Artificiell intelligens
Ändring av känslor i videofilm med AI

Forskare från Grekland och Storbritannien har utvecklat en ny djupinlärningsmetod för att ändra uttryck och synbara humör hos människor i videofilm, samtidigt som de bevarar troheten mot deras läpprörelser i förhållande till den ursprungliga ljudinspelningen på ett sätt som tidigare försök inte har kunnat matcha.

Från videon som åtföljer artikeln (inbäddad i slutet av den här artikeln), en kort klipp av skådespelaren Al Pacino med sitt uttryck subtilt ändrat av NED, baserat på högnivåsemantiska begrepp som definierar enskilda ansiktsuttryck och deras associerade känsla. ‘Reference-Driven’-metoden till höger tar den tolkade känslan/känslorna från en källvideo och tillämpar den på hela en videosekvens. Källa: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Detta specifika område faller inom den växande kategorin deepfaked känslor, där identiteten hos den ursprungliga talaren bevaras, men deras uttryck och mikrouttryck ändras. När denna specifika AI-teknologi mognar, erbjuder den möjligheten för film- och TV-produktioner att göra subtila ändringar av skådespelares uttryck – men öppnar också upp en ganska ny kategori av ‘känsloutsatt’ videodeepfakes.
Ansiktsbyten
Ansiktsuttryck för offentliga personer, som politiker, är noggrant curatorer; 2016 hamnade Hillary Clintons ansiktsuttryck under intensiv mediegranskning för deras potentiella negativa påverkan på hennes valutsikter; ansiktsuttryck, det visar sig, är också ett ärende av intresse för FBI; och de är en kritisk indikator i jobbintervjuer, vilket gör den (långt ifrån) utsikten till en live ‘uttrycksfilter’ en önskvärd utveckling för jobbsökare som försöker passera en förhandsgranskning på Zoom.
En studie från 2005 i Storbritannien hävdade att ansiktsutseende påverkar valbeslut, medan en funktion från 2019 i Washington Post undersökte användningen av ‘ur kontext’ video klippdelning, som för närvarande är den närmaste sak som förespråkare för falska nyheter har till att faktiskt kunna ändra hur en offentlig person verkar bete sig, svara eller känna.
Mot neuralt uttrycksmanipulering
För tillfället är tillståndet i konsten att manipulera ansiktsuttryck ganska rudimentärt, eftersom det innebär att man måste tackla disentanglement av högnivåbegrepp (såsom ledsen, arg, lycklig, leende) från faktisk videoinnehåll. Även om traditionella deepfake-arkitekturer verkar uppnå denna disentanglement ganska bra, kräver spegling av känslor mellan olika identiteter fortfarande att två träningsansiktsuppsättningar innehåller matchande uttryck för varje identitet.

