
Искусственный интеллект
DALL-E 2 просто «склеивает вещи вместе», не понимая их взаимосвязей?

В новой исследовательской работе Гарвардского университета предполагается, что захватывающая заголовки платформа OpenAI для преобразования текста в изображение DALL-E 2 испытывает заметные трудности в воспроизведении даже взаимосвязей на младенческом уровне между элементами, которые она объединяет в синтезированные фотографии, несмотря на ослепительную изощренность большинства из них. его выход.
Исследователи провели пользовательское исследование с участием 169 краудсорсинговых участников, которым были представлены изображения DALL-E 2, основанные на самых основных человеческих принципах семантики отношений, вместе с текстовыми подсказками, которые их создали. Когда его спросили, связаны ли подсказки и изображения, менее 22% изображений были восприняты как относящиеся к связанным с ними подсказкам с точки зрения очень простых отношений, которые DALL-E 2 попросили визуализировать.

Скриншот испытаний, проведенных для новой бумаги. Участникам было поручено выбрать все изображения, соответствующие подсказке. Несмотря на отказ от ответственности в нижней части интерфейса, во всех случаях изображения, без ведома участников, фактически были созданы из отображаемой связанной подсказки. Источник: https://arxiv.org/pdf/2208.00005.pdf
Результаты также показывают, что очевидная способность DALL-E объединять разрозненные элементы может уменьшаться, поскольку эти элементы становятся менее вероятными в реальных данных обучения, на которых работает система.
Например, изображения для подсказки «ребенок, касающийся миски» получили уровень согласия 87% (т. е. участники нажали на большинство изображений, имеющих отношение к подсказке), в то время как аналогичные фотореалистичные изображения «обезьяны, касающейся игуаны» достигли только 11% согласия:


DALL-E изо всех сил пытается изобразить маловероятное событие «прикосновения обезьяны к игуане», возможно, потому, что это редкость, а скорее всего, не существует в тренировочном наборе.
Во втором примере DALL-E 2 часто ошибается в масштабе и даже видах, предположительно из-за нехватки реальных изображений, изображающих это событие. Напротив, разумно ожидать большого количества обучающих фотографий, связанных с детьми и едой, и что этот поддомен/класс хорошо развит.
Сложность DALL-E в сопоставлении дико контрастирующих элементов изображения предполагает, что публика в настоящее время настолько ослеплена фотореалистичными и широкими интерпретационными возможностями системы, что не развила критического взгляда на случаи, когда система просто резко «приклеила» один элемент к другому. , как в этих примерах с официального сайта DALL-E 2:

