.
Till slut kan leverantören välja att enbart upprepa Stability.ai:s varning mot missbruk som kännetecknar den första körningen av många nuvarande Stable Diffusion-distributioner.
Men de små öppna utvecklarna som för närvarande använder informella varningar på detta sätt har lite att förlora i jämförelse med ett programvaruföretag som har investerat betydande mängder tid och pengar i att göra Stable Diffusion fullfjädrad och tillgänglig – vilket inbjuder till djupare överväganden.
Deepfake-ansvar
Som vi nyligen noterade, innehåller LAION-estetiska databasen, en del av de 4,2 miljarder bilder som Stable Diffusions pågående modeller tränades på, ett stort antal kändisbilder, vilket möjliggör för användare att effektivt skapa deepfakes, inklusive deepfake-kändisporn.

Från vår senaste artikel, fyra faser av Jennifer Connelly under fyra decennier av hennes karriär, härledda från Stable Diffusion.
Detta är ett separat och mer kontroversiellt ämne än genereringen av (vanligtvis) laglig “abstrakt” porn, som inte avbildar “verkliga” människor (även om sådana bilder härleds från flera verkliga foton i träningsmaterialet).
Eftersom ett ökande antal amerikanska delstater och länder utvecklar eller har infört lagar mot deepfake-pornografi, kan Stable Diffusions förmåga att skapa kändisdeepfakes innebära att en kommersiell applikation som inte är helt censurerad (dvs. som kan skapa pornografiskt material) kanske fortfarande behöver någon form av filter för att upptäcka kändisansikten.
En metod skulle vara att tillhandahålla en inbyggd “svartlista” över termer som inte kommer att accepteras i en användarprompt, relaterad till kändisnamn och till fiktiva karaktärer som de kan vara associerade med. Förmodligen skulle sådana inställningar behöva införas på fler språk än bara engelska, eftersom den ursprungliga datan innehåller andra språk. En annan tillvägagångssätt kunde vara att integrera kändisigenkänningsystem som de som utvecklats av Clarifai.
Det kan vara nödvändigt för programvaruproducenter att införa sådana metoder, kanske initialt inaktiverade, vilket kan hjälpa till att förhindra att en fullfjädrad fristående Stable Diffusion-applikation genererar kändisansikten, i avvaktan på ny lagstiftning som kan göra sådan funktionalitet olaglig.
Återigen, dock, kan sådan funktionalitet oundvikligen dekomplieras och omvändas av intresserade parter; men programvaruproducenten kunde, i sådant fall, hävda att detta i princip är obehörig vandalism – så länge som sådan omvänd ingenjörskonst inte görs alltför enkel.
Funktioner som kan ingå
Den grundläggande funktionaliteten i någon distribution av Stable Diffusion skulle förväntas av någon välfinansierad kommersiell applikation. Dessa inkluderar möjligheten att använda textprompt för att generera lämpliga bilder (text-till-bild); möjligheten att använda skisser eller andra bilder som riktlinjer för nya genererade bilder (bild-till-bild); medlen att justera hur “fantasifull” systemet instrueras att vara; ett sätt att avväga renderingtiden mot kvaliteten; och andra “grunder”, såsom valfri automatisk bild/prompt-arkivering och rutinmässig valfri uppskalning via RealESRGAN, och åtminstone grundläggande “ansiktsfixering” med GFPGAN eller CodeFormer.
Det är en ganska “vaniljinstall”. Låt oss ta en titt på några av de mer avancerade funktionerna som för närvarande utvecklas eller utökas, som kunde integreras i en fullfjädrad “traditionell” Stable Diffusion-applikation.
Stokastisk frysning
Även om du återanvänder ett frö från en tidigare lyckad rendering, är det fruktansvärt svårt att få Stable Diffusion att exakt upprepa en transformation om någon del av prompten eller källbilden (eller båda) ändras för en efterföljande rendering.
Detta är ett problem om du vill använda EbSynth för att påtvinga Stable Diffusions transformationer på riktiga videor på ett tidsmässigt sammanhängande sätt – även om tekniken kan vara mycket effektiv för enkla huvud-och-axelbilder:

Begränsad rörelse kan göra EbSynth till ett effektivt medium för att omvandla Stable Diffusions transformationer till realistiska videor. Källa: https://streamable.com/u0pgzd
EbSynth fungerar genom att extrapolera ett litet urval “ändrade” nyckelbilder till en video som har renderats ut i en serie bildfiler (och som senare kan sättas samman igen till en video).

