Лидеры мнений
Три метода сохранения конфиденциальности в машинном обучении, решающие самую важную проблему этого десятилетия
Автор: Amogh Tarcar, исследователь машинного обучения и искусственного интеллекта, Persistent Systems.
Конфиденциальность данных, по мнению экспертов из различных областей, будет самой важной проблемой этого десятилетия. Это особенно верно для машинного обучения (ML), где алгоритмам предоставляются огромные объемы данных.
Традиционно методы моделирования ML полагались на централизацию данных из нескольких источников в один центр данных. Ведь модели ML наиболее мощны, когда они имеют доступ к огромным объемам данных. Однако с этой техникой связано множество проблем с конфиденциальностью. Сбор разнообразных данных из нескольких источников сегодня менее возможен из-за регуляторных проблем, таких как HIPAA, GDPR и CCPA. Кроме того, централизация данных увеличивает объем и масштаб неправильного использования данных и угроз безопасности в виде утечек данных.
Чтобы преодолеть эти проблемы, были разработаны несколько столпов сохранения конфиденциальности в машинном обучении (PPML) с конкретными методами, которые снижают риск конфиденциальности и гарантируют, что данные остаются достаточно безопасными. Вот несколько из наиболее важных:
1. Федеративное обучение
Федеративное обучение – это метод обучения ML, который переворачивает проблему сбора данных с ног на голову. Вместо сбора данных для создания единой модели ML федеративное обучение собирает сами модели ML. Это гарантирует, что данные никогда не покидают своего источника, и позволяет нескольким сторонам сотрудничать и создавать общую модель ML без прямого обмена конфиденциальными данными.
Оно работает следующим образом. Вы начинаете с базовой модели ML, которую затем делятся с каждым клиентским узлом. Эти узлы затем выполняют локальное обучение на этой модели, используя свои собственные данные. Обновления модели периодически делятся с координаторным узлом, который обрабатывает эти обновления и объединяет их, чтобы получить новую глобальную модель. Таким образом, вы получаете информацию из различных наборов данных, не делясь этими наборами данных.

Источник: Persistent Systems
В контексте здравоохранения это невероятно мощный и конфиденциальный инструмент для сохранения безопасности данных пациентов, одновременно давая исследователям возможность использовать коллективные знания. Не собирая данные, федеративное обучение создает один дополнительный уровень безопасности. Однако сами модели и обновления моделей все еще представляют собой риск безопасности, если они остаются уязвимыми.
2. Дифференциальная конфиденциальность
Модели ML часто становятся мишенями для атак на определение принадлежности. Скажем, вы поделились своими данными здравоохранения с больницей, чтобы помочь разработать вакцину против рака. Больница сохраняет ваши данные в безопасности, но использует федеративное обучение для обучения общедоступной модели ML. Через несколько месяцев хакеры используют атаку на определение принадлежности, чтобы определить, использовались ли ваши данные для обучения модели или нет. Затем они передают информацию страховой компании, которая, исходя из вашего риска заболеть раком, может повысить ваши страховые премии.
Дифференциальная конфиденциальность гарантирует, что атаки противников на модели ML не смогут определить конкретные точки данных, использованные во время обучения, тем самым снижая риск раскрытия конфиденциальных данных при обучении моделей ML. Это достигается путем добавления “статистического шума” для нарушения данных или параметров модели ML во время обучения, что затрудняет проведение атак и определение того, были ли использованы данные конкретного человека для обучения модели.
Например, Facebook недавно выпустил Opacus, высокоскоростную библиотеку для обучения моделей PyTorch с использованием алгоритма обучения ML на основе дифференциальной конфиденциальности, называемого дифференциально-приватным стохастическим градиентным спуском (DP-SGD). Анимация ниже показывает, как он использует шум для маскировки данных.

