Искусственный интеллект
Обучение моделей компьютерного зрения на случайном шуме вместо реальных изображений

Исследователи из лаборатории компьютерных наук и искусственного интеллекта MIT (CSAIL) экспериментировали с использованием случайных шумовых изображений в наборах данных компьютерного зрения для обучения моделей компьютерного зрения, и обнаружили, что вместо того, чтобы производить мусор, этот метод удивительно эффективен:

Генеративные модели из эксперимента, отсортированные по производительности. Source: https://openreview.net/pdf?id=RQUl8gZnN7O
Подача apparent ‘visual trash’ в популярные архитектуры компьютерного зрения не должна приводить к такому виду производительности. На дальнем правом краю изображения выше, черные столбцы представляют собой баллы точности (на Imagenet-100) для четырех ‘реальных’ наборов данных. Хотя ‘случайные шумовые’ наборы данных, предшествующие им (изображенные в различных цветах, см. индекс вверху слева), не могут сравниться с этим, они почти все находятся в пределах уважительных верхних и нижних границ (красные пунктирные линии) для точности.
В этом смысле ‘точность’ не означает, что результат обязательно выглядит как лицо, церковь, пицца или любая другая конкретная область, для которой вы можете быть заинтересованы в создании системы синтеза изображений, такой как Генеративная Соперничающая Сеть или рамка кодировщика/декодировщика.
Скорее, это означает, что модели CSAIL получили обобщенные применимые центральные ‘истины’ из изображений, которые кажутся настолько неструктурированными, что не должны быть способны их обеспечить.
Разнообразие против натурализма
Эти результаты также не могут быть объяснены переобучением: живая обсуждение между авторами и рецензентами на Open Review показывает, что смешивание разных содержаний из визуально разнообразных наборов данных (таких как ‘мертвые листья’, ‘фракталы’ и ‘процедурный шум’ – см. изображение ниже) в набор данных для обучения на самом деле улучшает точность в этих экспериментах.
Это предполагает (и это немного революционная концепция) новый тип ‘недообучения’, где ‘разнообразие’ превосходит ‘натурализм’.
Страница проекта позволяет интерактивно просматривать различные типы случайных изображений, использованных в эксперименте. Source: https://mbaradad.github.io/learning_with_noise/
Результаты, полученные исследователями, ставят под сомнение фундаментальную связь между изображениями, основанными на нейронных сетях, и ‘реальными’ изображениями, которые бросаются в них в тревожных объемах каждый год, и предполагают, что необходимость получения, курирования и других манипуляций с гипермасштабными наборами изображений может в конечном итоге стать излишней. Авторы заявляют:
‘Текущие системы зрения обучаются на огромных наборах данных, и эти наборы данных имеют стоимость: курирование дорого, они наследуют человеческие предубеждения, и есть проблемы с конфиденциальностью и правами использования. Чтобы противостоять этим затратам, интерес к обучению на более дешевых источниках данных, таких как неаннотированные изображения, резко возрос.’
‘В этой статье мы делаем шаг дальше и спрашиваем, можно ли отказаться от реальных наборов изображений совсем, обучаясь на процедурных шумовых процессах.’
Исследователи предполагают, что текущий набор архитектур машинного обучения может быть более фундаментальным (или, по крайней мере, неожиданным) из изображений, чем считалось ранее, и что ‘бессмысленные’ изображения потенциально могут передать большое количество этой информации намного дешевле, даже с возможным использованием ад хок синтетических данных, через архитектуры генерации наборов данных, которые генерируют случайные изображения во время обучения:
‘Мы определили два ключевых свойства, которые делают хорошие синтетические данные для обучения систем зрения: 1) натурализм, 2) разнообразие. Интересно, что наиболее натуралистические данные не всегда являются лучшими, поскольку натурализм может быть достигнут за счет разнообразия.
‘Факт, что натуралистические данные помогают, может не быть удивительным, и это предполагает, что действительно, большие реальные данные имеют ценность. Однако мы обнаружили, что то, что важно, не то, что данные являются реальными, а то, что они являются натуралистическими, т.е. они должны отражать определенные структурные свойства реальных данных.
‘Многие из этих свойств могут быть отражены в простых шумовых моделях.’

