Искусственный интеллект
MagicDance: создание реалистичного видео человеческого танца

Компьютерное зрение — одна из наиболее обсуждаемых областей в индустрии искусственного интеллекта благодаря его потенциальному применению для решения широкого спектра задач в реальном времени. В последние годы системы компьютерного зрения быстро развивались: современные модели теперь способны анализировать черты лица, объекты и многое другое в сценариях реального времени. Несмотря на эти возможности, передача движений человека остается серьезной проблемой для моделей компьютерного зрения. Эта задача включает в себя перенаправление движений лица и тела с исходного изображения или видео на целевое изображение или видео. Передача движений человека широко используется в моделях компьютерного зрения для стилизации изображений или видео, редактирования мультимедийного контента, цифрового человеческого синтеза и даже генерации данных для структур, основанных на восприятии.
В этой статье мы сосредоточимся на MagicDance, модели, основанной на диффузии, призванной совершить революцию в передаче движений человека. Платформа MagicDance специально предназначена для переноса 2D-выражений и движений человеческого лица в сложные видеоролики о танцах людей. Его цель — создать новые танцевальные видеоролики с последовательностями поз для конкретных целевых личностей, сохраняя при этом исходную идентичность. В системе MagicDance используется двухэтапная стратегия обучения, в которой основное внимание уделяется распутыванию движений человека и таким факторам внешнего вида, как тон кожи, выражение лица и одежда. Мы углубимся в фреймворк MagicDance, изучим его архитектуру, функциональность и производительность по сравнению с другими современными фреймворками для передачи движений человека. Давайте погрузимся.
MagicDance: реалистичная передача движений человека
Как упоминалось ранее, передача движений человека является одной из самых сложных задач компьютерного зрения из-за огромной сложности, связанной с передачей движений и выражений человека из исходного изображения или видео в целевое изображение или видео. Традиционно системы компьютерного зрения обеспечивали передачу движений человека путем обучения генеративной модели для конкретной задачи, включая GAN или Генеративные состязательные сети на целевых наборах данных по выражению лица и позам тела. Хотя обучение и использование генеративных моделей в некоторых случаях дают удовлетворительные результаты, они обычно страдают от двух основных ограничений.
- Они в значительной степени полагаются на компонент деформации изображения, в результате чего им часто сложно интерполировать части тела, невидимые на исходном изображении, либо из-за изменения перспективы, либо из-за самоокклюзии.
- Они не могут обобщать изображения, полученные из внешних источников, что ограничивает их применение, особенно в реальных сценариях реального времени.

Современные модели диффузии продемонстрировали исключительные возможности генерации изображений в различных условиях, а модели диффузии теперь способны предоставлять мощные визуальные эффекты для решения множества последующих задач, таких как создание видео и рисование изображений, путем обучения на наборах данных изображений в веб-масштабе. Благодаря своим возможностям диффузионные модели могут быть идеальным выбором для задач передачи движений человека. Хотя диффузионные модели могут быть реализованы для передачи движений человека, они имеют некоторые ограничения либо с точки зрения качества создаваемого контента, либо с точки зрения сохранения идентичности, либо с точки зрения временных несоответствий в результате ограничений стратегии дизайна и обучения. Кроме того, модели, основанные на диффузии, не демонстрируют существенных преимуществ перед ГАН-фреймворки с точки зрения обобщаемости.
Чтобы преодолеть препятствия, с которыми сталкиваются фреймворки на основе диффузии и GAN при решении задач передачи движений человека, разработчики представили MagicDance, новую среду, целью которой является использование потенциала фреймворков диффузии для передачи движений человека, демонстрируя беспрецедентный уровень сохранения идентичности, превосходное визуальное качество, и обобщаемость предметной области. По своей сути, фундаментальная концепция платформы MagicDance состоит в том, чтобы разделить проблему на два этапа: контроль внешнего вида и контроль движения, две возможности, необходимые платформам распространения изображений для обеспечения точных результатов передачи движения.

