Artificiell intelligens
Komplett guide till Gemma 2: Googles nya öppna stora språkmodell

Gemma 2 bygger vidare på sin föregångare och erbjuder förbättrad prestanda och effektivitet, tillsammans med en uppsättning innovativa funktioner som gör den särskilt attraktiv för både forskning och praktiska tillämpningar. Det som särskiljer Gemma 2 är dess förmåga att leverera prestanda som är jämförbar med mycket större proprietära modeller, men i ett paket som är utformat för bredare tillgänglighet och användning på mer blygsamma hårdvarukonfigurationer.
När jag gick in på de tekniska specifikationerna och arkitekturen för Gemma 2, blev jag alltmer imponerad av designens genialitet. Modellen inkorporerar flera avancerade tekniker, inklusive nya uppmärksamhetsmekanismer och innovativa tillvägagångssätt för träningstabilitet, som bidrar till dess anmärkningsvärda förmågor.

Google Open Source LLM Gemma
I denna omfattande guide kommer vi att utforska Gemma 2 i detalj, undersöka dess arkitektur, nyckelfunktioner och praktiska tillämpningar. Oavsett om du är en erfaren AI-utövare eller en entusiastisk nybörjare inom området, syftar den här artikeln till att ge värdefulla insikter i hur Gemma 2 fungerar och hur du kan utnyttja dess kraft i dina egna projekt.
Vad är Gemma 2?
Gemma 2 är Googles senaste öppna stora språkmodell, utformad för att vara lättviktsmen kraftfull. Den bygger på samma forskning och teknik som användes för att skapa Googles Gemini-modeller, och erbjuder toppmoderna prestanda i ett mer tillgängligt paket. Gemma 2 finns i två storlekar:
Gemma 2 9B: En modell med 9 miljarder parametrar
Gemma 2 27B: En större modell med 27 miljarder parametrar
Varje storlek finns i två varianter:
Basmodeller: Förtränade på en stor mängd textdata
Instruction-tuned (IT)-modeller: Finjusterade för bättre prestanda på specifika uppgifter
Åtkomst till modellerna i Google AI Studio: Google AI Studio – Gemma 2
Läs rapporten här: Gemma 2 Teknisk Rapport
Nyckelfunktioner och förbättringar
Gemma 2 introducerar flera betydande framsteg jämfört med sin föregångare:
1. Ökad träningsdata
Modellerna har tränats på avsevärt mer data:
Gemma 2 27B: Tränad på 13 biljoner token
Gemma 2 9B: Tränad på 8 biljoner token
Denna utvidgade dataset, som främst består av webbdata (främst engelska), kod och matematik, bidrar till modellernas förbättrade prestanda och mångsidighet.
2. Sliding Window Attention
Gemma 2 implementerar en ny approach till uppmärksamhetsmekanismer:
Varannan lager använder en sliding window attention med en lokal kontext på 4096 token
Växlande lager använder fullständig kvadratisk global uppmärksamhet över hela 8192 token kontext
Denna hybridapproach syftar till att balansera effektivitet med förmågan att fånga långväga beroenden i indata.
3. Soft-Capping
För att förbättra träningsstabilitet och prestanda introducerar Gemma 2 en soft-capping-mekanism:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Tillämpad på uppmärksamhetslogit attention_logits = soft_cap(attention_logits, cap=50.0) # Tillämpad på slutliga lagerlogit final_logits = soft_cap(final_logits, cap=30.0)
Denna teknik förhindrar att logiterna växer för stora utan hård trunkering, samtidigt som den bibehåller mer information och stabiliserar träningsprocessen.
- Gemma 2 9B: En modell med 9 miljarder parametrar
- Gemma 2 27B: En större modell med 27 miljarder parametrar
Varje storlek finns i två varianter:
- Basmodeller: Förtränade på en stor mängd textdata
- Instruction-tuned (IT)-modeller: Finjusterade för bättre prestanda på specifika uppgifter
4. Kunskapsdestillering
För 9B-modellen använder Gemma 2 kunskapsdestillerings-tekniker:
- Förträning: 9B-modellen lär sig från en större lärar-modell under den initiala träningsfasen
- Efter träningsfas: Både 9B och 27B modellerna använder on-policy destillering för att förbättra sin prestanda
Denna process hjälper den mindre modellen att fånga de större modellernas förmågor mer effektivt.