Источник: Блог Opacus от Facebook
Этот шум управляется параметром, называемым Эпсилон. Если значение Эпсилон низкое, модель имеет идеальную конфиденциальность данных, но плохую полезность и точность. Напротив, если у вас высокое значение Эпсилон, конфиденциальность данных будет снижена, а точность увеличится. Секрет в том, чтобы найти баланс, чтобы оптимизировать оба показателя.
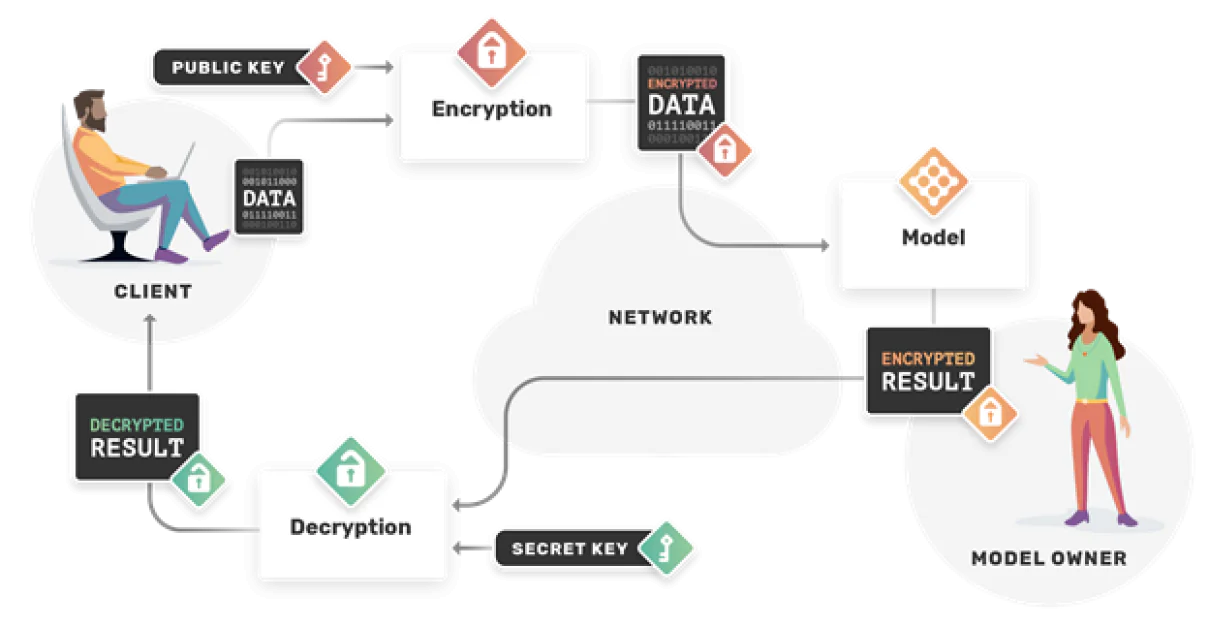
3. Гомоморфное шифрование
Стандартное шифрование традиционно несовместимо с машинным обучением, поскольку после шифрования данные больше не могут быть поняты алгоритмом ML. Однако гомоморфное шифрование – это специальный шифровальный метод, который позволяет продолжать выполнять определенные типы вычислений.

Источник: OpenMined
Сила этого заключается в том, что обучение может происходить в полностью зашифрованном пространстве. Это не только защищает владельцев данных, но и защищает владельцев моделей. Владелец модели может выполнять вывод на зашифрованных данных, не видя их и не злоупотребляя ими.
Когда это применяется к федеративному обучению, слияние обновлений моделей может происходить безопасно, поскольку они происходят в полностью зашифрованной среде, что существенно снижает риск атак на определение принадлежности.
Десятилетие конфиденциальности
Когда мы вступаем в 2021 год, сохранение конфиденциальности в машинном обучении – это возникающая область с удивительно активными исследованиями. Если прошлое десятилетие было о том, чтобы освободить данные, это десятилетие будет о том, чтобы освободить модели ML, сохраняя при этом конфиденциальность лежащих в их основе данных посредством федеративного обучения, дифференциальной конфиденциальности и гомоморфного шифрования. Эти методы представляют собой многообещающий новый способ продвижения решений машинного обучения, учитывающий конфиденциальность.












