Искусственный интеллект
Переструктуризация лиц в видео с помощью машинного обучения

Исследовательское сотрудничество между Китаем и Великобританией разработало новый метод для переструктуризации лиц в видео. Этот метод позволяет достичь убедительного расширения и сужения структуры лица, с высокой последовательностью и отсутствием артефактов.
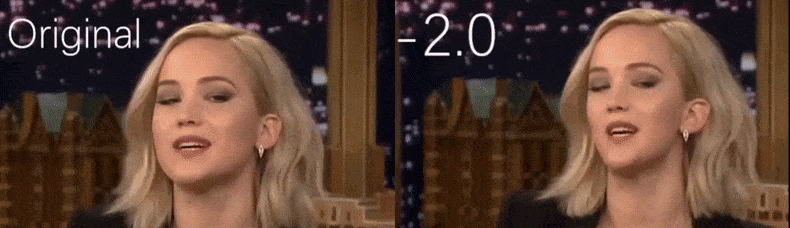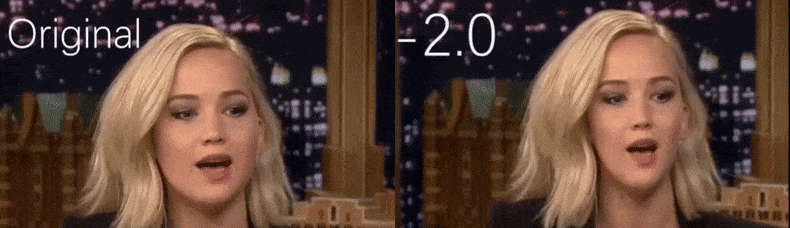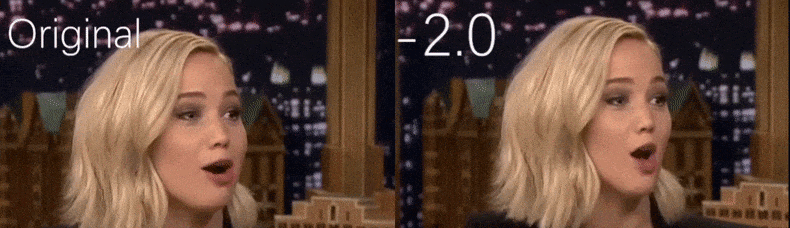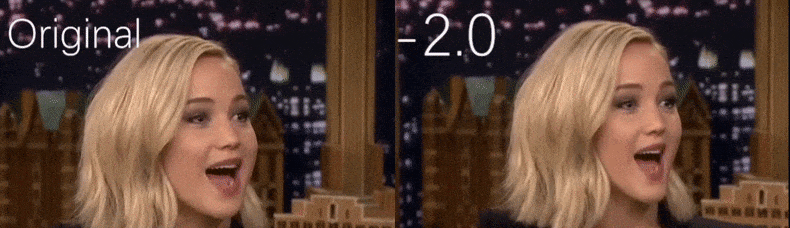
Из видео с YouTube, использованного в качестве исходного материала исследователями, актриса Дженнифер Лоуренс появляется как более худая личность (справа). См. сопровождающее видео, встроенное в нижней части статьи, для многих других примеров в лучшем разрешении. Источник: https://www.youtube.com/watch?v=tA2BxvrKvjE
Такой тип трансформации обычно возможен только с помощью традиционных методов CGI, которые потребуют полного воспроизведения лица посредством подробных и дорогих процедур захвата движения, настройки и текстурирования.
Вместо этого то, что есть в технике CGI, интегрируется в нейронную трубу как параметрическая 3D информация о лице, которая затем используется в качестве основы для рабочего процесса машинного обучения.

Традиционные параметрические лица все чаще используются в качестве руководства для трансформационных процессов, которые используют ИИ вместо CGI. Источник: https://arxiv.org/pdf/2205.02538.pdf
Авторы заявляют:
‘Наша цель – сгенерировать высококачественные портретные видео, изменяя общую форму портретных лиц в соответствии с естественной деформацией лица в реальном мире. Это можно использовать для таких применений, как генерация формы лица для красоты и усиление лица для визуальных эффектов.’
Хотя искажение и деформация лица в 2D были доступны потребителям с появлением Photoshop (и привели к странным и часто неприемлемым субкультурам вокруг деформации лица и дисморфии тела), это трудная задача в видео без использования CGI.

Размеры Марка Цукерберга расширяются и сужаются с помощью новой китайско-британской техники.
Переструктуризация тела в настоящее время является областью интенсивного интереса в секторе компьютерного зрения, главным образом из-за его потенциала в электронной коммерции моды, хотя сделать так, чтобы кто-то казался выше или скелетно разнообразным, в настоящее время является заметной проблемой.
Аналогично, изменение формы головы в видео в последовательной и убедительной манере было предметом предыдущей работы исследователей, хотя это реализация страдала от артефактов и других ограничений. Новая система расширяет возможности этой предыдущей работы с статического на видео-выход.
Новая система была обучена на настольном компьютере с AMD Ryzen 9 3950X и 32 ГБ оперативной памяти и использует алгоритм оптического потока из OpenCV для карт движения, сглаженных с помощью StructureFlow фреймворка; сеть выравнивания лица (FAN) компонент для оценки ориентиров, который также используется в популярных пакетах deepfakes; и Ceres Solver для решения задач оптимизации.