На рисунке выше представлен краткий обзор фреймворка MagicDance. Как видно, фреймворк использует Модель стабильной диффузии, а также развертывает два дополнительных компонента: Модель управления внешним видом и Pose ControlNet, где первый обеспечивает руководство по внешнему виду для модели SD из эталонного изображения посредством внимания, тогда как второй обеспечивает руководство по выражению/позе для модели диффузии из условного изображения или видео. В рамках также используется многоступенчатая стратегия обучения для эффективного изучения этих подмодулей и разделения контроля позы и внешнего вида.
Подводя итог, можно сказать, что фреймворк MagicDance представляет собой
- Новая и эффективная система, состоящая из контроля позы без распутывания внешнего вида и предварительной тренировки по контролю внешнего вида.
- Платформа MagicDance способна генерировать реалистичные выражения лица и движения человека под контролем входных данных о позе и эталонных изображений или видео.
- Платформа MagicDance направлена на создание согласованного по внешнему виду человеческого контента путем введения модуля Multi-Source Attention, который предлагает точное руководство для платформы Stable Diffusion UNet.
- Фреймворк MagicDance также может использоваться как удобное расширение или плагин для фреймворка Stable Diffusion, а также обеспечивает совместимость с существующими весами моделей, поскольку не требует дополнительной тонкой настройки параметров.
Кроме того, платформа MagicDance демонстрирует исключительные возможности обобщения как внешнего вида, так и движения.
- Обобщение внешнего вида. Платформа MagicDance демонстрирует превосходные возможности, когда дело доходит до создания разнообразного внешнего вида.
- Обобщение движений: платформа MagicDance также способна генерировать широкий диапазон движений.
MagicDance: цели и архитектура
Для данного эталонного изображения реального человека или стилизованного изображения основная цель платформы MagicDance — сгенерировать выходное изображение или выходное видео, обусловленное входными данными и входными данными позы {P, F}, где P представляет позу человека. скелет, а F представляет ориентиры лица. Сгенерированное выходное изображение или видео должно сохранять внешний вид и личность участвующих людей, а также фоновое содержимое, присутствующее в эталонном изображении, сохраняя при этом позу и выражения, определенные входными данными позы.
Архитектура
Во время обучения платформа MagicDance обучается как задача реконструкции кадра, чтобы восстановить основную истину с помощью эталонного изображения и входных данных позы, полученных из того же эталонного видео. Во время тестирования передачи движения входные данные позы и эталонное изображение берутся из разных источников.
Общую архитектуру платформы MagicDance можно разделить на четыре категории: предварительный этап, предварительная тренировка контроля внешнего вида, контроль позы без учета внешнего вида и модуль движения.
Предварительный этап
Модели скрытой диффузии или LDM представляют собой уникально разработанные модели диффузии, работающие в скрытом пространстве, чему способствует использование автокодировщика, а структура стабильной диффузии является ярким примером LDM, в которых используется векторная квантованная вариационная модель. Автоэнкодер и временная архитектура U-Net. Модель Stable Diffusion использует преобразователь на основе CLIP в качестве кодировщика текста для обработки текстовых входных данных путем преобразования текстовых входных данных во встраивания. Фаза обучения платформы Stable Diffusion подвергает модель текстовому условию и входному изображению с помощью процесса, включающего кодирование изображения в скрытое представление, и подвергает ее заранее определенной последовательности шагов диффузии, управляемых методом Гаусса. Результирующая последовательность дает зашумленное скрытое представление, которое обеспечивает стандартное нормальное распределение, при этом основной целью обучения структуры Stable Diffusion является итеративное шумоподавление зашумленных скрытых представлений в скрытые представления.
Предварительная тренировка по контролю внешнего вида