I det här exemplet från EbSynth-sajten har ett litet antal ramar från en video målats i en konstnärlig stil. EbSynth använder dessa ramar som styrande för att lika mycket ändra hela videon så att den matchar den målade stilen. Källa: https://www.youtube.com/embed/eghGQtQhY38
I exemplet nedan, som visar nästan ingen rörelse alls från den (verkliga) blonda yogainstruktören till vänster, har Stable Diffusion fortfarande svårt att upprätthålla ett konsekvent ansikte, eftersom de tre bilderna som omvandlas som “nyckelbilder” inte är helt identiska, även om de alla delar samma numeriska frö.

Här, även med samma prompt och frö över alla tre transformationer, och mycket få förändringar mellan källramarna, varierar kroppsmusklerna i storlek och form, men viktigare är att ansiktet är inkonsekvent, vilket hindrar tidsmässig sammanhängande i en potentiell EbSynth-rendering.
Även om SD/EbSynth-videon nedan är mycket uppfinningsrik, där användarens fingrar har förvandlats till (i turordning) en gående par byxor och en anka, typifierar inkonsekvensen i byxorna problemet som Stable Diffusion har med att upprätthålla konsekvens över olika nyckelbilder, även när källramarna är liknande varandra och fröet är konsekvent.

En mans fingrar blir en gående man och en anka, via Stable Diffusion och EbSynth. Källa: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Användaren som skapade den här videon kommenterade att anka-transformationen, som är den mer effektiva av de två, krävde bara en enda omvandlad nyckelbild, medan det var nödvändigt att rendera 50 Stable Diffusion-bilder för att skapa de gående byxorna, som visar mer tidsmässig inkonsekvens. Användaren noterade också att det tog fem försök att uppnå konsekvens för var och en av de 50 nyckelbilderna.
Därför skulle det vara en stor fördel för en riktigt omfattande Stable Diffusion-applikation att tillhandahålla funktionalitet som bevarar egenskaper till maximal utsträckning över nyckelbilder.
En möjlighet är att applikationen tillåter användaren att “frysa” den stokastiska koden för transformationen på varje ram, vilket för närvarande bara kan uppnås genom att modifiera källkoden manuellt. Som exemplet nedan visar hjälper detta till att upprätthålla tidsmässig sammanhängande, även om det inte löser det helt:

En Reddit-användare omvandlade webbkamerabilder av sig själv till olika kändisar genom att inte bara behålla fröet (vilket vilken implementation av Stable Diffusion som helst kan göra), utan genom att se till att den stokastiska_koden() -parametern var identisk i varje transformation. Detta uppnåddes genom att modifiera koden, men kunde lätt bli en användaråtkomlig omkopplare. Tydligt, dock, löser det inte alla tidsmässiga problem. Källa: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Molnbaserad textuell inversion
En bättre lösning för att framkalla tidsmässigt sammanhängande karaktärer och föremål är att “baka in” dem i en textuell inversion – en 5KB-fil som kan tränas på några timmar baserat på bara fem annoterade bilder, som sedan kan framkallas av en särskild ‘*’ -prompt, vilket möjliggör till exempel en bestående utseende av nya karaktärer för införande i en berättelse.

