Искусственный интеллект
Прямая оптимизация предпочтений: полное руководство

Согласование больших языковых моделей (LLM) с человеческими ценностями и предпочтениями является непростой задачей. Традиционные методы, такие как Обучение с подкреплением на основе отзывов людей (RLHF), проложили путь, интегрируя человеческий вклад для уточнения результатов модели. Однако RLHF может быть сложным и ресурсоемким, требующим значительных вычислительных мощностей и обработки данных. Прямая оптимизация предпочтений (DPO) представляет собой новый и более рационализированный подход, предлагающий эффективную альтернативу традиционным методам. Упрощая процесс оптимизации, DPO не только снижает вычислительную нагрузку, но и повышает способность модели быстро адаптироваться к предпочтениям человека.
В этом руководстве мы подробно рассмотрим DPO, изучим его основы, реализацию и практическое применение.
Необходимость согласования предпочтений
Чтобы понять DPO, важно понять, почему так важно согласовывать LLM с человеческими предпочтениями. Несмотря на свои впечатляющие возможности, LLM, обученные на обширных наборах данных, иногда могут выдавать результаты, которые не соответствуют друг другу, предвзяты или не соответствуют человеческим ценностям. Это несоответствие может проявляться по-разному:
- Создание небезопасного или вредного контента
- Предоставление неточной или вводящей в заблуждение информации
- Проявление предвзятости, присутствующей в данных обучения
Чтобы решить эти проблемы, исследователи разработали методы точной настройки LLM с использованием обратной связи с людьми. Наиболее известным из этих подходов был RLHF.
Понимание RLHF: предшественника DPO
Обучение с подкреплением на основе обратной связи с человеком (RLHF) стало общепринятым методом согласования программ магистратуры права с предпочтениями человека. Давайте разберём процесс RLHF, чтобы понять его сложность:
a) Контролируемая точная настройка (SFT): Процесс начинается с тонкой настройки предварительно обученного LLM на наборе данных высококачественных ответов. Этот шаг помогает модели генерировать более релевантные и последовательные результаты для целевой задачи.
b) Моделирование вознаграждений: отдельная модель вознаграждения обучена предсказывать предпочтения человека. Это включает в себя:
- Генерация пар ответов для заданных подсказок
- Заставить людей оценить, какой ответ они предпочитают
- Обучение модели прогнозированию этих предпочтений
c) Усиление обучения: точно настроенный LLM затем дополнительно оптимизируется с помощью обучения с подкреплением. Модель вознаграждения обеспечивает обратную связь, помогая LLM генерировать ответы, соответствующие предпочтениям человека.
Вот упрощенный псевдокод Python, иллюстрирующий процесс RLHF:
Несмотря на свою эффективность, RLHF имеет несколько недостатков:
- Это требует обучения и поддержки нескольких моделей (SFT, модель вознаграждения и модель, оптимизированная для RL).
- Процесс RL может быть нестабильным и чувствительным к гиперпараметрам.
- Это требует больших вычислительных затрат, так как требует множества прямых и обратных проходов по моделям.
Эти ограничения побудили поиск более простых и эффективных альтернатив, что привело к разработке DPO.
Прямая оптимизация предпочтений: основные концепции

Прямая оптимизация предпочтений https://arxiv.org/abs/2305.18290
На этом изображении сопоставляются два различных подхода к согласованию результатов обучения LLM с человеческими предпочтениями: обучение с подкреплением на основе обратной связи с человеком (RLHF) и прямая оптимизация предпочтений (DPO). RLHF использует модель вознаграждения для управления политикой языковой модели посредством итеративных циклов обратной связи, в то время как DPO напрямую оптимизирует результаты модели для соответствия предпочтительным для человека ответам, используя данные о предпочтениях. Это сравнение подчеркивает сильные стороны и потенциальные возможности каждого метода, давая представление о том, как будущие LLM могут быть обучены лучше соответствовать человеческим ожиданиям.
Ключевые идеи, лежащие в основе DPO:
a) Моделирование неявного вознаграждения: DPO устраняет необходимость в отдельной модели вознаграждения, рассматривая саму языковую модель как неявную функцию вознаграждения.
b) Формулировка на основе политики: вместо оптимизации функции вознаграждения DPO напрямую оптимизирует политику (языковую модель), чтобы максимизировать вероятность предпочтительных ответов.
c) Решение закрытой формы: DPO использует математическое понимание, которое позволяет найти решение оптимальной политики в закрытой форме, избегая необходимости итеративных обновлений RL.