5. Modell-sammanslagning
Gemma 2 använder en ny modell-sammanslagningsteknik som kallas Warp, som kombinerar flera modeller i tre faser:
- Exponential Moving Average (EMA) under förstärkt inlärning
- Spherical Linear intERPolation (SLERP) efter finjustering av flera policys
- Linear Interpolation Towards Initialization (LITI) som en sista fas
Denna approach syftar till att skapa en mer robust och kapabel slutmodell.
Prestandamätningar
Gemma 2 visar imponerande prestanda över olika mätningar:
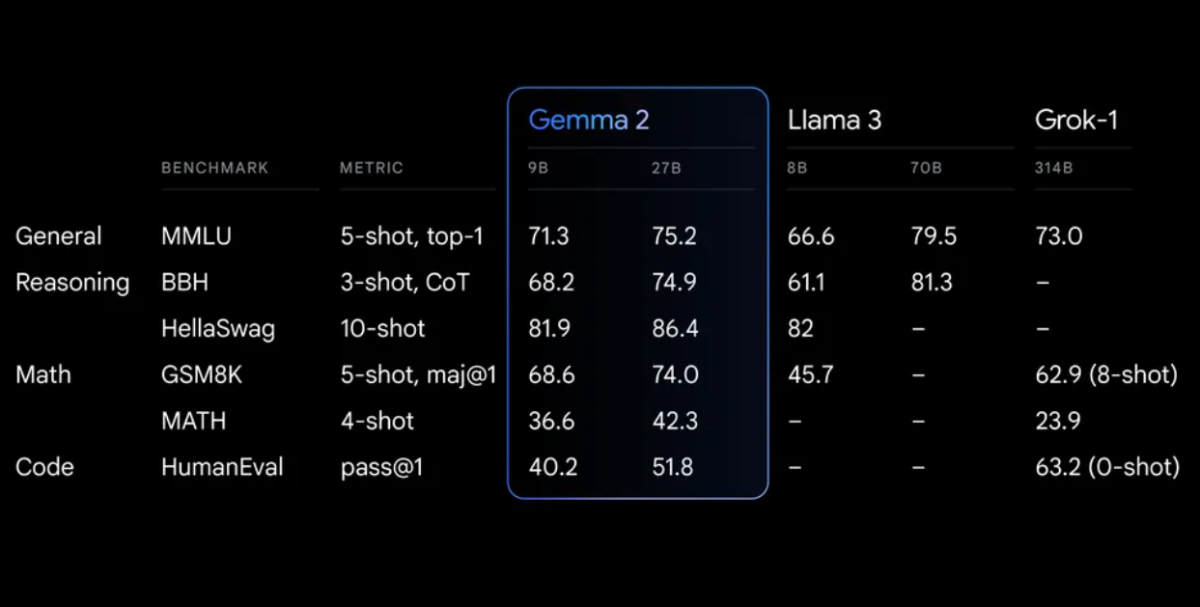
Gemma 2 på en ombyggd arkitektur, utformad för både exceptionell prestanda och inferens-effektivitet
Komma igång med Gemma 2
För att börja använda Gemma 2 i dina projekt har du flera alternativ:
1. Google AI Studio
För snabb experimentell utan hårdvarukrav kan du komma åt Gemma 2 via Google AI Studio.
2. Hugging Face Transformers
Gemma 2 är integrerad med den populära Hugging Face Transformers-bibliotek. Här är hur du kan använda den:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Ladda modell och tokenisator model_name = "google/gemma-2-27b-it" # eller "google/gemma-2-9b-it" för den mindre versionen tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Förbered indata prompt = "Förklara konceptet med kvantmekanisk sammanflätning på ett enkelt sätt." inputs = tokenizer(prompt, return_tensors="pt") # Generera text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
För TensorFlow-användare är Gemma 2 tillgänglig via Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Ladda modell
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generera text
prompt = "Förklara konceptet med kvantmekanisk sammanflätning på ett enkelt sätt."
output = model.generate(prompt, max_length=200)
print(output)
Avancerad användning: Bygga ett lokalt RAG-system med Gemma 2
En kraftfull tillämpning av Gemma 2 är att bygga ett Retrieval Augmented Generation (RAG)-system. Låt oss skapa ett enkelt, fullständigt lokalt RAG-system med Gemma 2 och Nomic-embeddings.
Steg 1: Konfigurera miljön
Först, se till att du har de nödvändiga biblioteken installerade:
pip install langchain ollama nomic chromadb
Steg 2: Indexera dokument
Skapa en indexerare för att bearbeta dina dokument:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