Bilder associerade med lämpliga taggar kan omvandlas till separata enheter via textuell inversion, och framkallas utan tvetydighet, och i rätt sammanhang och stil, av särskilda tokenord. Källa: https://huggingface.co/docs/diffusers/training/text_inversion
Textuella inversioner är adjungerade filer till den mycket stora och fullständigt tränade modellen som Stable Diffusion använder, och är i princip “slipströmmade” in i den framkallande/promptande processen, så att de kan deltaga i modellbaserade scener, och dra nytta av modellens enorma databas av kunskap om föremål, stilar, miljöer och interaktioner.
Men även om en textuell inversion inte tar lång tid att träna, kräver den en stor mängd VRAM; enligt olika aktuella genomgångar, någonstans mellan 12, 20 och till och med 40GB.
Eftersom de flesta oerfarna användare inte sannolikt har den typen av GPU-kraft till sitt förfogande, dyker molntjänster upp som kommer att hantera operationen, inklusive en Hugging Face-version. Även om det finns Google Colab-implementationer som kan skapa textuella inversioner för Stable Diffusion, kan de erforderliga VRAM- och tidskraven göra dem utmanande för användare av den kostnadsfria Colab-nivån.
För en potentiell fullfjädrad och välfinansierad Stable Diffusion-applikation (installerad) verkar det som en uppenbar moneteringsstrategi att föra över denna tunga uppgift till företagets molnservrar (under förutsättning att en låg- eller avgiftsfri Stable Diffusion-applikation är genomsyrad av sådan icke-kostnadsfri funktionalitet, vilket verkar troligt i många möjliga applikationer som kommer att dyka upp från den här tekniken under de närmaste 6-9 månaderna).
Dessutom kunde den ganska komplicerade processen att annotera och formatera de inskickade bilderna och texten dra nytta av automatisering i en integrerad miljö. Den potentiella “beroendefaktorn” i att skapa unika element som kan utforska och interagera med de väldiga världarna av Stable Diffusion skulle verka potentiellt tvångsmässig, både för allmänna entusiaster och yngre användare.
Flexibel promptviktning
Det finns många nuvarande implementationer som tillåter användaren att tilldela större betoning till en del av en lång textprompt, men instrumenteringen varierar ganska mycket mellan dessa, och är ofta klumpig eller ointuitiv.
Den mycket populära Stable Diffusion-grenen av AUTOMATIC1111, till exempel, kan sänka eller höja värdet på en promptord genom att omge den med enkla eller flera hakparenteser (för att minska betoningen) eller hakparenteser för extra betoning.