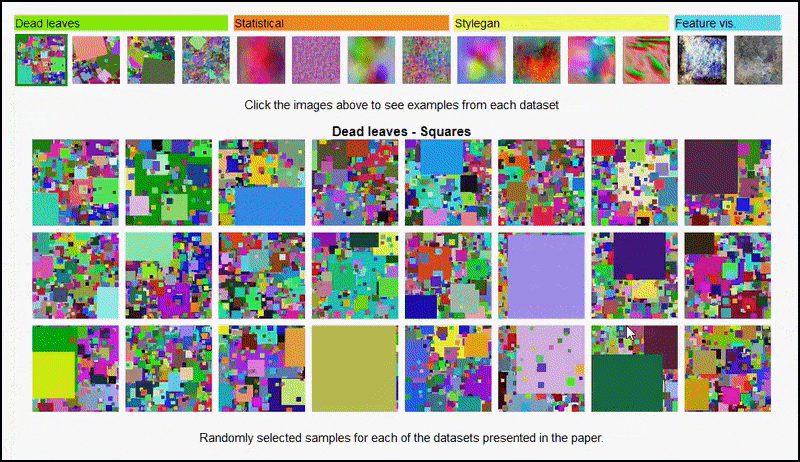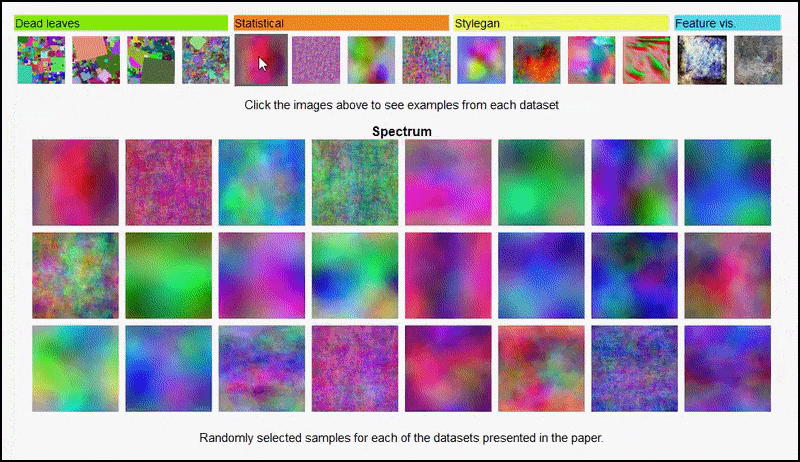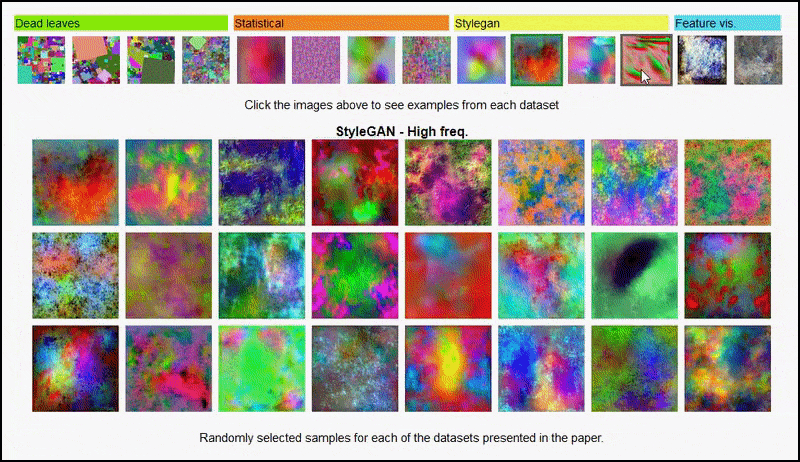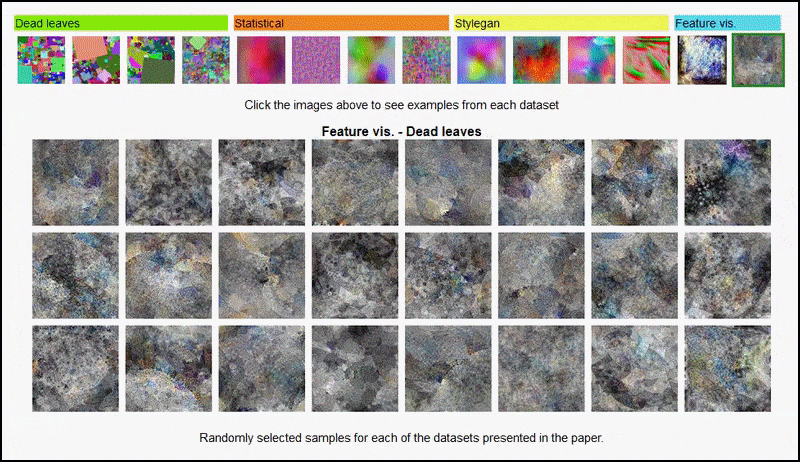
Визуализация функций, полученная из кодировщика, полученного из AlexNet, на некоторых из различных ‘случайных изображений’ наборов данных, использованных авторами, охватывающих 3-й и 5-й (финальный) свертывающий слой. Методология, использованная здесь, следует методологии, изложенной в исследовании Google AI 2017 года.
Статья Learning to See by Looking at Noise, представленная на 35-й конференции по обработке нейронной информации (NeurIPS 2021) в Сиднее, была написана шестью исследователями из CSAIL, с равным вкладом.
Работа была рекомендована консенсусом для выбора в фокусе на NeurIPS 2021, с комментариями рецензентов, характеризующими статью как ‘научный прорыв’, открывающий ‘большую область исследования’, даже если она вызывает столько же вопросов, сколько и ответов.
В статье авторы заключили:
‘Мы показали, что, когда они спроектированы с использованием результатов прошлых исследований по статистике натуральных изображений, эти наборы данных могут успешно обучать визуальные представления. Мы надеемся, что эта статья будет мотивировать изучение новых генеративных моделей, способных производить структурированный шум, достигающий еще более высокой производительности при использовании в различных визуальных задачах.
‘Будет ли возможно сравнить производительность, полученную с помощью предварительного обучения на ImageNet? Может быть, в отсутствие большого набора данных, специфичного для конкретной задачи, лучшее предварительное обучение может не использовать стандартный реальный набор данных, такой как ImageNet.’