Typiska exempel på ansiktsbilder i dataset som används för att träna deepfakes. För närvarande kan du bara manipulera en persons ansiktsuttryck genom att skapa ID-specifika uttryck-uttryck-vägar i en deepfake-neuronnätverksarkitektur. 2017 års deepfake-programvara har ingen inbyggd, semantisk förståelse för ett ‘leende’ – den kartlägger och matchar bara upplevda förändringar i ansiktsgeometri mellan de två ämnena.
Vad som är önskvärt, och som ännu inte har uppnåtts fullständigt, är att känna igen hur ämne B (till exempel) ler, och enkelt skapa en ‘le’-knapp i arkitekturen, utan att behöva kartlägga den till en ekvivalent bild av ämne A som ler.
Den nya artikeln heter Neural Emotion Director: Speech-preserving semantic control of facial expressions in “in-the-wild” videos, och kommer från forskare vid School of Electrical & Computer Engineering vid National Technical University of Athens, Institute of Computer Science vid Foundation for Research and Technology Hellas (FORTH), och College of Engineering, Mathematics and Physical Sciences vid University of Exeter i Storbritannien.
Teamet har utvecklat ett ramverk som kallas Neural Emotion Director (NED), som inkluderar ett 3D-baserat emotion-översättningsnätverk, 3D-Based Emotion Manipulator.
NED tar emot en sekvens av uttrycksparametrar och översätter dem till en måldomän. Det tränas på oparallell data, vilket innebär att det inte är nödvändigt att träna på dataset där varje identitet har motsvarande ansiktsuttryck.
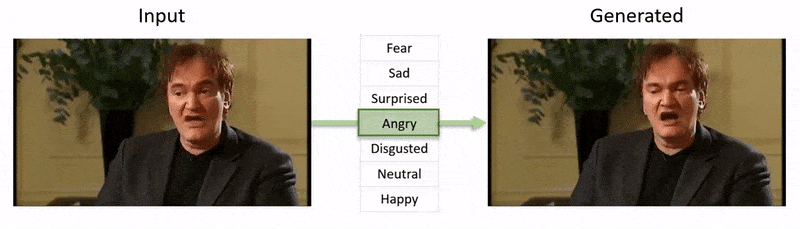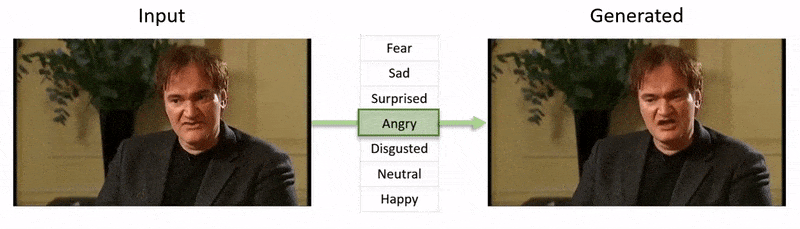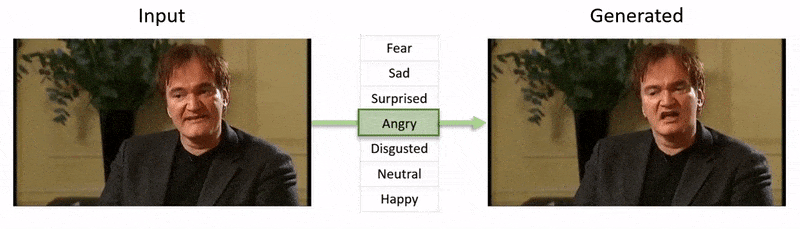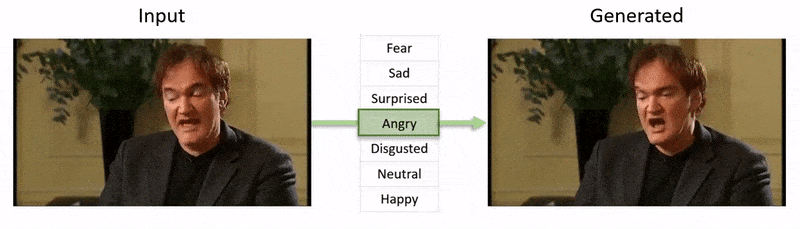
Videon, som visas i slutet av den här artikeln, går igenom en serie tester där NED påtvingar ett uppenbart emotionellt tillstånd på footage från YouTube-databasen.
Författarna hävdar att NED är den första video-baserade metoden för att ‘regissera’ skådespelare i slumpmässiga och oförutsägbara situationer, och har gjort koden tillgänglig på NED:s projektsida.
Metod och arkitektur
Systemet tränas på två stora videodataset som har annoterats med ‘känsla’-etiketter.
Utmatningen möjliggörs av en videoansiktsrenderare som renderar den önskade känslan till video med hjälp av traditionella ansiktsbildsynthetekniker, inklusive ansiktssegmentering, ansiktslandmärkesjustering och blandning, där endast ansiktsområdet syntetiseras och sedan påförs originalet.

Arkitekturen för NED-pipelinen. Källa: https://arxiv.org/pdf/2112.00585.pdf
Till en början får systemet 3D-ansiktsåtervinning och påtvingar ansiktslandmärkesjusteringar på indataframes för att identifiera uttrycket. Efter detta skickas de återvunna uttrycksparametrarna till 3D-baserade Emotion Manipulatorn, och en stilvektor beräknas med hjälp av antingen en semantisk etikett (såsom ‘lycklig’) eller en referensfil.
En referensfil är en video som visar ett visst erkänt uttryck/känsla, som sedan påförs hela målvideon, och byter ut det ursprungliga uttrycket.

Steg i emotionstransferpipelinen, med olika skådespelare som sampats från YouTube-videor.
Den slutliga genererade 3D-ansiktsformen kombineras sedan med Normalized Mean Face Coordinate (NMFC) och ögonbilder (de röda prickarna i bilden ovan), och skickas till neurala renderaren, som utför den slutliga manipulationen.
Resultat
Forskarna genomförde omfattande studier, inklusive användar- och ablationsstudier, för att utvärdera effektiviteten hos metoden jämfört med tidigare arbete, och fann att NED överträffar den nuvarande tillståndet i konsten inom denna subsektor av neural ansiktsmanipulering.

Artikelns författare förutser att senare implementationer av detta arbete, och verktyg av liknande natur, kommer att vara användbara främst inom TV- och filmindustrin, och uttalar:
‘Vår metod öppnar en mängd nya möjligheter för användbara tillämpningar av neurala renderings-teknologier, från filmefterproduktion och videospel till fotorealistiska affektiva avatarer.’
Detta är ett tidigt arbete inom området, men ett av de första som försöker ansiktsåtergestaltning med video istället för stillbilder. Även om videor i princip är många stillbilder som körs mycket snabbt, finns det temporala överväganden som gör tidigare tillämpningar av emotionstransfer mindre effektiva. I den medföljande videon och exempel i artikeln, inkluderar författarna visuella jämförelser av NED:s utmatning mot andra jämförbara metoder.

Mer detaljerade jämförelser och många fler exempel på NED kan hittas i den fullständiga videon nedan:
3 december 2021, 18:30 GMT+2 – På begäran av en av artikelförfattarna, gjordes korrigeringar avseende ‘referensfilen’, som jag felaktigt angav vara en stillbild (när den i själva verket är en videosekvens). Även en ändring av namnet på Institute of Computer Science vid Foundation for Research and Technology.
3 december 2021, 20:50 GMT+2 – En andra begäran från en av artikelförfattarna om en ytterligare ändring av namnet på den ovan nämnda institutionen.