Hakparenteser och/eller parenteser kan omvandla din frukost i den här versionen av Stable Diffusion-promptviktning, men det är en kolesterolkatastrof antingen way.
Andra iterationer av Stable Diffusion använder utropstecken för betoning, medan de mest flexibla tillåter användare att tilldela vikter till varje ord i prompten via GUI:t.
Systemet bör också tillåta negativa promptvikter – inte bara för skräckfans, utan för att det kan finnas färre alarmerande och mer upplyftande mysterier i Stable Diffusions latenta utrymme som vår begränsade användning av språk inte kan framkalla.
Utskrivning
Strax efter den sensationella öppna källkodsutgåvan av Stable Diffusion försökte OpenAI – till stor del utan framgång – att återerövra en del av sin DALL-E 2-åska genom att tillkännage “utskrivning”, som tillåter en användare att utöka en bild bortom dess gränser med semantisk logik och visuell sammanhängande.
Naturligtvis har detta sedan dess implementerats i olika former för Stable Diffusion, samt i Krita, och bör definitivt ingå i en omfattande, Photoshop-liknande version av Stable Diffusion.
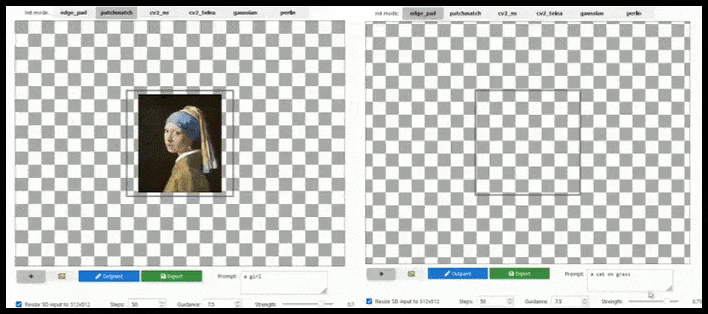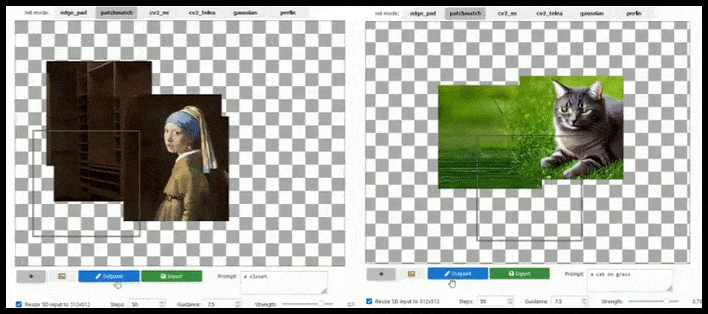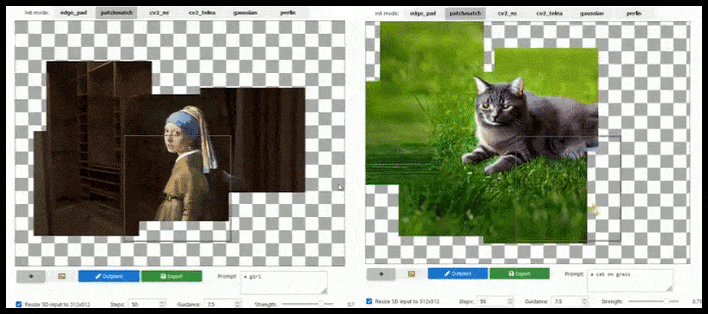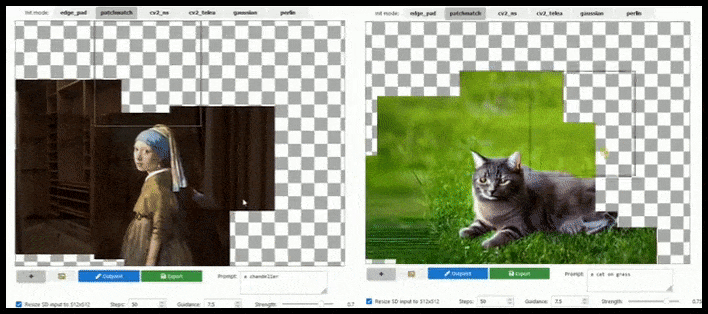
Tile-baserad augmentation kan utöka en standard 512×512-rendering nästan oändligt, så länge prompten, den befintliga bilden och den semantiska logiken tillåter det. Källa: https://github.com/lkwq007/stablediffusion-infinity
Eftersom Stable Diffusion är tränad på 512x512px-bilder (och av en mängd andra skäl) skär den ofta av huvuden (eller andra viktiga kroppsdelar) på mänskliga ämnen, även där prompten tydligt angav “huvudbetoning” etc..

Typiska exempel på Stable Diffusions “avhuvudning”; men utskrivning kunde sätta George tillbaka i bilden.
Någon form av utskrivningsimplementering av den typ som visas i den animerade bilden ovan (som är baserad uteslutande på Unix-bibliotek, men borde kunna replikeras på Windows) borde också utrustas som en enklick-/prompt-åtgärd för att lösa detta problem.
För närvarande utökar många användare canvassen på “avhuvudade” avbildningar uppåt, fyller i huvudområdet grovt och använder img2img för att slutföra den felaktiga renderingen.
Effektiv maskering som förstår sammanhang
Maskering kan vara en fruktansvärt träffsäker angelägenhet i Stable Diffusion, beroende på grenen eller versionen i fråga. Ofta, där det är möjligt att rita en sammanhängande mask över huvud taget, slutar den angivna området med att målas med innehåll som inte tar hela bilden i beaktande.
På ett tillfälle maskerade jag ut iris i en ansiktsbild och angav prompten ‘blå ögon’ som en maskinmålning – bara för att upptäcka att jag tycktes titta genom två utskurna mänskliga ögon på en avlägsen bild av en overklig varg. Jag gissar att jag är lycklig att det inte var Frank Sinatra.
Semantisk redigering är också möjlig genom att identifiera bruset som konstruerade bilden från första början, vilket tillåter användaren att adressera specifika strukturföremål i en rendering utan att störa resten av bilden:

Ändra ett element i en bild utan traditionell maskering och utan att ändra angränsande innehåll, genom att identifiera bruset som ursprungligen genererade bilden och adressera de delar som bidrog till målområdet. Källa: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Denna metod bygger på K-Diffusion-samplaren.
Semantiska filter för fysiologiska fel
Som vi tidigare nämnt kan Stable Diffusion ofta lägga till eller subtrahera lemmar, till stor del på grund av dataproblem och brister i annotationerna som åtföljer de bilder som tränade den.

Liksom den där otåliga killen som stack ut tungan i gruppfotot, är Stable Diffusions biologiska grymheter inte alltid omedelbart uppenbara, och du kan ha delat din senaste AI-mästerverk på Instagram innan du märker de extra händerna eller de smälta lemmarna.
Det är så svårt att korrigera dessa typer av fel att det skulle vara användbart om en fullfjädrad Stable Diffusion-applikation innehöll någon form av anatomisk igenkänningsystem som använde semantisk segmentering för att beräkna om den inkommande bilden innehåller allvarliga anatomiska brister (såsom i bilden ovan), och kasserar den till förmån för en ny rendering innan den presenteras för användaren.

Naturligtvis kan du vilja rendera gudinnan Kali, eller Doktor Octopus, eller till och med rädda en opåverkad del av en lem-ådrad bild, så den här funktionen bör vara en valfri omkopplare.
Om användare kunde acceptera aspekten av telemetri, kunde sådana misslyckanden till och med överföras anonymt i en kollektiv ansträngning av federativt lärande som kan hjälpa framtida modeller att förbättra sin förståelse av anatomisk logik.
LAION-baserad automatisk ansiktsförbättring