Синтез вырезания и вставки из официальных примеров для DALL-E 2. Источник: https://openai.com/dall-e-2/
В новой статье говорится*:
«Понимание отношений — фундаментальный компонент человеческого интеллекта, который проявляется на ранней стадии развития, и вычисляется быстро и автоматически в восприятии.
DALL-E 2 испытывает трудности даже с базовыми пространственными отношениями (такими как in, on, недооценивают ее) предполагает, что независимо от того, чему он научился, он еще не научился тем видам репрезентаций, которые позволяют людям так гибко и надежно структурировать мир.
«Прямая интерпретация этой трудности заключается в том, что такие системы, как DALL-E 2, еще не обладают реляционной композиционностью».
Авторы предполагают, что системы генерации изображений с текстовым управлением, такие как серия DALL-E, могут выиграть от использования алгоритмов, общих для робототехники, которые одновременно моделируют идентичность и отношения, из-за необходимости, чтобы агент фактически взаимодействовал с окружающей средой, а не просто фабриковал. смесь различных элементов.
Один из таких подходов под названием CLIPort, использует тот же КЛИП-механизм который служит элементом оценки качества в DALL-E 2:
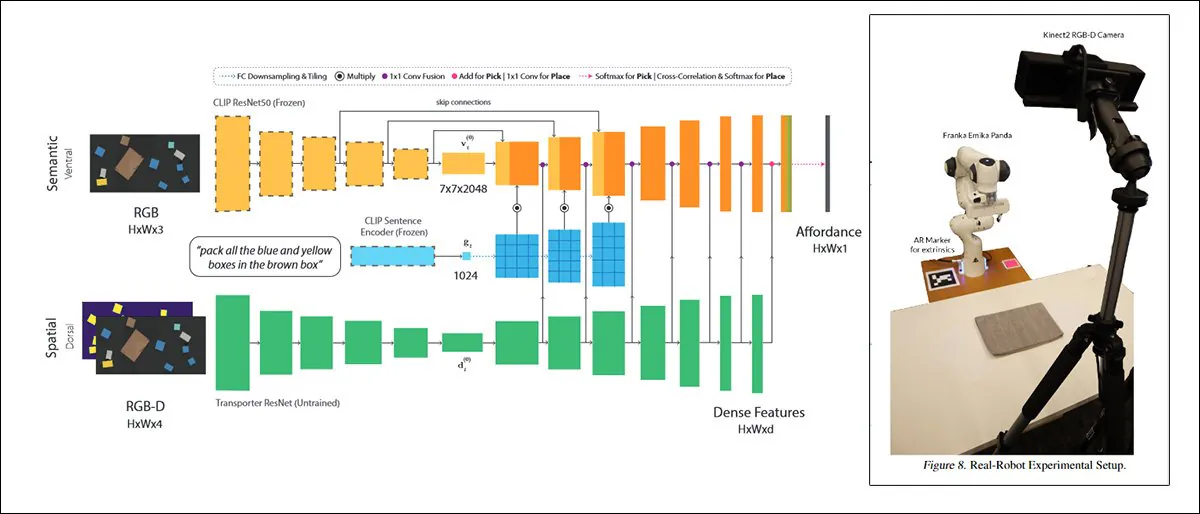
CLIPort, совместная работа Вашингтонского университета и NVIDIA в 2021 году, использует CLIP в настолько практическом контексте, что системы, обученные на нем, обязательно должны развивать понимание физических отношений, мотиватор, отсутствующий в DALL-E 2 и подобных «фантастических» каркасы синтеза изображений. Источник: https://arxiv.org/pdf/2109.12098.pdf
Авторы также предполагают, что «еще одно вероятное обновление» может состоять в том, чтобы архитектура систем синтеза изображений, таких как DALL-E, включала мультипликативные эффекты на единственном уровне вычислений, позволяющем вычислять отношения способом, вдохновленным возможностями обработки информации биологический системы.
Территория Новый документ называется Тестирование реляционного понимания при генерации изображений с текстовым управлением, и исходит от Колина Конуэлла и Томера Д. Уллмана с факультета психологии Гарварда.
Помимо ранней критики
Комментируя «ловкость рук», стоящую за реализмом и целостностью вывода DALL-E 2, авторы отмечают предыдущие работы, в которых были обнаружены недостатки в системах генеративного изображения в стиле DALL-E.
В июне этого года UoC Berkeley отметил, сложность DALL-E в обработке отражений и теней; В том же месяце исследование из Кореи исследовало «уникальность» и оригинальность вывода в стиле DALL-E 2. с критическим взглядом; предварительный анализ изображений DALL-E 2 вскоре после запуска из Нью-Йоркского университета и Техасского университета обнаружили различные проблемы с композиционностью и другими важными факторами в изображениях DALL-E 2; и последний месяц, совместная работа между Университетом Иллинойса и Массачусетским технологическим институтом предложили предложения по архитектурным улучшениям таких систем с точки зрения композиционности.
Исследователи также отмечают, что светила DALL-E, такие как Адитья Рамеш, уступил проблемы фреймворка с привязкой, относительным размером, текстом и другими проблемами.
Разработчики конкурирующей с Google системы синтеза изображений Imagen также предложили DrawBench, новая система сравнения, которая измеряет точность изображений в рамках различных метрик.
Вместо этого авторы новой статьи предполагают, что лучший результат можно было бы получить, сопоставив человеческую оценку — а не междоусобные алгоритмические метрики — с полученными изображениями, чтобы установить, в чем заключаются слабые места и что можно сделать, чтобы их смягчить.
Исследование
С этой целью новый проект основывает свой подход на психологических принципах и стремится отступить от нынешних всплеск интереса in быстрый инжиниринг (что, по сути, является уступкой недостаткам DALL-E 2 или любой аналогичной системы), для исследования и потенциального устранения ограничений, которые делают необходимыми такие «обходные пути».
В документе говорится:
«Текущая работа сосредоточена на наборе из 15 основных отношений, ранее описанных, исследованных или предложенных в когнитивной, развивающей или лингвистической литературе. Набор содержит как обоснованные пространственные отношения (например, «X на Y»), так и более абстрактные агентные отношения (например, «X помогает Y»).
«Подсказки намеренно просты, без сложности атрибутов или разработки. То есть вместо подсказки типа «ослик и осьминог играют в игру». Осел держит веревку за один конец, осьминог держится за другой. Ослик держит веревку во рту. Кошка прыгает через веревку», мы используем «ящик на ноже».
«Простота по-прежнему охватывает широкий спектр отношений из различных подобластей человеческой психологии и делает потенциальные неудачи модели более яркими и конкретными».
Для своего исследования авторы набрали 169 участников из Prolific, все из США, средний возраст 33 года, 59% женщин.
Участникам было показано 18 изображений, организованных в сетку 3×6 с подсказкой вверху и заявлением об отказе от ответственности внизу, в котором говорилось, что все, некоторые или ни одно из изображений могло быть сгенерировано из отображаемой подсказки, а затем их попросили выберите изображения, которые, по их мнению, были связаны таким образом.
Образы, представленные индивидуумам, были основаны на лингвистической, развивающей и когнитивной литературе и включали набор из восьми физических и семи «агентных» отношений (это станет ясно через мгновение).
Физические отношения
в, на, под, прикрывая, рядом, загораживая, нависая над, и связанный с.
Агентские отношения
толкать, тянуть, трогать, бить, пинать, помогать, и задерживающей.
Все эти отношения были взяты из ранее упомянутых областей исследования, не связанных с CS.
Таким образом, для использования в подсказках были получены двенадцать сущностей с шестью объектами и шестью агентами:
Объекты
коробка, цилиндр, одеяло, чаша, чашка, и нож.
Агент
мужчина, женщина, ребенок, робот, обезьяна, и игуана.
(Исследователи признают, что включение игуаны, не являющейся опорой сухих социологических или психологических исследований, было «удовольствием»).
Для каждого отношения было создано пять разных подсказок путем пятикратной случайной выборки двух объектов, в результате чего было получено 75 подсказок, каждая из которых была отправлена в DALL-E 2, и для каждой из которых использовались исходные 18 предоставленных изображений без изменений. или разрешены вторые шансы.
Результаты
В документе указано*:
«Участники в среднем сообщили о низком уровне совпадения между изображениями DALL-E 2 и подсказками, использованными для их создания, со средним значением 22.2% [18.3, 26.6] по 75 различным подсказкам.
«Агентские подсказки, в среднем 28.4% [22.8, 34.2] по 35 подсказкам, вызвали более высокое согласие, чем физические подсказки, в среднем 16.9% [11.9, 23.0] по 40 подсказкам».

