
AI 101
Kaj je prekomerno opremljanje?
Kaj je prekomerno opremljanje?
Ko trenirate nevronsko mrežo, se morate izogibati pretiranemu opremljanju. Prekomerno opremljanje je težava v okviru strojnega učenja in statistike, kjer se model predobro nauči vzorcev nabora podatkov o usposabljanju, kar odlično razloži nabor podatkov o usposabljanju, vendar ne posploši svoje napovedne moči na druge nize podatkov.
Povedano drugače, v primeru preveč opremljenega modela bo pogosto pokazal izjemno visoko natančnost nabora podatkov o usposabljanju, vendar nizko natančnost podatkov, zbranih in v prihodnosti prevoženih skozi model. To je kratka definicija prekomernega opremljanja, a poglejmo si koncept prekomernega opremljanja podrobneje. Poglejmo si, kako nastane prekomerno opremljanje in kako se mu lahko izognemo.
Razumevanje »fit« in premajhnega prileganja
Koristno je, če si ogledate koncept premajhne opreme in "fit” na splošno, ko govorimo o prekomernem opremljanju. Ko usposabljamo model, poskušamo razviti ogrodje, ki je sposobno predvideti naravo ali razred elementov v naboru podatkov na podlagi značilnosti, ki opisujejo te elemente. Model mora biti sposoben razložiti vzorec znotraj nabora podatkov in predvideti razrede prihodnjih podatkovnih točk na podlagi tega vzorca. Bolje kot model pojasnjuje razmerje med značilnostmi vadbenega nabora, bolj »fit« je naš model.
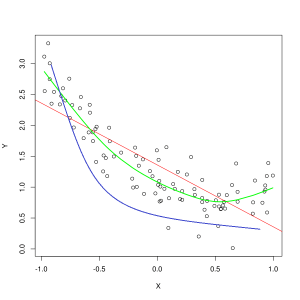
Modra črta predstavlja napovedi modela, ki ne ustreza, medtem ko zelena črta predstavlja model, ki se bolje prilega. Fotografija: Pep Roca prek Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Model, ki slabo razloži razmerje med značilnostmi podatkov o usposabljanju in tako ne uspe natančno razvrstiti prihodnjih primerov podatkov, je premalo opremljen podatke o usposabljanju. Če bi grafično prikazali predvideno razmerje neustreznega modela proti dejanskemu presečišču funkcij in oznak, bi napovedi skrenele z meje. Če bi imeli graf z označenimi dejanskimi vrednostmi vadbenega nabora, bi močno premajhen model drastično zgrešil večino podatkovnih točk. Model z boljšim prileganjem bi lahko presekal pot skozi sredino podatkovnih točk, pri čemer bi posamezne podatkovne točke le malo odstopale od predvidenih vrednosti.
Nezadostno prilagajanje se lahko pogosto pojavi, ko ni dovolj podatkov za ustvarjanje natančnega modela ali ko poskušate oblikovati linearni model z nelinearnimi podatki. Več podatkov o vadbi ali več funkcij bo pogosto pomagalo zmanjšati premajhno opremljanje.
Zakaj torej ne bi preprosto ustvarili modela, ki popolnoma razloži vsako točko v podatkih o usposabljanju? Zagotovo je zaželena popolna natančnost? Ustvarjanje modela, ki se je predobro naučil vzorcev podatkov o usposabljanju, je tisto, kar povzroča prekomerno opremljanje. Nabor podatkov o usposabljanju in drugi, prihodnji nabori podatkov, ki jih vodite skozi model, ne bodo povsem enaki. Verjetno si bosta v mnogih pogledih zelo podobna, vendar se bosta v ključnih pogledih tudi razlikovala. Zato oblikovanje modela, ki popolnoma razlaga nabor podatkov za usposabljanje, pomeni, da boste na koncu dobili teorijo o razmerju med funkcijami, ki se ne posplošuje dobro na druge nabore podatkov.