Реализация DPO: практическое руководство по коду
На изображении ниже показан фрагмент кода, реализующий функцию потерь DPO с помощью PyTorch. Эта функция играет ключевую роль в уточнении того, как языковые модели приоритизируют выходные данные на основе предпочтений пользователя. Ниже представлено описание ключевых компонентов:
- Подпись функции:
dpo_lossфункция принимает несколько параметров, включая вероятности журнала политики (pi_logps), вероятности журнала опорной модели (ref_logps), а также индексы, представляющие предпочтительные и непредпочтительные завершения (yw_idxs,yl_idxs). Кроме того,betaПараметр контролирует силу штрафа KL. - Логарифмическое извлечение вероятности: код извлекает журнальные вероятности для предпочтительных и нежелательных завершений как из политики, так и из эталонной модели.
- Расчет коэффициента логарифма: разница между вероятностями журнала для предпочтительных и нежелательных завершений вычисляется как для стратегической, так и для эталонной модели. Это соотношение имеет решающее значение для определения направления и масштаба оптимизации.
- Расчет потерь и вознаграждений: Убыток рассчитывается с использованием
logsigmoidфункция, в то время как вознаграждения определяются путем масштабирования разницы между вероятностями политики и эталонного журнала поbeta.

Функция потери DPO с использованием PyTorch
Давайте углубимся в математику, лежащую в основе DPO, чтобы понять, как он достигает этих целей.
Математика ДПО
DPO — это остроумная переформулировка задачи обучения предпочтениям. Вот пошаговое объяснение:
а) Отправная точка: максимизация вознаграждения с ограничениями KL
Исходную цель RLHF можно выразить так:
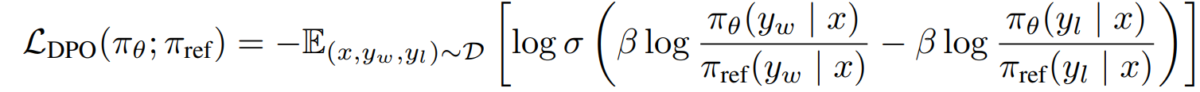
- πθ — это политика (языковая модель), которую мы оптимизируем
- r(x,y) — функция вознаграждения
- πref — эталонная политика (обычно исходная модель SFT).
- β контролирует силу ограничения дивергенции KL.
b) Оптимальная форма политики: Можно показать, что оптимальная политика для достижения этой цели имеет вид:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Где Z(x) — константа нормализации.
c) Двойственность политики вознаграждения: Основная идея DPO заключается в выражении функции вознаграждения в терминах оптимальной политики:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))г) Модель предпочтений. Предполагая, что предпочтения следуют модели Брэдли-Терри, мы можем выразить вероятность предпочтения y1 по сравнению с y2 как:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Где σ — логистическая функция.
e) Цель DPO Подставив нашу двойственность политики вознаграждения и политики в модель предпочтений, мы приходим к цели DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Эту цель можно оптимизировать с помощью стандартных методов градиентного спуска без необходимости использования алгоритмов RL.