Som jag noterade i min tidigare titt på tre saker som Stable Diffusion kan hantera i framtiden, bör det inte lämnas enbart till någon version av GFPGAN att försöka “förbättra” renderade ansikten i första hand.
GFPGAN:s “förbättringar” är fruktansvärt generiska, ofta undergräver identiteten hos den avbildade personen och fungerar enbart på ett ansikte som har fått lika lite bearbetningstid eller uppmärksamhet som någon annan del av bilden.
Därför bör ett professionellt standardprogram för Stable Diffusion kunna känna igen ett ansikte (med en standard och relativt lätt bibliotek som YOLO), applicera full kraft av tillgänglig GPU-kraft för att återge det, och antingen blanda det förbättrade ansiktet in i den ursprungliga fullkontext-renderingen, eller spara det separat för manuell omkomposition. För närvarande är detta en ganska “hands-on”-operation.
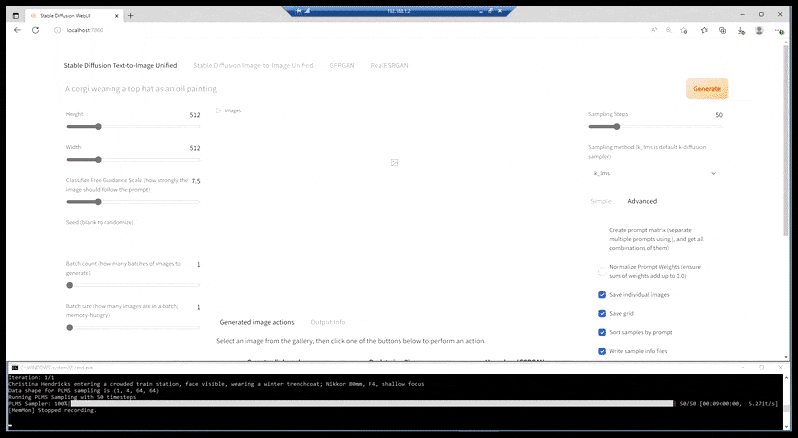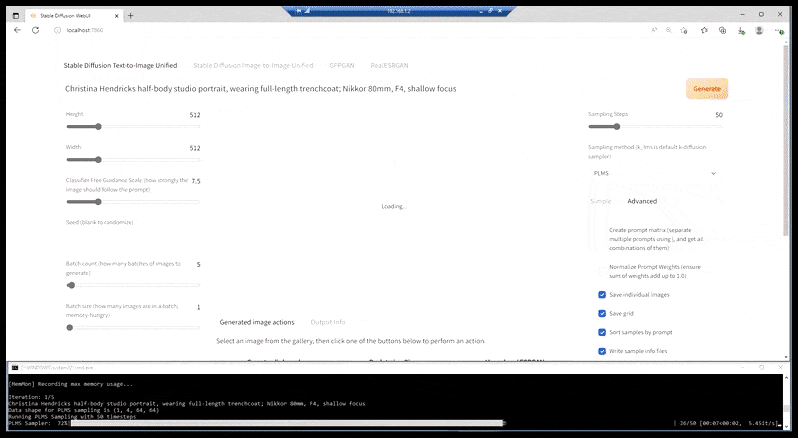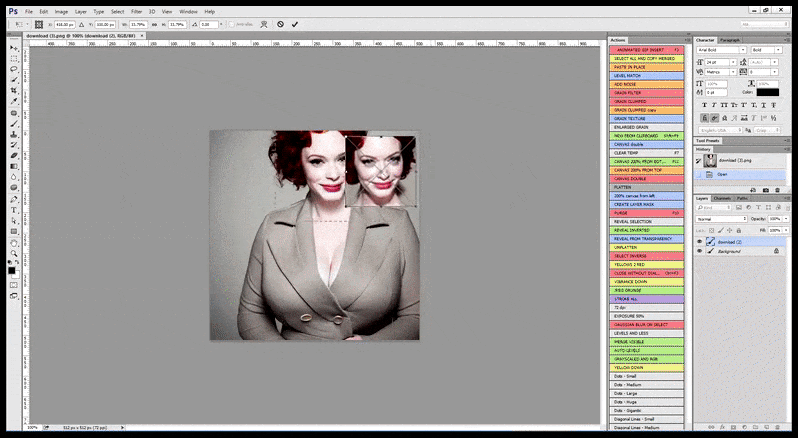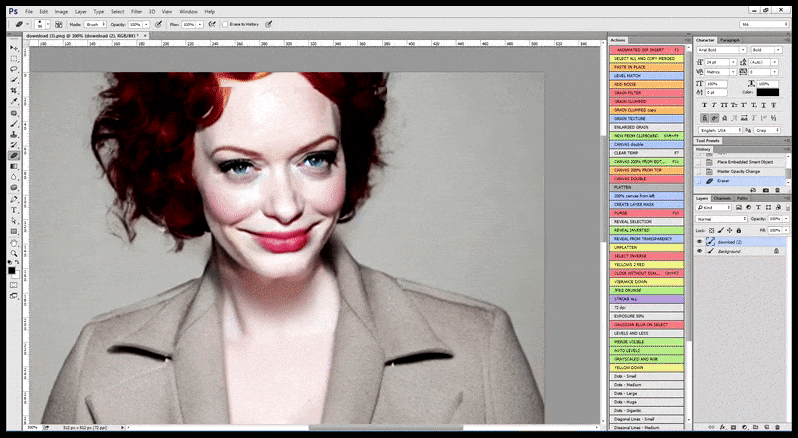
I fall där Stable Diffusion har tränats på ett tillräckligt antal bilder av en kändis, är det möjligt att fokusera hela GPU-kapaciteten på en efterföljande rendering enbart av ansiktet på den renderade bilden, vilket vanligtvis är en anmärkningsvärd förbättring – och, till skillnad från GFPGAN, bygger på information från LAION-tränad data, snarare än att enbart justera de renderade pixlarna.
In-app LAION-sökningar
Sedan användare började inse att sökning i LAION-databasen efter koncept, människor och teman kunde vara till hjälp för en bättre användning av Stable Diffusion, har flera online-LAION-utforskare skapats, inklusive haveibeentrained.com.