Основной проблемой исходной среды ControlNet является ее неспособность последовательно контролировать внешний вид среди пространственно изменяющихся движений, хотя она имеет тенденцию генерировать изображения с позами, очень похожими на позы во входном изображении, при этом на общий внешний вид преимущественно влияют текстовые входные данные. Хотя этот метод работает, он не подходит для передачи движения, включающей задачи, в которых не текстовые входные данные, а эталонное изображение служит основным источником информации о внешнем виде.
Модуль предварительного обучения контролю внешнего вида в платформе MagicDance разработан как вспомогательная ветвь, предоставляющая рекомендации по контролю внешнего вида при поэтапном подходе. Вместо того, чтобы полагаться на ввод текста, весь модуль фокусируется на использовании атрибутов внешнего вида из эталонного изображения с целью повышения способности платформы точно генерировать характеристики внешнего вида, особенно в сценариях, включающих сложную динамику движения. Более того, только модель контроля внешнего вида поддается обучению во время предварительного обучения контролю внешнего вида.
Контроль позы без учета внешнего вида
Простое решение для управления позой на выходном изображении — это интеграция предварительно обученной модели ControlNet с предварительно обученной моделью управления внешним видом напрямую без тонкой настройки. Однако интеграция может привести к тому, что фреймворк будет испытывать проблемы с контролем позы, не зависящим от внешнего вида, что может привести к несоответствию между входными и сгенерированными позами. Чтобы устранить это несоответствие, платформа MagicDance настраивает модель Pose ControlNet совместно с предварительно обученной моделью управления внешним видом.
Модуль движения
При совместной работе сеть управления позой, разделенная на внешний вид, и модель управления внешним видом могут обеспечить точную и эффективную передачу изображения в движение, хотя это может привести к временной несогласованности. Чтобы обеспечить временную согласованность, платформа интегрирует дополнительный модуль движения в основную архитектуру Stable Diffusion UNet.
MagicDance: предварительная подготовка и наборы данных
Для предварительного обучения платформа MagicDance использует набор данных TikTok, который состоит из более чем 350 танцевальных видеороликов различной длины от 10 до 15 секунд, на которых запечатлен танцующий один человек, причем большинство этих видеороликов содержат лицо и верхнюю часть тела. человек. Платформа MagicDance извлекает каждое отдельное видео со скоростью 30 кадров в секунду и запускает OpenPose для каждого кадра индивидуально, чтобы определить скелет позы, позы рук и ориентиры лица.
Для предварительного обучения модель управления внешним видом предварительно обучается с размером пакета 64 на 8 графических процессорах NVIDIA A100 за 10 тысяч шагов с размером изображения 512 x 512 с последующей совместной точной настройкой моделей управления позой и внешним видом с помощью размер пакета 16 на 20 тысяч шагов. Во время обучения платформа MagicDance случайным образом выбирает два кадра в качестве целевого и эталонного соответственно, при этом изображения обрезаются в одном и том же положении по одной и той же высоте. Во время оценки модель обрезает изображение по центру, а не в случайном порядке.
MagicDance : Результаты
Результаты экспериментов, проведенные с использованием платформы MagicDance, показаны на следующем изображении. Как видно, платформа MagicDance превосходит существующие платформы, такие как Disco и DreamPose, в передаче движений человека по всем показателям. Фреймворки, содержащие «*» перед своим именем, используют целевое изображение непосредственно в качестве входных данных и включают больше информации по сравнению с другими фреймворками.
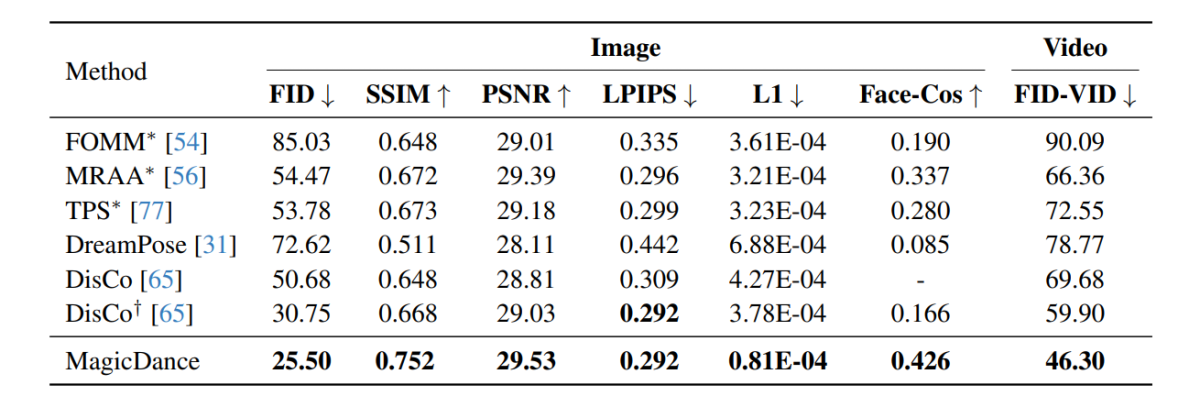
Интересно отметить, что фреймворк MagicDance достигает показателя Face-Cos 0.426, что на 156.62% лучше, чем у фреймворка Disco, и почти на 400% выше по сравнению с фреймворком DreamPose. Результаты указывают на надежную способность платформы MagicDance сохранять идентификационную информацию, а видимый прирост производительности указывает на превосходство платформы MagicDance над существующими современными методами.
На следующих рисунках сравнивается качество генерации человеческого видео в платформах MagicDance, Disco и TPS. Как можно заметить, результаты, полученные с помощью фреймворков GT, Disco и TPS, страдают от противоречивой идентичности человеческой позы и выражения лица.

