Tankeledare
3 sätt att hålla föråldrade fakta färska i stora språkmodeller
Stora språkmodeller (LLM) som GPT3, ChatGPT och BARD är alla på modet idag. Alla har en åsikt om hur dessa verktyg är bra eller dåliga för samhället och vad de betyder för framtiden för AI. Google fick mycket kritik för att deras nya modell BARD fick ett komplext fråga fel (lite). När de tillfrågades “Vilka nya upptäckter från rymdteleskopet James Webb kan jag berätta för min 9-åring om?” – gav chatboten tre svar, varav 2 var rätt och 1 var fel. Det felaktiga svaret var att den första “exoplanet”-bilden togs av JWST, vilket var inkorrekt. Så i grund och botten hade modellen en felaktig faktum lagrad i sin kunskapsbas. För att stora språkmodeller ska vara effektiva behöver vi ett sätt att hålla dessa fakta uppdaterade eller komplettera fakta med ny kunskap.
Låt oss först titta på hur fakta lagras inuti en stor språkmodell (LLM). Stora språkmodeller lagrar inte information och fakta på ett traditionellt sätt som databaser eller filer. Istället har de tränats på stora mängder textdata och har lärt sig mönster och relationer i den data. Detta möjliggör för dem att generera mänskliga svar på frågor, men de har ingen specifik lagringsplats för sin inhämtade information. När de svarar på en fråga använder modellen sin utbildning för att generera ett svar baserat på den indata den får. Informationen och kunskapen som en språkmodell har är ett resultat av de mönster den har lärt sig i den data den tränades på, inte ett resultat av att den uttryckligen lagras i modellens minne. Transformers-arkitekturen som de flesta moderna LLM bygger på har en intern kodning av fakta som används för att svara på frågan som ställs i prompten.

Så, om fakta inuti den interna minnet av LLM är felaktiga eller föråldrade, behöver ny information tillhandahållas via en prompt. Prompt är den text som skickas till LLM med frågan och stödjande bevis som kan vara några nya eller korrigeringar av fakta. Här är 3 sätt att närma sig detta.
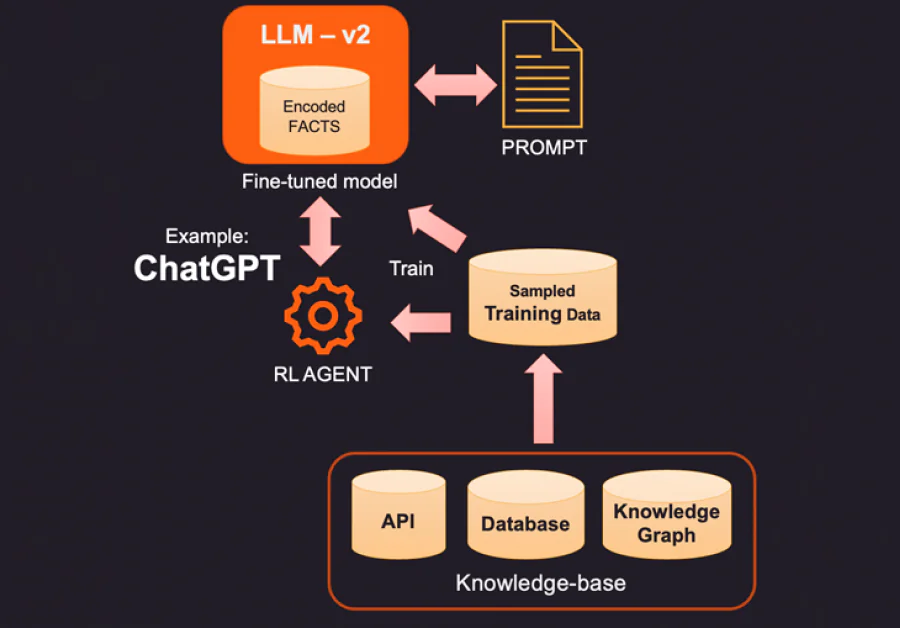
1. Ett sätt att korrigera de kodade fakta i en LLM är att tillhandahålla nya fakta som är relevanta för sammanhanget med hjälp av en extern kunskapsbas. Denna kunskapsbas kan vara API-anrop för att hämta relevant information eller en sökning i en SQL-, No-SQL- eller Vektordatabas. Mer avancerad kunskap kan extraheras från en kunskapsgraf som lagrar dataentiteter och relationer mellan dem. Beroende på den information användaren frågar efter kan den relevanta sammanhangsinformationen hämtas och ges som ytterligare fakta till LLM. Dessa fakta kan också formateras för att se ut som träningsexempel för att förbättra lärandeprocessen. Till exempel kan du skicka ett antal fråga-svarspar för att modellen ska lära sig hur den ska ge svar.

2. Ett mer innovativt (och dyrare) sätt att komplettera LLM är faktisk finjustering med hjälp av träningsdata. Istället för att fråga kunskapsbasen för specifika fakta för att lägga till, bygger vi en träningsdataset genom att sampla kunskapsbasen. Med hjälp av övervakad inlärningstekniker som finjustering kan vi skapa en ny version av LLM som tränas på denna ytterligare kunskap. Denna process är vanligtvis dyr och kan kosta ett par tusen dollar för att bygga och underhålla en finjusterad modell i OpenAI. Naturligtvis förväntas kostnaden bli billigare över tiden.
3. Ett annat alternativ är att använda metoder som förstärkt inlärning (RL) för att träna en agent med mänsklig återkoppling och lära en policy för att svara på frågor. Denna metod har varit mycket effektiv i att bygga mindre fotavtrycksmodeller som blir bra på specifika uppgifter. Till exempel var den berömda ChatGPT som släpptes av OpenAI tränad på en kombination av övervakad inlärning och RL med mänsklig återkoppling.

Sammantaget är detta ett mycket utvecklande område där varje stor företag vill komma in och visa sin differentiering. Vi kommer snart att se stora LLM-verktyg i de flesta områden som detaljhandel, hälsovård och bankväsende som kan svara på ett mänskligt sätt och förstå nyanserna i språket. Dessa LLM-baserade verktyg integrerade med företagsdata kan strömlinjeforma åtkomst och göra rätt data tillgänglig för rätt personer vid rätt tid.