Sökfunktionen på haveibeentrained.com låter användare utforska de bilder som driver Stable Diffusion, och upptäcka om föremål, människor eller idéer som de kan vilja framkalla från systemet sannolikt har tränats in i det. Källa: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Även om sådana webbaserade databaser ofta avslöjar några av de taggar som åtföljer bilderna, innebär processen med generalisering som sker under modellträning att det är osannolikt att någon specifik bild kan framkallas med hjälp av dess tagg som en prompt.
Dessutom innebär borttagandet av ‘stop-ord’ och praktiken med avstamning och lemmatisering i naturligt språkbehandling att många av de fraser som visas har delats upp eller utelämnats innan de tränades in i Stable Diffusion.
Ändå kan sättet som estetiska grupperingar binder samman i dessa gränssnitt lära slutanvändaren en hel del om logiken (eller, argumenterbart, “personligheten”) hos Stable Diffusion, och bevisa en hjälp för bättre bildproduktion.
Slutsats
Det finns många andra funktioner som jag skulle vilja se i en fullständig infödd skrivbordsimplementation av Stable Diffusion, såsom inbyggd CLIP-baserad bildanalys, som omvänt den standardmässiga Stable Diffusion-processen och tillåter användaren att framkalla fraser och ord som systemet naturligt skulle associera med källbilden eller renderingen.
Dessutom vore sann tile-baserad skalning en välkommen tillägg, eftersom ESRGAN är nästan lika trubbigt som GFPGAN. Lyckligtvis är planer på att integrera txt2imghd-implementationen av GOBIG snabbt på väg att göra detta till verklighet över distributionerna, och det verkar som ett uppenbart val för en skrivbordsiteration.
Några andra populära förfrågningar från Discord-samhällena intresserar mig mindre, såsom integrerade promptordlistor och tillämpliga listor över artister och stilar, även om en in-app-anteckningsbok eller anpassningsbar lexikon av fraser skulle verka som en logisk tillägg.
Likaså är de nuvarande begränsningarna för mänsklig animation i Stable Diffusion, även om de har startats av CogVideo och olika andra projekt, fortfarande extremt embryonala, och på nåder av uppströmsforskning om tidsmässiga prioriteringar som relaterar till äkta mänsklig rörelse.
För närvarande är Stable Diffusion-video strikt psykedelisk, även om den kan ha en mycket ljusare nära framtid i deepfake-marionetter, via EbSynth och andra relativt nya text-till-video-initiativ (och det är värt att notera avsaknaden av syntetiserade eller “ändrade” människor i Runways senaste promotionsvideo).
En annan värdefull funktionalitet skulle vara transparent Photoshop-genomgång, som redan etablerats i Cinema4D:s textureditor, bland liknande implementationer. Med detta kan du enkelt skicka bilder mellan applikationer och använda varje applikation för att utföra de transformationer som den excellerar i.
Slutligen, och kanske viktigast, bör en fullfjädrad skrivbords-Stable Diffusion-programvara kunna inte bara växla lätt mellan kontrollpunkter (dvs. versioner av den underliggande modell som driver systemet), utan också kunna uppdatera anpassade Textuella inversioner som fungerade med tidigare officiella modellutgåvor, men som annars kan brytas av senare versioner av modellen (som utvecklare på den officiella Discord har indikerat kan vara fallet).
Ironiskt nog är organisationen i den bästa positionen för att skapa en sådan kraftfull och integrerad matris av verktyg för Stable Diffusion, Adobe, som har allierat sig så starkt med Content Authenticity Initiative att det kan verka som ett retrogradt PR-misstag för företaget – såvida det inte skulle försvaga Stable Diffusions generativa krafter lika grundligt som OpenAI har gjort med DALL-E 2, och positionera det istället som en naturlig utveckling av dess betydande innehav i aktiebilder.
Publicerad första gången den 15 september 2022.