Кроме того, на следующем изображении показана визуализация выражения лица и переноса позы человека в наборе данных TikTok с использованием платформы MagicDance, способной генерировать реалистичные и яркие выражения и движения под различными ориентирами лица и входными данными скелета позы, при этом точно сохраняя идентификационную информацию из эталонных входных данных. изображение.

Стоит отметить, что платформа MagicDance может похвастаться исключительными возможностями обобщения для эталонных изображений невидимых поз и стилей, находящихся за пределами домена, с впечатляющей управляемостью внешнего вида даже без какой-либо дополнительной тонкой настройки в целевой области, результаты продемонстрированы на следующем изображении. .

Следующие изображения демонстрируют возможности визуализации платформы MagicDance с точки зрения передачи выражения лица и движения человека с нулевого кадра. Как можно видеть, структура MagicDance прекрасно обобщает движения человека в дикой природе.

MagicDance: ограничения
OpenPose является важным компонентом платформы MagicDance, поскольку он играет решающую роль в управлении позой, существенно влияя на качество и временную согласованность генерируемых изображений. Однако фреймворку MagicDance по-прежнему сложно обнаружить ориентиры на лицах и точно позиционировать скелеты, особенно когда объекты на изображениях частично видны или демонстрируют быстрое движение. Эти проблемы могут привести к появлению артефактов в сгенерированном изображении.
Заключение
В этой статье мы говорили о MagicDance, модели, основанной на диффузии, которая призвана произвести революцию в передаче движений человека. Платформа MagicDance пытается перенести 2D-выражения и движения человеческого лица в сложные видеоролики о танцах людей с конкретной целью создания новых видеороликов о танцах человека на основе позы для конкретных целевых идентичностей, сохраняя при этом идентичность постоянной. Система MagicDance представляет собой двухэтапную стратегию обучения распутыванию движений человека и его внешнему виду, например, тону кожи, выражению лица и одежде.
MagicDance — это новый подход, облегчающий создание реалистичного человеческого видео за счет передачи выражений лица и движений, а также обеспечивающий единообразную генерацию анимации без необходимости какой-либо дальнейшей тонкой настройки, что демонстрирует значительное преимущество по сравнению с существующими методами. Кроме того, платформа MagicDance демонстрирует исключительные возможности обобщения сложных последовательностей движений и разнообразных человеческих личностей, что делает платформу MagicDance лидером в области передачи движения с помощью искусственного интеллекта и генерации видео.