Реализация DPO
Теперь, когда мы разобрались с теорией DPO, давайте посмотрим, как реализовать её на практике. Мы будем использовать Питон и PyTorch для этого примера:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Проблемы и будущие направления
Хотя DPO предлагает значительные преимущества по сравнению с традиционными подходами RLHF, все еще существуют проблемы и области для дальнейших исследований:
а) Масштабируемость до более крупных моделей:
Поскольку языковые модели продолжают расти в размерах, эффективное применение DPO к моделям с сотнями миллиардов параметров остается открытой проблемой. Исследователи изучают такие методы, как:
- Эффективные методы тонкой настройки (например, LoRA, настройка префикса)
- Оптимизация распределенного обучения
- Градиентная контрольная точка и обучение смешанной точности
Пример использования LoRA с DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
б) Многозадачность и адаптация к небольшому количеству кадров:
Разработка методов DPO, которые могут эффективно адаптироваться к новым задачам или областям с ограниченными данными о предпочтениях, является активной областью исследований. Изучаемые подходы включают:
- Рамки метаобучения для быстрой адаптации
- Оперативная точная настройка для DPO
- Перенос обучения из моделей общих предпочтений в конкретные области
в) Обработка неоднозначных или противоречивых предпочтений:
Реальные данные о предпочтениях часто содержат неопределенности или противоречия. Повышение устойчивости DPO к таким данным имеет решающее значение. Возможные решения включают:
- Вероятностное моделирование предпочтений
- Активное обучение разрешению двусмысленностей
- Мультиагентная агрегация предпочтений
Пример вероятностного моделирования предпочтений:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
г) Сочетание DPO с другими методами выравнивания:
Интеграция DPO с другими подходами к согласованию может привести к созданию более надежных и функциональных систем:
- Конституционные принципы ИИ для явного удовлетворения ограничений
- Моделирование дебатов и рекурсивного вознаграждения для выявления сложных предпочтений
- Обучение с обратным подкреплением для определения основных функций вознаграждения
Пример сочетания ДПО с конституциональным ИИ:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Практические соображения и лучшие практики
При реализации DPO для реальных приложений примите во внимание следующие советы:
a) Качество данных: качество данных о ваших предпочтениях имеет решающее значение. Убедитесь, что ваш набор данных:
- Охватывает широкий спектр входных данных и желаемого поведения.
- Имеет последовательные и надежные аннотации предпочтений.
- Уравновешивает различные типы предпочтений (например, фактичность, безопасность, стиль)
b) Настройка гиперпараметра: Хотя у DPO меньше гиперпараметров, чем у RLHF, настройка все равно важна:
- β (бета): контролирует компромисс между удовлетворением предпочтений и отклонением от эталонной модели. Начните с ценностей вокруг 0.1-0.5.
- Скорость обучения. Используйте более низкую скорость обучения, чем при стандартной точной настройке, обычно в диапазоне от 1e-6 до 1e-5.
- Размер партии: Большие размеры партии (32-128) часто хорошо работают для обучения предпочтениям.
c) Итеративное уточнение: DPO можно применять итеративно:
- Обучите исходную модель с помощью DPO
- Генерируйте новые ответы, используя обученную модель
- Соберите новые данные о предпочтениях по этим ответам.
- Повторное обучение с использованием расширенного набора данных

Производительность оптимизации прямых предпочтений
На этом изображении показана эффективность моделей LLM, таких как GPT-4, в сравнении с человеческими суждениями при использовании различных методов обучения, включая прямую оптимизацию предпочтений (DPO), контролируемую тонкую настройку (SFT) и оптимизацию проксимальной политики (PPO). Таблица показывает, что результаты GPT-4 всё больше соответствуют человеческим предпочтениям, особенно в задачах реферирования. Уровень согласованности между GPT-4 и рецензентами-людьми демонстрирует способность модели генерировать контент, который резонирует с рецензентами-людьми, почти так же близко, как и контент, созданный человеком.
Тематические исследования и приложения
Чтобы проиллюстрировать эффективность DPO, давайте рассмотрим некоторые реальные приложения и некоторые его варианты:
- Итеративный DPO: этот вариант, разработанный Snorkel (2023), сочетает в себе отбраковочную выборку и DPO, что позволяет более усовершенствовать процесс отбора обучающих данных. Путем повторения нескольких раундов выборки предпочтений модель может лучше обобщать и избегать переобучения к шумным или предвзятым предпочтениям.
- IPO (Итеративная оптимизация предпочтений): Представлено Азаром и др. (2023), IPO добавляет термин регуляризации, чтобы предотвратить переоснащение, что является распространенной проблемой при оптимизации на основе предпочтений. Это расширение позволяет моделям поддерживать баланс между соблюдением предпочтений и сохранением возможностей обобщения.
- КТО (Оптимизация передачи знаний): более поздний вариант от Ethayarajh et al. (2023), KTO вообще отказывается от бинарных предпочтений. Вместо этого он фокусируется на переносе знаний из эталонной модели в политическую модель, оптимизируя ее для более плавного и последовательного соответствия человеческим ценностям.
- Мультимодальный DPO для междоменного обучения Сюй и др. (2024): подход, в котором DPO применяется к различным модальностям — тексту, изображению и аудио — демонстрируя свою универсальность в согласовании моделей с предпочтениями человека в различных типах данных. Это исследование подчеркивает потенциал DPO в создании более комплексных систем искусственного интеллекта, способных решать сложные мультимодальные задачи.