Результаты исследования. Черные точки обозначают все подсказки, каждая точка - отдельная подсказка, а цвет распределяется в зависимости от того, был ли субъект подсказки агентным или физическим (т.е. объектом).
Чтобы сравнить разницу между человеческим и алгоритмическим восприятием изображений, исследователи прогнали свои рендеры через открытый исходный код OpenAI. ВиТ-Л/14 Фреймворк на основе CLIP. Усредняя оценки, они обнаружили «умеренную взаимосвязь» между двумя наборами результатов, что, возможно, удивительно, учитывая степень, в которой сам CLIP помогает генерировать изображения.

Результаты сравнения CLIP (ViT-L/14) с ответами человека.
Исследователи предполагают, что другие механизмы в архитектуре, возможно, в сочетании со случайным преобладанием (или отсутствием) данных в обучающей выборке, могут объяснить то, как CLIP может распознавать ограничения DALL-E, не имея возможности во всех случаях что-либо сделать. много о проблеме.
Авторы приходят к выводу, что DALL-E 2 имеет только условную способность, если таковая имеется, воспроизводить изображения, которые включают понимание отношений, фундаментальную грань человеческого интеллекта, которая развивается в нас очень рано.
«Мысль о том, что такие системы, как DALL-E 2, не обладают композиционностью, может удивить любого, кто видел поразительно разумные ответы DALL-E 2 на такие запросы, как «мультфильм о маленьком дайконе в балетной пачке, выгуливающем пуделя». Подобные подсказки часто создают разумное приближение к композиционной концепции, при этом все части подсказок присутствуют и находятся в нужных местах.
«Однако композиционность — это не только способность склеивать вещи — даже вещи, которые вы, возможно, никогда раньше не наблюдали вместе. Композиционность требует понимания условиями, которые связывают вещи вместе. Отношения — это такие правила».
Человек кусает тираннозавра
Обзор Поскольку OpenAI охватывает большее количество пользователей после недавней бета-монетизации DALL-E 2 и поскольку теперь за большинство поколений приходится платить, недостатки в понимании отношений DALL-E 2 могут стать более очевидными, поскольку каждая «неудачная» попытка имеет финансовый вес, а возврат невозможен.
У тех из нас, кто получил приглашение немного раньше, было время (и до недавнего времени больше свободного времени, чтобы поиграть с системой), чтобы наблюдать некоторые «сбои в отношениях», которые может излучать DALL-E 2.
Например, для Jurassic Park Фанат, очень сложно заставить динозавра преследовать человека в DALL-E 2, даже несмотря на то, что понятие «погоня» отсутствует в DALL-E 2. система цензуры, и хотя долгая история фильмов о динозаврах должны предоставить множество обучающих примеров (по крайней мере, в виде трейлеров и рекламных роликов) для этой невозможной в противном случае встречи видов.

Типичный ответ DALL-E 2 на подсказку «Цветная фотография тираннозавра, преследующего человека по дороге». Источник: ДАЛЛ-Э 2
Я обнаружил, что изображения выше типичны для вариаций на «[динозавр] преследует [человека]» дизайн подсказки, и что никакая проработка подсказки не может заставить T-Rex действительно соответствовать требованиям. На первом и втором фото мужчина (более или менее) гонится за тираннозавром; в-третьих, приближаясь к нему с небрежным пренебрежением к безопасности; и на финальном изображении, по-видимому, бегущей трусцой параллельно великому зверю. Примерно через 10-15 попыток на эту тему я обнаружил, что динозавр также «отвлекается».
Возможно, единственные тренировочные данные, к которым DALL-E 2 мог получить доступ, находились в строке «человек сражается с динозавром», из рекламных кадров для старых фильмов, таких как Один миллион лет до нашей эры (1966), и что Джефф Голдблюм знаменитый полет от царя хищников просто выпадает из этого небольшого массива данных.
* Мое преобразование встроенных цитат авторов в гиперссылки.
Впервые опубликовано 4 августа 2022 г.