Razumevanje prekomernega opremljanja
Prekomerno opremljanje se pojavi, ko se model predobro nauči podrobnosti v naboru podatkov za usposabljanje, kar povzroči, da model trpi, ko se napovedi izvajajo na zunanjih podatkih. To se lahko zgodi, ko se model ne le nauči značilnosti nabora podatkov, temveč se nauči tudi naključnih nihanj oz. hrupa znotraj nabora podatkov, pri čemer je pomembnost teh naključnih/nepomembnih pojavov.
Če se uporabljajo nelinearni modeli, je večja verjetnost, da bo prišlo do prekomernega opremljanja, saj so bolj prilagodljivi pri učenju podatkovnih funkcij. Neparametrični algoritmi strojnega učenja imajo pogosto različne parametre in tehnike, ki jih je mogoče uporabiti za omejitev občutljivosti modela na podatke in s tem zmanjšanje prekomernega opremljanja. Kot primer, modeli odločitvenega drevesa so zelo občutljivi na prekomerno opremljanje, vendar se lahko tehnika, imenovana obrezovanje, uporabi za naključno odstranitev nekaterih podrobnosti, ki se jih je model naučil.
Če bi grafično prikazali napovedi modela na osi X in Y, bi imeli črto napovedi, ki se vije cik-cak naprej in nazaj, kar odraža dejstvo, da se je model preveč trudil, da bi vse točke v naboru podatkov prilagodil njeno razlago.
Nadzorovanje prekomernega opremljanja
Ko usposabljamo model, želimo, da model ne dela napak. Ko se zmogljivost modela približa pravilnim napovedim na vseh podatkovnih točkah v naboru podatkov o usposabljanju, postane prileganje boljše. Model z dobrim prileganjem lahko razloži skoraj ves nabor podatkov o usposabljanju brez pretiranega opremljanja.
Ko se model uri, se njegova učinkovitost sčasoma izboljša. Stopnja napak modela se bo s časom usposabljanja zmanjšala, vendar se zmanjša le do določene točke. Točka, na kateri se zmogljivost modela na preskusnem nizu začne znova povečevati, je običajno točka, na kateri pride do prekomernega opremljanja. Da bi dosegli najboljšo prilagoditev modela, želimo ustaviti model na točki najmanjše izgube na učnem nizu, preden se napaka spet začne povečevati. Optimalno točko zaustavitve lahko ugotovite tako, da grafično prikažete zmogljivost modela skozi ves čas vadbe in prekinete vadbo, ko je izguba najmanjša. Vendar pa je eno tveganje pri tej metodi nadzora za prekomerno opremljanje ta, da določanje končne točke za usposabljanje na podlagi uspešnosti preizkusa pomeni, da postanejo podatki o preskusu nekoliko vključeni v postopek usposabljanja in izgubijo svoj status popolnoma »nedotaknjenih« podatkov.
Obstaja nekaj različnih načinov, kako se lahko borite proti prekomernemu opremljanju. Eden od načinov za zmanjšanje prekomernega opremljanja je uporaba taktike ponovnega vzorčenja, ki deluje z ocenjevanjem natančnosti modela. Uporabite lahko tudi a potrjevanje nabor podatkov poleg preskusnega nabora in narišite natančnost usposabljanja glede na validacijski nabor namesto testnega nabora podatkov. Tako vaš testni nabor podatkov ostane neviden. Priljubljena metoda ponovnega vzorčenja je navzkrižna validacija K-gub. Ta tehnika vam omogoča, da svoje podatke razdelite na podnabore, na katerih se uri model, nato pa se analizira delovanje modela na podnaborih, da se oceni, kako bo model deloval na zunanjih podatkih.
Uporaba navzkrižne validacije je eden najboljših načinov za ocenjevanje natančnosti modela na nevidnih podatkih, v kombinaciji z validacijskim naborom podatkov pa je mogoče prekomerno opremljanje pogosto zmanjšati na minimum.