Крайний пример расширения лица с помощью новой системы.
Статья озаглавлена Параметрическая переструктуризация портретов в видео и исходит от трех исследователей из Университета Чжэцзяна и одного из Университета Бата.
О лице
Под новой системой видео извлекается в последовательность изображений, и сначала оценивается жесткая поза для каждого лица. Затем представительное количество последующих кадров оценивается совместно для построения последовательных параметров идентичности на протяжении всей последовательности изображений (т.е. кадров видео).

Архитектурный поток системы искажения лица.
После этого оценивается выражение, в результате чего получается параметр переструктуризации, который реализуется с помощью линейной регрессии. Далее новый подход с функцией подписанного расстояния (SDF) строит плотную 2D-карту лицевых линий до и после переструктуризации.
Наконец, выполняется оптимизация контента-осведомленного искажения на выходном видео.
Параметрические лица
Процесс использует 3D-модель морфабельного лица (3DMM), которая все чаще становится популярным дополнением к нейронным и GAN-основанным системам синтеза лица, а также применимым для систем обнаружения deepfakes.

Не из новой статьи, но пример 3D-модели морфабельного лица (3DMM) – параметрической прототипной лица, используемой в новом проекте. Вверху слева, применение ориентиров на 3DMM-лице. Вверху справа, 3D-вершины сетки изомапы. Внизу слева показано подгонка ориентиров; в центре внизу, изомапа извлеченной текстуры лица; и вправо внизу, результирующее подгонка и форма. Источник: http://www.ee.surrey.ac.uk/CVSSP/Publications/papers/Huber-VISAPP-2016.pdf
Поток работы новой системы должен учитывать случаи окклюзии, такие как случай, когда субъект отворачивается. Это одна из самых больших проблем в программном обеспечении deepfakes, поскольку ориентиры FAN имеют мало возможностей для учета этих случаев и склонны ухудшаться в качестве, когда лицо отворачивается или окклюзируется.
Новая система может избежать этой ловушки, определяя энергию контура, которая способна соответствовать границе между 3D-лицом (3DMM) и 2D-лицом (определенным ориентирами FAN).
Оптимизация
Полезным развертыванием такой системы было бы реализовать реальное время деформации, например, в фильтрах видеочата. Текущий фреймворк не позволяет этого, и вычислительные ресурсы, необходимые для этого, сделали бы ‘живую’ деформацию заметной проблемой.
Согласно статье, и предполагая цель видео 24 кадра в секунду, операции с кадрами в трубопроводе представляют задержку 16,344 секунды для каждой секунды кадров, с дополнительными единовременными ударами для оценки идентичности и деформации лица 3D (321 мс и 160 мс, соответственно).
Следовательно, оптимизация является ключом к прогрессу в снижении задержки. Поскольку совместная оптимизация по всем кадрам добавит серьезную нагрузку на процесс, а оптимизация init-стиля (предполагая последовательную идентичность диктора из первого кадра) может привести к аномалиям, авторы приняли скудную схему для расчета коэффициентов кадров, отобранных на практических интервалах.
Затем выполняется совместная оптимизация на этом подмножестве кадров, что приводит к более экономному процессу реконструкции.
Искажение лица
Техника искажения, используемая в проекте, является адаптацией работы авторов 2020 года Глубокие портреты (DSP).

Глубокие портреты, представленные на ACM Multimedia. Статья возглавляется исследователями из ZJU-Tencent Game и Intelligent Graphics Innovation Technology Joint Lab. Источник: http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
Авторы отмечают ‘Мы расширяем этот метод от переструктуризации одного моноокулярного изображения до переструктуризации всей последовательности изображений.’
Тесты
Статья отмечает, что не было сравнимого предыдущего материала, с которым можно было бы оценить новый метод. Следовательно, авторы сравнили кадры своего искаженного видео-выхода с статическим выходом DSP.

Тестирование новой системы против статических изображений из Глубоких портретов.
Авторы отмечают, что артефакты возникают из метода DSP, из-за использования скудного отображения – проблему, которую новая система решает с помощью плотного отображения. Кроме того, видео, произведенное DSP, статья утверждает, демонстрирует отсутствие плавности и визуальной согласованности.
Авторы заявляют:
‘Результаты показывают, что наш подход может надежно производить согласованные переструктурированные портретные видео, в то время как метод, основанный на изображении, легко может привести к заметным артефактам мигания.’
Проверьте сопровождающее видео ниже, для более примеров:
Опубликовано впервые 9 мая 2022 года. Исправлено 18:00 EET, заменено ‘поле’ на ‘функцию’ для SDF.












